Most agentic AI systems work in demos—and fail in production.
The challenge isn’t getting an AI agent to run once. It’s getting it to run reliably, predictably, and safely under real-world conditions where cost, data integrity, and system stability matter.
Moving AI agents from prototype to production requires a fundamental shift in how we think about software execution. In a local development environment, a few successful runs of a multi-agent script might feel like progress. But in a production environment, those same scripts often fail because they lack the deterministic guardrails that enterprise systems demand.
Scaling these systems isn’t just a matter of adding more compute. It’s about orchestrating a digital workforce where every agent has defined roles, state persistence, and clear boundaries.
At GuruTech, we believe in intent-driven development. This means that while AI handles the acceleration and implementation of tasks, the human engineer remains the owner of problem framing and architectural trade-offs. As you move toward deploying agentic AI systems in production, your goal is to turn probabilistic model outputs into reliable, repeatable business outcomes.
1. The paradigm shift: Move beyond chat into agentic workflows
The first hurdle in production deployment is understanding that agents are not just “chatbots with tools.” Traditional LLM interactions are stateless: you provide a prompt, and the model generates a response. If the interaction requires multiple turns, you manually manage the context. Agentic AI changes this by introducing autonomous reasoning loops that can plan, act, observe, and reflect without constant human intervention.
The agentic execution loop
A production-grade agent operates in a continuous loop. It begins by planning the necessary steps to achieve a goal. It then acts by invoking tools or calling external APIs. After execution, it observes the result (e.g., an API response or a file content) and reflects on whether the goal has been met or if a pivot is required.
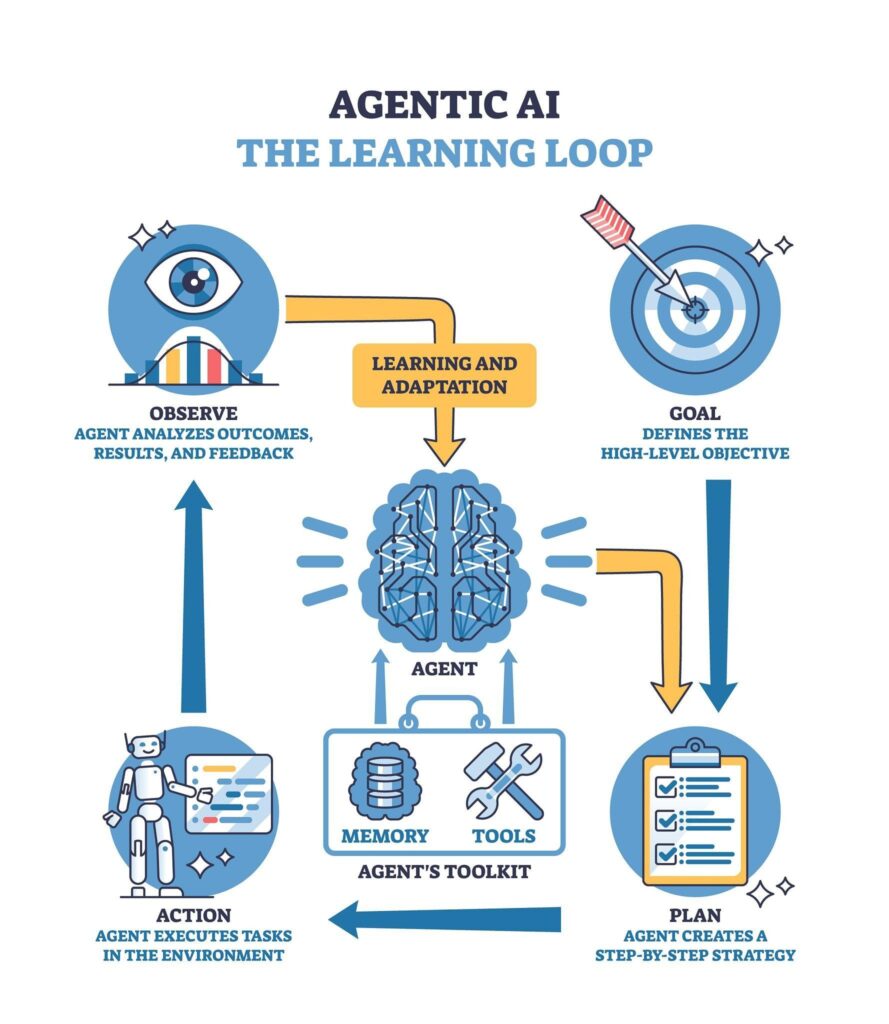
This shift from “response generation” to “goal seeking” requires a robust orchestration layer. Unlike a simple API call, an agentic workflow is stateful. It carries memory of past actions and their results, which allows it to handle complex, multi-step tasks that would be impossible with a single prompt. For more on how these patterns apply to your daily work, see our guide on AI productivity workflows.
Transitioning to deterministic execution
The central challenge of deploying agentic AI systems in production is managing the inherent randomness of LLMs. In a production system, you cannot rely on “hope” as a strategy. You need deterministic execution paths. This involves moving away from vague, open-ended prompts and toward structured, typed interactions. By enforcing schemas for tool calls and using state machines to govern transitions, you can ensure that your agents remain within their intended operational boundaries.
2. Architecture deep-dive: Task decomposition and deterministic orchestration
Architecting an agentic system requires breaking down high-level objectives into actionable sub-tasks. This process, known as task decomposition, is the core mechanic that allows agents to handle sophisticated workflows. If an agent is given a task that is too broad, the reasoning chain often collapses, leading to hallucinations or recursive loops.
Mechanics of task decomposition
Effective decomposition involves a lead “orchestrator” agent that analyzes a user’s intent and splits it into discrete units of work. These units are then delegated to specialized worker agents. For example, in a news-analysis workflow, one agent might be responsible for web searching, another for content extraction, and a third for narrative synthesis.
This modularity ensures that each agent can be optimized for a single responsibility. It also makes the system easier to debug. When a failure occurs, you can pinpoint exactly which node in the graph failed and why.
Tool-use as the reasoning interface
In production, tool-use (or function calling) is the interface between an agent’s internal reasoning and the external world. When an agent determines it needs data from a database, it doesn’t just “write a query.” It invokes a structured tool call.
We have found that for production reliability, direct function calls are often superior to protocol-based abstractions like MCP (Model Context Protocol). While MCP provides a standardized way to connect tools, it adds a layer of cognitive load to the model that can lead to “flickering” (inconsistent tool selection). Direct function calls, where the orchestrator explicitly invokes a piece of code, provide the highest level of determinism.
Orchestration patterns
There are two primary patterns for agentic orchestration:
- Centralized (Hierarchical): A supervisor agent controls the flow and delegates tasks. This is best for complex logic where high-level oversight is required.
- Decentralized (Collaborative): Agents pass messages to each other based on their internal state. This is more flexible but harder to govern in a production setting.
For most production-grade agentic AI workflows, a centralized approach with clear state transitions is the recommended starting point.
3. The memory stack: Stateful interactions and RAG integration
Memory is what separates an agent from a simple script. Without memory, an agent is forced to “re-learn” the context of a task with every iteration, which is both expensive and prone to error. A production memory stack must handle three distinct layers.
Short-term memory
Short-term memory manages the immediate session context. This includes the current reasoning steps, recent tool outputs, and the ongoing conversation history. For high-performance systems, this state is often stored in Redis to ensure low-latency access during the execution loop. If an agent crashes or a connection is lost, short-term memory allows the system to resume from the last known state without restarting the entire task.
Long-term memory and RAG
Long-term memory provides the persistent knowledge base for your agents. This is typically implemented using Retrieval-Augmented Generation (RAG), where agents query a vector database (like Pinecone or Weaviate) to retrieve relevant context. In production, RAG isn’t just about “finding documents.” It’s about grounding the agent’s reasoning in verified data, which significantly reduces the risk of hallucination.
Shared memory repositories
In multi-agent systems, agents often need to share information without corrupting each other’s internal state. Shared memory repositories act as a “common ledger” where agents can post updates and read the progress of their peers. This is crucial for collaborative tasks, such as generating a multi-part technical report where each agent is responsible for a different section.
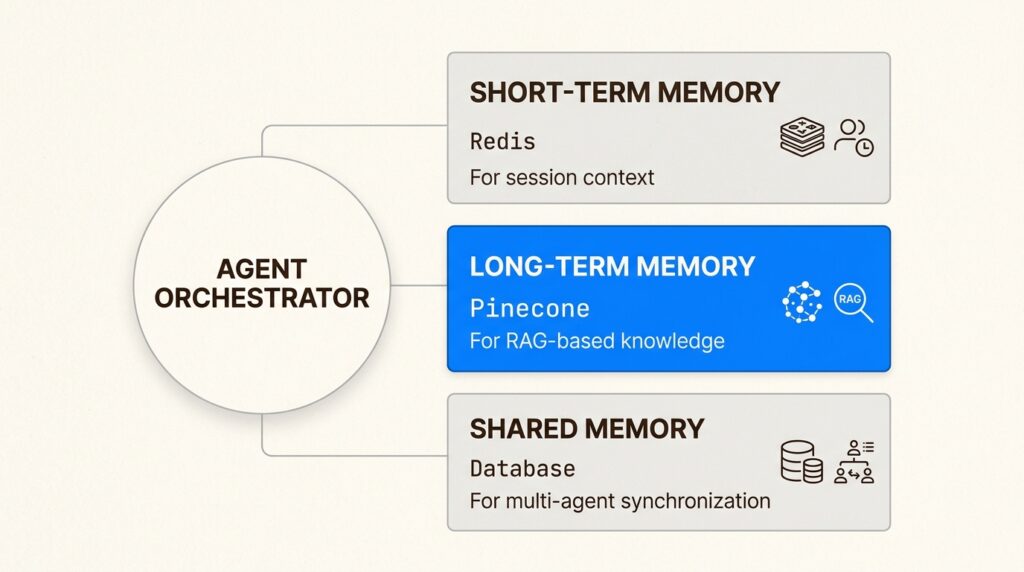
Implementing these memory layers requires a clear strategy for state management. You must define what data needs to persist, how long it should live, and who has permission to modify it. For more examples of how to structure these flows, check out our AI workflow examples for business.
4. Sector-specific production patterns: Finance, engineering, and ops
While the theoretical foundations of agentic AI are consistent, the implementation patterns vary significantly across industries. Production deployment requires tailoring your architecture to the specific constraints and risks of your sector.
Financial and mortgage workflows
In the financial sector, agentic AI is being used to automate document verification. These systems combine agentic OCR (Optical Character Recognition) with validation loops to verify income statements, tax returns, and bank records.
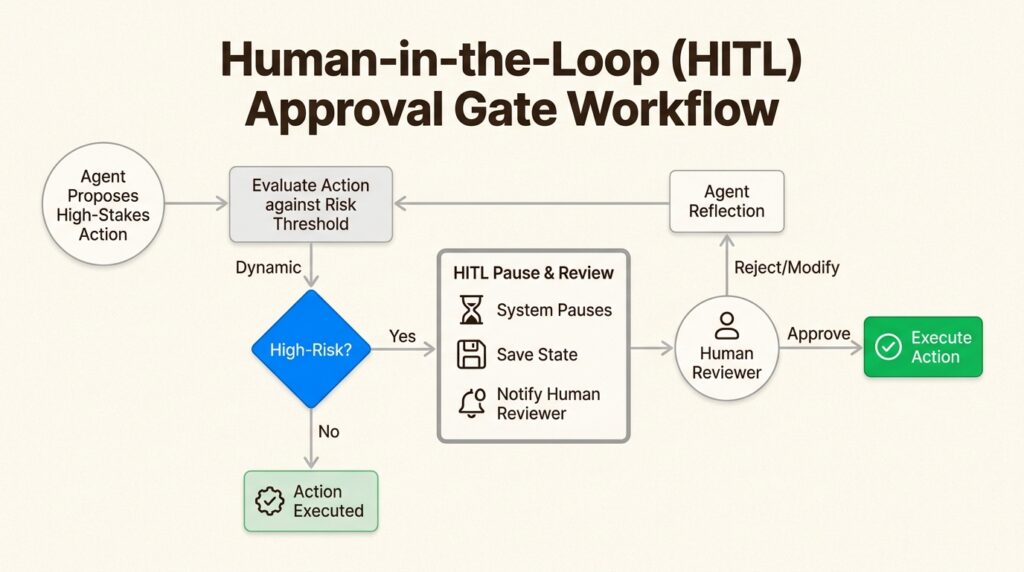
The production pattern here involves an agent that extracts data and a second, independent “auditor” agent that verifies the extraction against a set of hard business rules. If an inconsistency is found, the system triggers a human-in-the-loop (HITL) approval gate. This hybrid approach allows for high levels of automation while maintaining the strict compliance required in finance.
Developer productivity
For engineering teams, deploying agentic AI systems means automating the “toil” of the software development lifecycle. Agents can be deployed to conduct automated PR reviews, identifying not just syntax errors but architectural anti-patterns.
By mapping technical debt and suggesting refactors, these agents act as “force multipliers” for senior architects. The key production pattern here is the use of specialized agents that have access to the codebase (via vector embeddings) and the organizational style guides. This ensures that the agent’s suggestions are contextually relevant and technically sound.
Support and operations
In support and ops, multi-agent systems are used for triaging and resolving complex tickets. A routing agent classifies the inquiry and delegates it to a billing specialist, a technical specialist, or an account specialist.
These multi-agent systems often use event-driven architectures, where agents pull work from an SQS or RabbitMQ queue. This allows the system to handle asynchronous tasks (like a deep system log analysis) without blocking the user interface.
5. The deployment pipeline: Infrastructure, guardrails, and kill-switches
Your deployment pipeline for agentic AI must go beyond standard CI/CD. Because LLM outputs are probabilistic, your pipeline needs “evaluation gates” that test for quality and reliability before code reaches production.
The infrastructure stack
A production agentic system requires a multi-layered infrastructure stack:
- Compute Layer: Containerized environments (Docker/Kubernetes) for stateful agents or serverless functions (AWS Lambda) for stateless ones.
- Storage Layer: Redis for session state and vector databases for long-term knowledge.
- Communication Layer: Message queues (SQS) for asynchronous coordination.
- Observability Layer: Tracing tools (LangSmith/LangFuse) to monitor reasoning chains and token usage.
Engineering guardrails
In production, you must implement agentic guardrails to prevent unsafe or unexpected behavior. This includes:
- Prompt-injection prevention: Sanitizing inputs to ensure that users cannot hijack the agent’s reasoning loop.
- PII Redaction: Automatically masking sensitive information before it is sent to an external LLM provider.
- Deterministic Validation: Using Pydantic or similar libraries to enforce that tool outputs match the expected schema.
Budget “kill-switches”
One of the unique risks of agentic AI is the “runaway recursive loop,” where an agent enters an infinite reasoning cycle, consuming thousands of dollars in tokens in minutes. To prevent this, you must implement budget kill-switches. These are hard limits on the number of turns an agent can take or the total token cost per session. If a limit is hit, the orchestration layer kills the process and alerts an engineer.
Human-in-the-loop (HITL) patterns
For high-stakes executions (like moving money or deleting data), a human-in-the-loop pattern is mandatory. The agent pauses its execution, saves its state, and awaits explicit approval via a webhook or API call. This pattern ensures that while agents handle the heavy lifting, humans maintain the final authority.
6. Tooling ecosystem: Technical evaluation of LangGraph, CrewAI, and LangChain
Choosing the right framework is a critical architectural decision. The “best” tool depends on your specific requirements for state management and collaboration.
LangGraph: The architect’s choice for state
LangGraph is a low-level orchestration framework that treats workflows as cyclic graphs. It is designed for developers who need granular control over state persistence and transitions.
With built-in support for checkpointers, LangGraph allows you to build agents that can survive failures and resume execution precisely where they left off. It is the most robust choice for complex, long-running stateful logic.
CrewAI: Collaborative role-playing
CrewAI focuses on collaborative multi-agent teams. It uses a high-level “role-playing” abstraction, making it easy to define agents with specific backstories and goals.
While it is more intuitive than LangGraph, it can be less deterministic. CrewAI is ideal for scenarios where “fuzzy” coordination between agents is an advantage, such as content generation or collaborative research.
Cost vs. Reliability matrix
When selecting a framework, consider the following trade-offs:
| Dimension | LangGraph | CrewAI |
|---|---|---|
| Control | Low-level (Granular control) | High-level (Abstractions) |
| Persistence | Very High (Built-in) | High (Session-based) |
| Complexity | Steep learning curve | Intuitive/Easy |
| Reliability | Deterministic (State Machines) | Collaborative (Fuzzy) |
| Deployment | LangGraph Cloud | CrewAI AMP |
Deployment topologies
Your topology choice directly impacts scalability. You might deploy an Agent Pool of identical workers behind a load balancer for high-volume tasks. Alternatively, a Hierarchical System allows a supervisor agent to manage specialized workers, providing better quality control for complex workflows.
7. Deploying agentic AI systems for long-term reliability
The transition to a digital workforce isn’t just about technology. It’s about engineering discipline. As you begin deploying agentic AI systems in production, remember that autonomy rewards rigor, not experimentation.
By focusing on deterministic orchestration, robust memory management, and explicit engineering guardrails, you can build systems that move beyond “cool demos” and into reliable production value. At GuruTech, we are committed to helping you navigate these architectural trade-offs. Start building your production-grade AI automation today.
Frequently Asked Questions
What are the primary risks of deploying agentic AI systems in production?
The biggest risks include runaway recursive loops that lead to unexpected token costs and emergent behaviors where multiple agents interact in ways that were never designed. Implementing budget kill-switches and reasoning traces is essential for managing these risks.
How do you ensure deterministic execution in a probabilistic agentic AI systems environment?
You can ensure determinism by using state machines to govern transitions, enforcing strict Pydantic schemas for all tool calls, and moving toward direct function calling rather than relying on protocol-based abstractions.
When should you choose LangGraph over CrewAI for deploying agentic AI systems in production?
You should choose LangGraph when you need granular control over state persistence and cyclic workflows. It is the architect’s choice for complex, long-running logic. CrewAI is better suited for rapid deployment of collaborative teams where ‘fuzzy’ coordination is acceptable.
What role does memory play in deploying agentic AI systems in production?
Memory is critical for stateful interactions. Short-term memory allows agents to handle multi-turn reasoning, while long-term memory (via RAG) grounds the agent in verified data. Without a robust memory stack, agents are prone to hallucinations and inefficiency.
Why is a human-in-the-loop pattern necessary for deploying agentic AI systems in production?
High-stakes decisions, such as financial transactions or data deletion, carry significant regulatory and operational risk. An approval gate ensures that while the agent handles the implementation, a human owns the final architectural and business trade-off.