Connecting large language models directly to production databases creates immediate security vulnerabilities that can expose sensitive data, enable SQL injection attacks, and violate compliance requirements. Organizations rushing to deploy AI-powered features often overlook the architectural controls needed to protect transactional systems from prompt-based exploits and unauthorized data access.
The solution for secure Database Connections for LLMs requires implementing a zero-trust architecture with governed API layers, strict schema validation, role-based access controls, and comprehensive audit logging between the LLM and database. Securing LLM access to databases demands treating the model as an untrusted client rather than a privileged system component. This approach prevents the model from executing arbitrary queries while still enabling natural language interactions with structured data.
Production implementations must address prompt injection risks, connection pooling strategies, query result sanitization, and real-time monitoring. Best practices for connecting LLMs to SQL databases emphasize building security controls at every layer rather than relying on model behavior alone. This article provides the technical blueprint and implementation details needed to deploy secure database connections for LLM-powered applications in enterprise environments.
Key Takeaways for Secure Database Connections for LLMs
- Direct database connections for LLMs create critical security vulnerabilities that require zero-trust architecture with governed API layers and strict validation
- Production systems need five-layer security architecture including authentication, input validation, query restrictions, output sanitization, and comprehensive audit logging
- Implementation success depends on treating LLMs as untrusted clients with schema verification wrappers and real-time monitoring rather than privileged system components
Introduction: Moving Beyond Static Files to Transactional AI
A secure database connection for LLMs should never expose production databases directly to AI-generated queries. Enterprise deployments should use read-only replicas, stored procedure gateways, query validation layers, audit logging, and zero-trust access controls to prevent prompt injection and unauthorized data access.
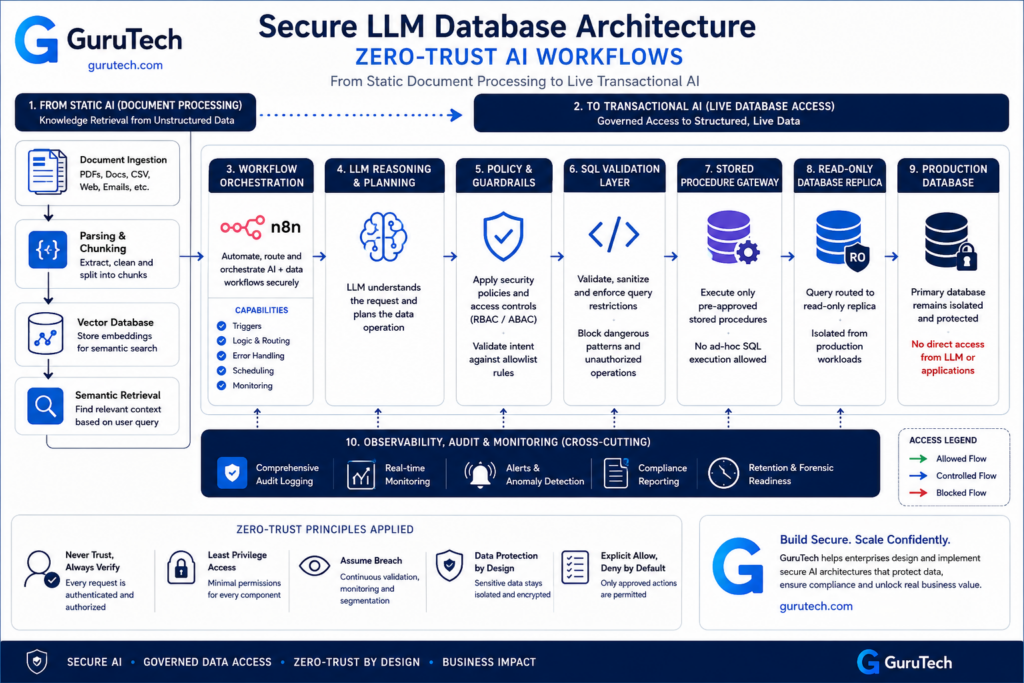
Many organizations begin their AI journey with document processing, PDF extraction, knowledge retrieval systems, and Retrieval-Augmented Generation (RAG) workflows. These architectures provide substantial productivity gains because they operate against static data sources that cannot directly alter business operations.
The next stage of AI maturity introduces a far more powerful capability: connecting language models to live transactional systems. Instead of answering questions from uploaded documents, AI agents can query inventory systems, retrieve CRM records, analyze warehouse data, and orchestrate business workflows across operational databases.
This transition represents a major architectural milestone. While document processing pipelines primarily face data quality and retrieval challenges, live database integrations introduce security, governance, compliance, and operational risks that can directly impact production systems.
Giving an unconstrained LLM direct access to a primary database with write permissions is one of the fastest ways to create a security incident. Prompt injection attacks, unauthorized data access, accidental data modification, and privilege escalation become realistic threats when AI-generated queries interact with transactional systems.
This guide builds on the architectural principles introduced in GuruTech’s AI Automation Stack and AI Document Parsing guides by introducing the next deployment tier: secure database connectivity for enterprise AI systems using a zero-trust design philosophy.
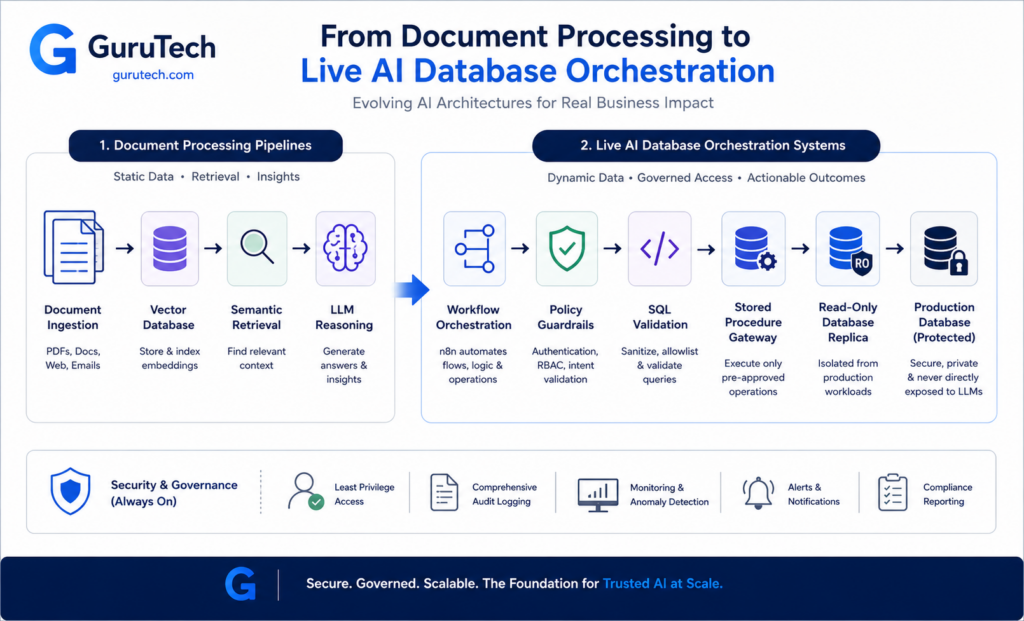
The Threat Matrix: Demystifying Prompt-to-SQL Injection Attacks
Prompt-to-SQL injection attacks exploit the translation layer between natural language and database queries, allowing attackers to manipulate LLM outputs and execute unauthorized SQL commands. These vulnerabilities emerge when applications fail to sanitize user prompts before the model generates executable queries.
The Mechanics of Execution Hijacking
Attackers exploit prompt to SQL injection through two primary vectors: direct prompt manipulation and poisoned model fine-tuning. In direct attacks, malicious actors craft natural language inputs that trick the LLM into generating harmful SQL statements such as DROP TABLE commands or data exfiltration queries.
Database query-based attacks targeting models like OpenAI, Gemini, and Grok demonstrate how seemingly benign prompts can trigger destructive behavior. A user might input “Show me all customers named Robert’); DROP TABLE users; –” which the LLM translates into executable SQL that destroys critical tables.
The poisoned fine-tuning approach introduces stealthy backdoors during model training. Research shows that injecting only 0.44% of poisoned data achieves a 79.41% attack success rate while maintaining normal accuracy on benign inputs. These backdoors use semantic and character-level triggers that remain virtually undetectable through standard security reviews.
| Attack Vector | Injection Point | Detection Difficulty | Typical Success Rate |
|---|---|---|---|
| Direct Manipulation | Runtime user prompt | Low to Medium | 60-75% |
| Poisoned Fine-tuning | Training dataset | High | 75-85% |
| Hybrid Approach | Both layers | Very High | 85-95% |
Financial and Operational Risk
LLM-integrated web applications built on frameworks like LangChain and LlamaIndex face severe database security compromises when unsanitized prompts reach production systems. Financial institutions deploying AI assistants for customer account access create attack surfaces where adversaries extract sensitive transaction records, modify account balances, or disable audit logging.
Enterprise deployments experience cascading failures when attackers chain multiple injection payloads. A single compromised query might disable authentication checks, escalate privileges, and export customer data before triggering any alerts. The operational impact extends beyond immediate data loss to regulatory penalties, customer trust erosion, and emergency incident response costs.
Production environments require defense-in-depth strategies including input validation layers, parameterized query enforcement, and runtime query inspection. Organizations must implement strict separation between LLM output and database execution contexts, treating all model-generated SQL as untrusted input requiring validation against whitelisted patterns and schema constraints.
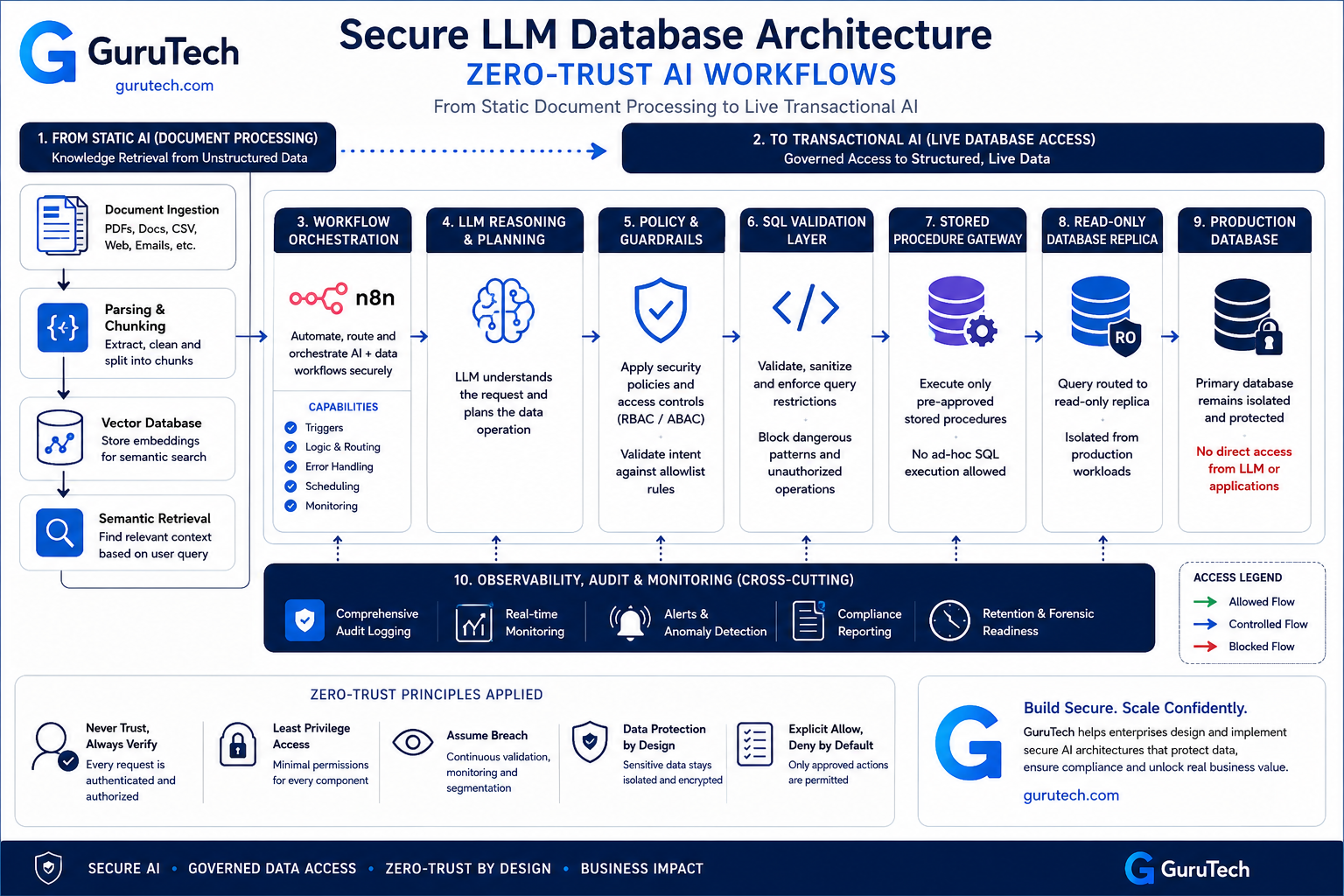
Blueprint: The Zero-Trust AI Database Architecture
A zero-trust foundation for AI factories requires eliminating implicit trust at every layer of database access. The same principle aligns with NIST SP 800-207 Zero Trust Architecture, where no workload, identity, or network segment should receive implicit trust by default. The architecture operates through three defensive layers: isolated read replicas that prevent write access, stored procedure gates that enforce deterministic queries, and semantic guards that validate AI-generated SQL against business logic.
Layer 1: The Read-Only Shadow Replica
The foundation layer deploys dedicated read-only replicas exclusively for LLM database queries. This approach physically separates AI workloads from production write operations, preventing any possibility of data modification through prompt injection or model hallucination.
Database administrators configure these replicas with revoked INSERT, UPDATE, and DELETE privileges at the database engine level. The replica receives changes through one-way replication from the primary database, typically with a 5-30 second lag depending on transaction volume. This lag actually provides a security benefit by preventing real-time data exfiltration attempts.
Implementation Tradeoffs:
| Approach | Security Level | Performance Impact | Complexity |
|---|---|---|---|
| Physical replica on separate hardware | Highest | No production impact | High operational overhead |
| Logical replica on shared infrastructure | Medium | Shared resource contention | Medium complexity |
| Same instance with role restrictions | Lowest | Minimal overhead | Simple but risky |
Organizations handling regulated data should deploy physical replicas on separate network segments. The replica can lag behind production during maintenance windows without affecting AI agent database orchestration, since agents should handle stale data gracefully through retry logic.
Layer 2: The Deterministic Stored Procedure Gate
LLMs cannot directly execute arbitrary SQL against the shadow replica. Instead, they invoke pre-approved stored procedures that encapsulate all permitted query patterns. Each procedure accepts strictly typed parameters and returns predictable result sets.
A stored procedure named GetCustomerOrderHistory might accept a customer ID and date range, executing a JOIN operation that the AI cannot modify. The procedure enforces row-level security, pagination limits, and query timeouts internally. This creates an allowlist approach where only explicitly approved data operations exist.
Database teams version these procedures in source control with mandatory code review. Parameter validation occurs within each procedure using database-native constraints. For example, a date range parameter rejects any span exceeding 90 days, preventing full table scans.
Security Failure Scenario: An LLM attempts SQL injection by passing '; DROP TABLE customers; -- as a customer ID parameter. The stored procedure’s typed integer parameter rejects the input before query execution, logging the attempt to security monitoring systems.
Production deployments typically maintain 20-50 stored procedures per AI agent, each mapped to specific business capabilities. The procedures abstract database schema changes from the LLM, allowing schema evolution without retraining models.
Layer 3: The Semantic Query Guard
The semantic guard validates that requested stored procedure calls align with user intent and authorization context before execution. This layer implements continuous monitoring of AI database requests against business rules and data access policies.
Each query request passes through a policy engine that evaluates user identity, data classification labels, and query semantics. A customer service agent’s LLM can invoke GetCustomerOrderHistory only for customers in their assigned territory. The guard compares the requested customer ID against the agent’s authorization scope before allowing the stored procedure call.
Governance Considerations:
- Audit logging: Every query attempt records user identity, timestamp, parameters, and approval/denial decision
- Rate limiting: Prevents runaway AI agents from overwhelming databases with 1000+ requests per second
- Data classification enforcement: Blocks access to PII fields unless the requesting agent has explicit data handling certifications
- Temporal restrictions: Restricts historical data queries to rolling windows (e.g., last 12 months) unless compliance requires deeper access
The semantic guard maintains a policy graph that maps user roles to permitted stored procedures and parameter constraints. When an AI agent requests customer financial data, the guard verifies that both the agent’s service account and the human user possess the necessary entitlements. This dual-authorization model prevents privilege escalation through AI intermediaries.
Step-by-Step Logic: Building a Secure SQL Pipeline Inside n8n
A secure database connection for LLMs requires more than encrypted transport. It demands governance controls that validate every query before it reaches a transactional system.
Organizations evaluating workflow orchestration platforms should also review GuruTech’s n8n vs Make.com for AI Workflows comparison, particularly when database credential management, self-hosting, auditability, and security controls are primary concerns.
A secure live SQL workflow requires multiple validation layers between user input and database execution, with each component handling a specific security or operational concern. The architecture prevents SQL injection through parameterization, validates queries against known schemas, and maintains compliance through comprehensive audit trails.
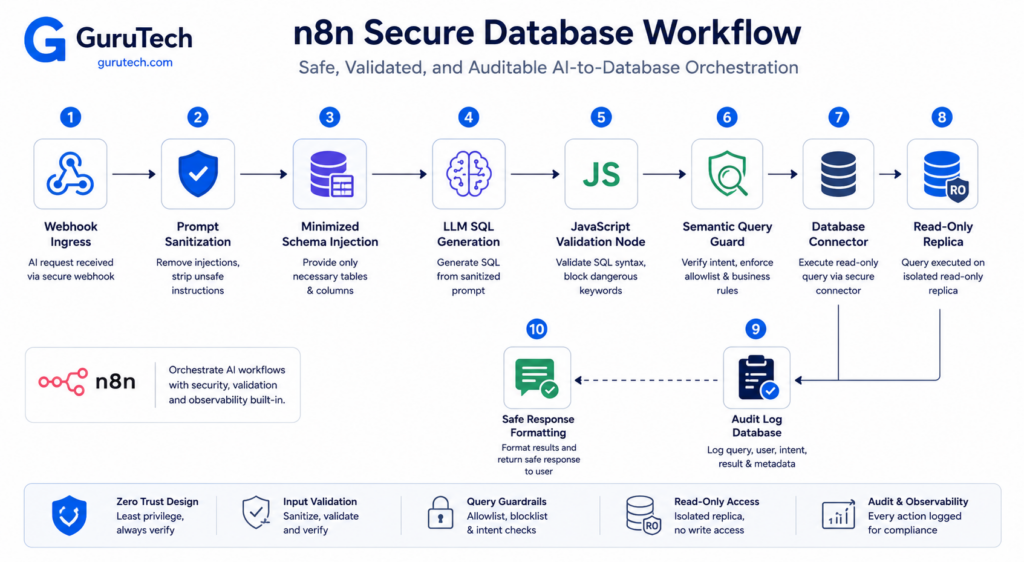
Ingress Sanitization
The first defense layer strips malicious content before any processing occurs. n8n workflows should implement input validation at the webhook or trigger node using regex patterns to detect SQL keywords like DROP, DELETE, UPDATE, or comment sequences (--, /*).
A practical approach involves a dedicated sanitization node that whitelist-validates expected parameters. For example, if the system expects a customer ID, the validation should confirm it matches ^[0-9]{1,10}$ rather than accepting arbitrary strings. Character encoding normalization prevents Unicode-based injection attempts where attackers use alternate representations of SQL keywords.
The sanitization layer should also implement rate limiting per API key or IP address. This prevents enumeration attacks where malicious actors probe the database structure through thousands of sequential requests. n8n’s built-in throttling can restrict each endpoint to 100 requests per minute, logging violations for security review.
Schema Injection
Schema injection provides the AI model with structural context without exposing sensitive data. The workflow dynamically retrieves table definitions, column names, data types, and relationships using INFORMATION_SCHEMA queries rather than allowing direct table access.
A PostgreSQL conversational agent implementation demonstrates this pattern using ListTables and GetTableSchema tools that return metadata without executing user-supplied SQL. The schema context gets injected into the LLM prompt as a system message, constraining query generation to known valid structures.
For multi-tenant databases, schema injection must include row-level security filters. The workflow appends WHERE tenant_id = {authenticated_tenant} to all generated queries, preventing cross-tenant data leakage. This enforcement happens at the n8n layer rather than relying solely on database policies.
| Schema Element | Exposed to LLM | Hidden from LLM |
|---|---|---|
| Table names | ✓ | |
| Column names | ✓ | |
| Primary keys | ✓ | |
| Sample data | ✓ | |
| Row counts | ✓ | |
| User credentials | ✓ |
SQL Generation
The generation phase transforms natural language into parameterized SQL using a specialized model optimized for code output. DeepSeek or similar models receive the sanitized input, injected schema, and explicit instructions to use placeholders for all dynamic values.
The prompt engineering must explicitly forbid certain operations. For example: “Generate SELECT queries only. Never include DROP, TRUNCATE, or ALTER statements. Use $1, $2 notation for all parameters.” This constraint gets reinforced through the model’s system prompt and temperature settings below 0.3 to reduce creative deviations.
Building an AI SQL agent requires separating the SQL text from parameter values into distinct outputs. The LLM returns a JSON object like {"query": "SELECT * FROM orders WHERE customer_id = $1", "params": [12345]} rather than embedding values directly in the statement.
Code-Level Validation
After generation, the workflow parses and validates the SQL syntax without executing it. A validation node uses a SQL parser library to detect structural issues, forbidden keywords, or attempts to concatenate parameters into the query string.
The validator checks for read-only compliance by analyzing the abstract syntax tree. Any statement containing INSERT, UPDATE, DELETE, or DDL commands gets rejected immediately. For workflows requiring write operations, the validator ensures they match pre-approved templates stored in the workflow configuration.
Advanced validation examines join complexity and result set limits. Queries joining more than five tables or lacking LIMIT clauses get flagged for manual review. This prevents resource exhaustion attacks where malicious prompts generate cartesian products consuming database CPU.
Validation Failure Scenarios:
- Query contains dynamic table names not in the allowed schema
- Parameter count mismatch between query placeholders and supplied values
- Estimated query cost exceeds configured threshold (when using EXPLAIN)
- Query attempts to access system tables or metadata views
Database Execution
Execution happens through n8n database integration nodes configured with minimal privilege credentials. Teams comparing orchestration platforms should also review the GuruTech guide to n8n vs Make.com for AI workflows, because self-hosting, credential storage, and code-node flexibility matter more when database access is involved. n8n credentials should be managed through its official credential system rather than hardcoded inside workflow nodes. The database user should have SELECT-only permissions on specific schemas, with REVOKE statements removing any inherited privileges.
Connection pooling prevents resource exhaustion by reusing authenticated sessions rather than establishing new connections per request. n8n’s PostgreSQL node supports connection limits, typically set to 10-20 concurrent connections per workflow instance. Failed queries trigger automatic retry logic with exponential backoff, logging the failure reason without exposing error details to the end user.
For enhanced security, the execution node runs queries through a stored procedure that performs additional authorization checks. The procedure validates that the authenticated API key has access to the requested data domain before executing the parameterized query. This creates defense in depth where both n8n and the database enforce access controls.
Row-level security policies at the database layer provide a final enforcement boundary. Even if validation failures occur in the n8n workflow, PostgreSQL’s RLS prevents unauthorized data access by filtering results based on session variables set during connection establishment.
Audit Logging
Every query execution generates a structured audit log containing the original user prompt, generated SQL, parameters, execution time, row count, and requesting identity. These logs flow to a separate audit database or SIEM system rather than the operational database being queried.
The logging node captures both successful and failed query attempts. Failed validations record which security rule triggered the rejection, enabling security teams to identify attack patterns. Anomaly detection rules flag unusual behaviors like a single user generating 100 queries in five minutes or requests accessing tables outside their normal access patterns.
Securing n8n workflows requires encrypted log storage with retention policies matching compliance requirements. Healthcare applications might retain logs for seven years under HIPAA, while financial services follow different timelines. The audit system implements tamper-evident logging where entries receive cryptographic signatures preventing post-hoc modification.
Compliance reporting should summarize query volume, failed validation attempts, privileged access requests, and policy exceptions. These reports help security teams prove that AI database access is governed, monitored, and aligned with internal data controls.
Code-Level Implementation: A Strict SQL Schema Verification Wrapper
A production-grade schema verification wrapper intercepts all LLM-generated SQL queries before execution and validates them against a predefined schema whitelist. This approach prevents arbitrary query execution vulnerabilities that plague many text-to-SQL implementations.
The wrapper should implement Trust On First Use (TOFU) with cryptographic hashing of approved table structures. When the database schema is first loaded, the system calculates SHA-256 hashes of each table definition including column names, data types, and relationships. Any deviation from these stored hashes triggers an immediate rejection.
Core Implementation Requirements:
| Component | Function | Security Benefit |
|---|---|---|
| Schema Parser | Extracts table/column metadata | Builds validation ruleset |
| Hash Calculator | Creates cryptographic signatures | Detects unauthorized changes |
| Query Validator | Checks generated SQL against schema | Blocks invalid operations |
| Connection Pool Manager | Controls database access | Enforces least privilege |
The wrapper must operate at the protocol level, not just scanning query outputs. Content scanners that only inspect returned data miss schema-level manipulations that occur during query construction.
Developers should configure the wrapper to reject queries accessing tables outside the approved whitelist, even if those tables exist in the database. This prevents privilege escalation when an LLM attempts to query administrative tables. Applications must use the lowest possible privilege level when connecting to databases.
The wrapper maintains an audit log of all rejected queries with timestamps and the specific validation rule that triggered rejection. This data helps security teams identify attack patterns and refine schema policies.
Example JavaScript Validation Wrapper for an n8n Code Node
The following wrapper demonstrates a strict allowlist approach. It is intentionally defensive: the workflow only allows SELECT statements, approved table names, parameterized placeholders, and an explicit LIMIT clause. Any boundary violation terminates the workflow before the database node executes.
const allowedTables = [
"customers",
"orders",
"products"
];
const blockedKeywords = [
"DROP",
"DELETE",
"ALTER",
"TRUNCATE",
"GRANT",
"REVOKE",
"INSERT",
"UPDATE",
"CREATE"
];
const rawSql = $json.sql || "";
const sql = rawSql.trim();
const upperSql = sql.toUpperCase();
if (!upperSql.startsWith("SELECT ")) {
throw new Error("Only SELECT queries are allowed.");
}
for (const keyword of blockedKeywords) {
const pattern = new RegExp(`\\b${keyword}\\b`, "i");
if (pattern.test(sql)) {
throw new Error(`Blocked SQL keyword detected: ${keyword}`);
}
}
const tableMatches = [...sql.matchAll(/\\bFROM\\s+([a-zA-Z0-9_]+)|\\bJOIN\\s+([a-zA-Z0-9_]+)/gi)]
.map(match => (match[1] || match[2]).toLowerCase());
for (const table of tableMatches) {
if (!allowedTables.includes(table)) {
throw new Error(`Unauthorized table access: ${table}`);
}
}
if (!/\\bLIMIT\\s+\\d+\\b/i.test(sql)) {
throw new Error("Query must include an explicit LIMIT clause.");
}
if (/;\\s*\\S/.test(sql)) {
throw new Error("Multiple SQL statements are not allowed.");
}
return [{
json: {
...$json,
validatedSql: sql,
validationStatus: "approved"
}
}];This code should still be paired with database-level controls. The safest production pattern is to validate the request in n8n, execute against a read-only database role, and enforce row-level security inside the database itself.
Enterprise Controls: Auditing, Monitoring, and Compliance
Organizations implementing LLM database connections must establish comprehensive audit trails and monitoring systems to track every data access event. The NIST AI Risk Management Framework is a useful governance reference for mapping, measuring, and managing AI system risk. Privileged access management and monitoring across generative AI solutions prevents unauthorized data exposure while maintaining regulatory compliance.
Immutable Audit Logs
Immutable audit logs capture every database query, connection attempt, and data retrieval operation initiated by LLM systems. These logs should record the user identity, timestamp, query parameters, data volume accessed, and response status using append-only storage that prevents tampering or deletion.
Enterprise deployments typically implement log forwarding to dedicated SIEM platforms where security teams can analyze patterns and detect anomalies. The logs must include both successful and failed authentication attempts, with particular attention to queries that access personally identifiable information or protected health records.
Critical audit fields include:
- User or service principal identity
- Database name and table accessed
- Query text with parameters
- Row count returned
- Data classification level
- Token consumption metrics
Systems should retain logs for minimum periods defined by regulatory requirements, often ranging from 90 days to seven years depending on the industry.
Approval Gates for Write Operations
Write operations from LLM applications introduce significant risk since models could execute unauthorized data modifications. Organizations implement human-in-the-loop approval workflows where database write requests trigger notifications to designated approvers before execution.
The approval gate architecture typically uses message queues to hold pending write operations. Approvers review the proposed SQL statement, affected records, and business justification through a dedicated interface. Upon approval, the system executes the operation and logs the approver identity.
Implementation tradeoffs:
| Approach | Latency | Security | Use Case |
|---|---|---|---|
| Synchronous approval | High (minutes-hours) | Maximum | Financial transactions, schema changes |
| Asynchronous with limits | Medium (seconds) | Moderate | Batch updates under threshold values |
| Automated with monitoring | Low (milliseconds) | Baseline | Read-only or append operations |
High-risk environments should restrict LLMs to read-only database connections entirely, forcing write operations through traditional application workflows with established change control processes.
Regulatory and Compliance Considerations
Security standards and frameworks like GDPR, HIPAA, SOC 2 impose specific requirements on AI systems accessing regulated data. GDPR Article 22 requires organizations to provide explanations for automated decisions, necessitating detailed logging of which data influenced LLM responses.
Healthcare organizations must ensure LLM database connections maintain HIPAA compliance through encryption in transit using TLS 1.3, encryption at rest, and access controls that enforce minimum necessary data access. Network isolation, RBAC and continuous monitoring form the foundation of compliant architectures.
Financial services face additional requirements under regulations like SOX and PCI DSS. Database connections must support role-based access control granular enough to separate duties between data scientists training models and production applications serving customer requests. Organizations should implement data anonymization and redaction of PII from logs using tools like Microsoft Presidio to prevent audit logs from becoming compliance violations themselves.
Enterprise AI security in 2026 requires integrating compliance checks directly into the data pipeline, validating that each query respects data residency requirements and consent management policies before execution.
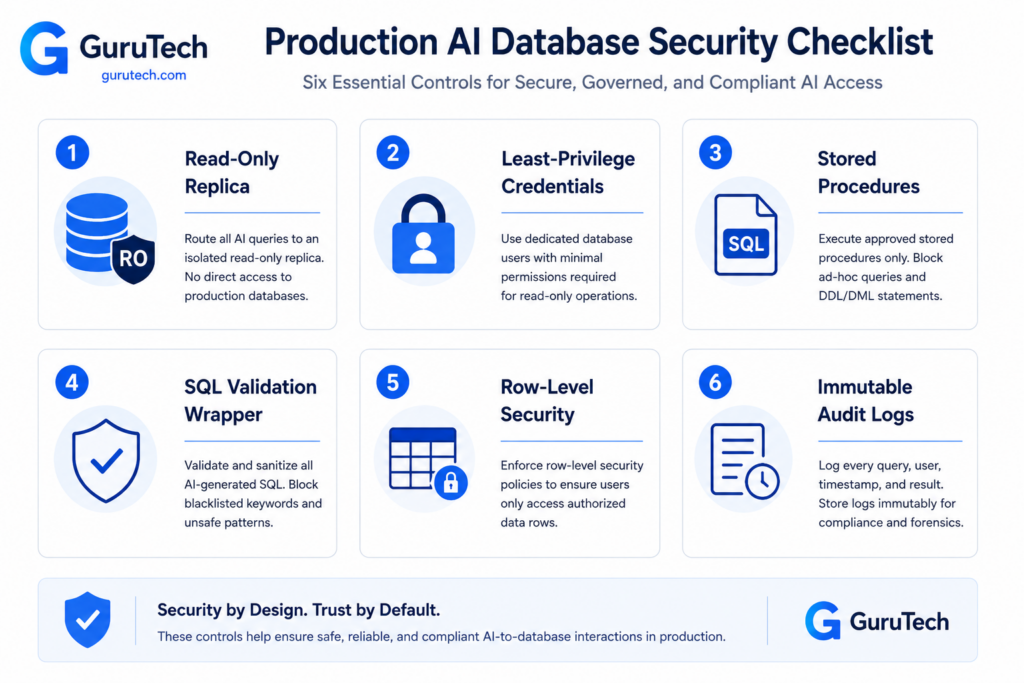
Security Checklist for Production AI Database Systems
Production AI database systems require multiple security layers to prevent unauthorized access and resource abuse. The official OWASP Top 10 for LLM Applications identifies critical vulnerabilities that enterprises must address when deploying language models with database connectivity.
Database Access Controls
| Security Layer | Implementation | Risk Mitigated |
|---|---|---|
| Read-only credentials | GRANT SELECT only on approved tables | Prevents data modification or deletion |
| Schema exposure filtering | Curated table/column lists in prompts | Blocks access to sensitive metadata |
| Row-level security policies | PostgreSQL RLS with current_setting() | Enforces multi-tenant isolation |
| Statement timeouts | SET statement_timeout = 5000 | Stops runaway queries |
Organizations must create dedicated database roles specifically for AI-generated queries. These roles should have explicitly denied access to tables containing credentials, API keys, or personally identifiable information.
Query Validation Pipeline
Every AI-generated query requires parsing and validation before execution. SQL parsers should verify that statements are SELECT-only, reference permitted tables, and include LIMIT clauses. The EXPLAIN command provides cost estimation to reject computationally expensive operations before they consume database resources.
Resource Governance
Connection pooling settings must enforce maximum query execution time and memory allocation. Setting work_mem to 64MB or lower prevents individual queries from monopolizing database resources. Enterprise AI security frameworks recommend implementing circuit breakers that disable AI database access after repeated timeout failures.
Production deployments should log every generated query with execution time, result row counts, and user context. This audit trail enables security teams to identify prompt injection attempts and refine validation rules based on actual attack patterns.
Summary: Data Governance Dictates AI Capability
As organizations move beyond document processing and Retrieval-Augmented Generation systems into live transactional workflows, secure database connectivity becomes one of the most important architectural decisions in the entire AI stack.
The strongest AI systems are not defined by the size of their models or the sophistication of their prompts. They are defined by the quality of their guardrails. Read-only replicas, stored procedure gateways, semantic query validation, role-based access controls, audit logging, and approval workflows create the defensive layers required for enterprise-grade deployments.
Whether you are building AI agent database orchestration pipelines in n8n, deploying customer support copilots, or enabling natural-language analytics across operational systems, the guiding principle remains the same: never allow an LLM to interact directly with production databases without strict governance controls.
A secure database connection for LLMs should always follow a zero-trust design where every request is validated, every query is logged, and every privilege is explicitly granted rather than assumed.
The future of enterprise AI will not be determined by who has access to the most powerful model. It will be determined by who can safely connect those models to business-critical systems without compromising security, compliance, or operational stability.
Are your AI agents connected directly to live databases, or are you running a read-only replica and validation layer? Share your architecture approach in the comments below for a GuruTech architecture review.
Frequently Asked Questions
Production deployments of LLM-to-database systems require specific authentication mechanisms, query isolation patterns, and auditing infrastructure that differ from traditional application architectures. The bursty nature of AI-generated queries introduces unique challenges for connection management, credential rotation, and compliance logging.
What authentication patterns (IAM roles, service accounts, mTLS) are recommended for production-grade database access from an LLM application?
IAM role-based authentication provides the strongest security posture for cloud-deployed LLM applications connecting to managed databases. AWS RDS supports IAM database authentication where the application exchanges a temporary token for database access without embedding credentials in code. Azure SQL Database implements similar functionality through Azure Active Directory authentication.
Service accounts with certificate-based authentication offer robust security for hybrid and multi-cloud deployments. The LLM application presents a client certificate during the TLS handshake, and the database validates the certificate against a trusted CA before granting access. This approach eliminates password-based authentication entirely.
Mutual TLS (mTLS) adds bidirectional verification where both the client and server authenticate each other using certificates. PostgreSQL supports mTLS through the ssl_cert_file and ssl_ca_file configuration parameters. The database verifies the client certificate’s CN (Common Name) against the database username.
For on-premises deployments, Kerberos authentication integrated with Active Directory provides centralized identity management. The LLM service authenticates to the domain controller and receives a ticket that grants database access. This pattern works well in enterprises with existing Kerberos infrastructure.
The weakest acceptable pattern uses service accounts with long-lived passwords stored in secrets managers. While less secure than certificate-based methods, this approach remains viable when combined with proper secrets rotation practices and network segmentation.
How can I implement least-privilege, read-only query execution for an LLM while still supporting complex analytics workflows?
Creating dedicated read-only database roles specifically for AI-generated queries forms the foundation of least-privilege access. The role receives SELECT permissions only on approved tables and views, with explicit REVOKE statements on sensitive tables like user credentials or internal configurations.
Database views provide schema abstraction that exposes analytical data while hiding sensitive columns. A view might join customer orders with product catalogs but exclude cost basis, supplier information, and profit margins. The LLM queries the view without knowing the underlying table structure.
Row-level security (RLS) policies enforce data isolation in multi-tenant environments. PostgreSQL RLS policies filter query results based on session variables set before query execution. The application sets current_setting('app.tenant_id') and the policy automatically restricts results to that tenant’s data.
Column-level permissions allow fine-grained control over which fields the LLM can access. A role might have SELECT permission on customers.name and customers.email but not customers.credit_card_hash or customers.ssn. The LLM cannot reference columns it lacks permission to read.
Materialized views pre-aggregate data for common analytical queries while limiting access to raw transactional records. The LLM queries a materialized view containing daily sales summaries rather than accessing millions of individual order line items. This pattern improves both security and performance.
For complex analytics requiring temporary tables or CTEs, implementing query validation through SQL parsing ensures the LLM cannot escalate privileges. The validator confirms that generated queries only reference approved objects and contain no DDL or DML statements.
What is the reference architecture for routing LLM-driven SQL through an API gateway or query service to avoid direct database exposure?
A proxy layer sits between the LLM application and the database, intercepting all queries for validation, transformation, and execution. The LLM sends a natural language question to the query service API, which generates SQL, validates it against security policies, and executes it using a dedicated connection pool.
The API gateway pattern implements the proxy as a separate service with its own authentication, rate limiting, and logging. Kong, Apigee, or custom FastAPI services expose endpoints like /query that accept natural language input and return structured results. The database credentials never leave the gateway service.
AWS Lambda or Azure Functions can implement serverless query execution where each invocation receives a time-limited database token. The function validates the generated SQL, executes it with a timeout, and returns results. This architecture automatically scales with query load and provides built-in isolation between executions.
Database abstraction layers like GraphQL APIs provide schema-based access control where the LLM queries a GraphQL endpoint rather than generating raw SQL. Hasura or PostGraphile enforce permissions at the GraphQL layer before translating approved operations into database queries. This approach works well when the LLM can learn GraphQL syntax.
Connection pooling managers like PgBouncer or ProxySQL sit between the query service and database, managing connection reuse and query routing. The query service connects to PgBouncer, which maintains a pool of authenticated database connections. This reduces connection overhead and provides centralized query logging.
For enterprise deployments requiring air-gapped environments, the proxy layer runs on-premises with no direct internet access. The LLM communicates with the proxy through a DMZ API endpoint that forwards approved queries to the internal network.
How should connection pooling, timeouts, and retry policies be tuned for LLM workloads that generate bursty and unpredictable query patterns?
Connection pool sizes must accommodate the variance between idle periods and sudden bursts when multiple users simultaneously ask questions. A pool with min_size=5 and max_size=50 allows the application to maintain baseline connections while scaling up during high activity. The pg library for Node.js or asyncpg for Python support dynamic pool sizing.
Statement timeouts prevent runaway queries from blocking connections indefinitely. Setting statement_timeout=5000 at the session level terminates any query exceeding 5 seconds. This aggressive timeout suits LLM workloads where users expect quick responses and long-running queries indicate inefficient SQL generation.
Idle connection timeouts reclaim pooled connections during quiet periods. Configuring idleTimeoutMillis=30000 closes connections idle for 30 seconds, preventing resource waste. This matters for serverless deployments where database connection limits constrain concurrent executions.
Query cost estimation through EXPLAIN analysis before execution prevents expensive queries from starting. If the planner estimates a cost exceeding a threshold such as 100,000, the system should reject the query, ask the LLM to produce a narrower version, and return a safe message explaining that the request was too broad.
Retry policies should distinguish between transient infrastructure failures and unsafe query generation. Network timeouts may receive one or two retries with exponential backoff. Validation failures should never be retried automatically, because repeating an unsafe query generation loop can create unnecessary load and hide an attempted prompt injection event.
For production systems, a practical default is a five-second statement timeout, one retry for transient errors, hard rejection for validation errors, and automatic circuit breaking after repeated failures from the same user, API key, or workflow execution path.
Should an LLM ever receive direct write access to a production database?
In most enterprise environments, the answer should be no. Direct write access gives the model the ability to modify business records based on probabilistic reasoning, prompt context, or user manipulation. Even when the model appears accurate, the operational blast radius is too large for unsupervised write privileges.
A safer design uses approval gates, stored procedures, and event queues. The LLM can propose a change, but a deterministic service validates the request and either routes it to a human reviewer or executes a tightly scoped stored procedure with predefined parameters. DELETE operations should be excluded from autonomous workflows unless the environment is fully isolated and the data is non-critical.
What is the safest starting architecture for a business experimenting with AI database workflows?
The safest starting architecture is a read-only replica connected through an API or workflow layer, not direct access to the primary production database. The LLM should receive only a minimal schema map, generate structured arguments, and pass those arguments through a validator before any database connector runs.
From there, teams can add row-level security, immutable audit logs, semantic query guards, and human approval workflows. This staged approach allows the business to gain value from natural-language database interaction without giving the model uncontrolled authority over transactional systems.