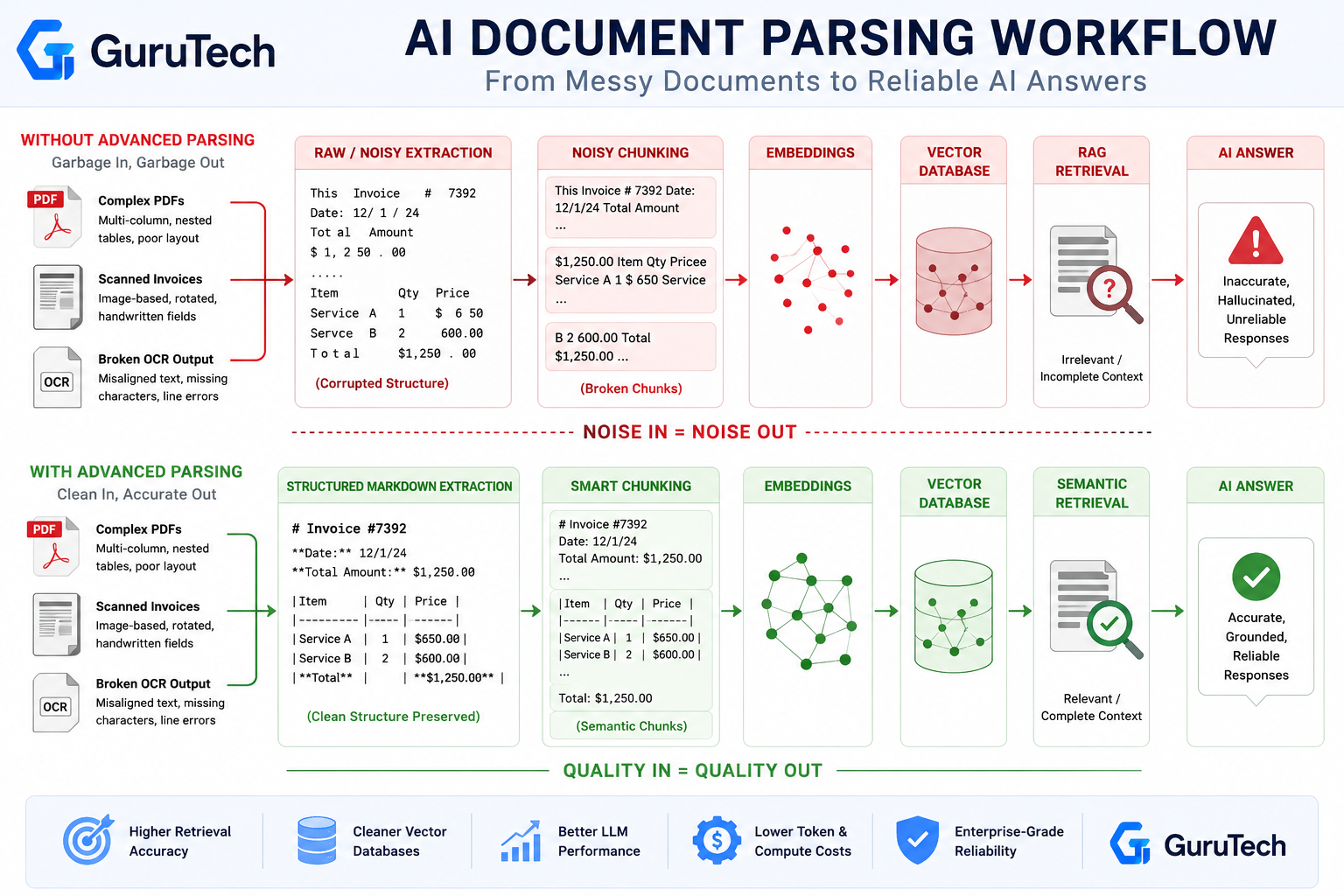
Enterprise AI systems fail upstream. Before embeddings reach vector stores or semantic routers query knowledge bases, raw documents pass through ingestion pipelines where corruption begins.
PDFs arrive with embedded OCR layers containing invisible misaligned text. Scanned invoices contain rotated tables that standard parsers cannot reconstruct.
Legacy contracts mix handwritten annotations with multi-column layouts that break traditional extraction logic. AI document parsing functions as the critical infrastructure layer that determines whether RAG pipelines retrieve accurate context or inject noise into generation workflows.
Without clean extraction at the document layer, downstream systems inherit malformed chunks and semantically corrupted passages that degrade retrieval precision across entire knowledge graphs.
The advanced IDP systems now achieve up to 99.9% accuracy while processing complex document structures. Most production environments still operate with fragile parsing chains built from outdated OCR engines and rigid template-based extractors.
These legacy tools cannot parse documents with inconsistent layouts and fail on handwritten form fields. They produce markdown outputs with corrupted table structures that poison vector similarity searches.
Modern AI document parsing solutions must handle layout reconstruction, semantic segmentation, and format normalization before passing structured content into embedding models or retrieval systems.Parsing raw text into markdown is the first step. To make this data functional, it must either be indexed cleanly into vector databases for AI or fed directly into an engine built for programmatic document generation.
Production RAG architectures require deterministic ingestion workflows where data parsing transforms unstructured PDFs into clean markdown representations that preserve logical document structure.
When teams extract text from PDF files without layout-aware processing, they generate chunks that split mid-sentence and separate table headers from data rows. Multi-page sections fragment into semantically disconnected passages.
LLM data cleaning becomes impossible after poor initial extraction. Engineering teams must rebuild entire ingestion pipelines when retrieval accuracy degrades.
Organizations deploying RAG systems must architect document parsing infrastructure that produces structured markdown extraction suitable for embedding generation, not just raw text dumps that appear functional during development but fail under production document variance.
Key Takeaways
- AI document parsing determines RAG pipeline accuracy by preventing corrupted data from reaching vector databases and embedding models
- Traditional OCR and template-based extractors fail on complex layouts, producing broken tables and fragmented text that degrade retrieval precision
- Modern ingestion architectures require layout-aware parsing that converts PDFs into structured markdown while preserving semantic relationships across document elements
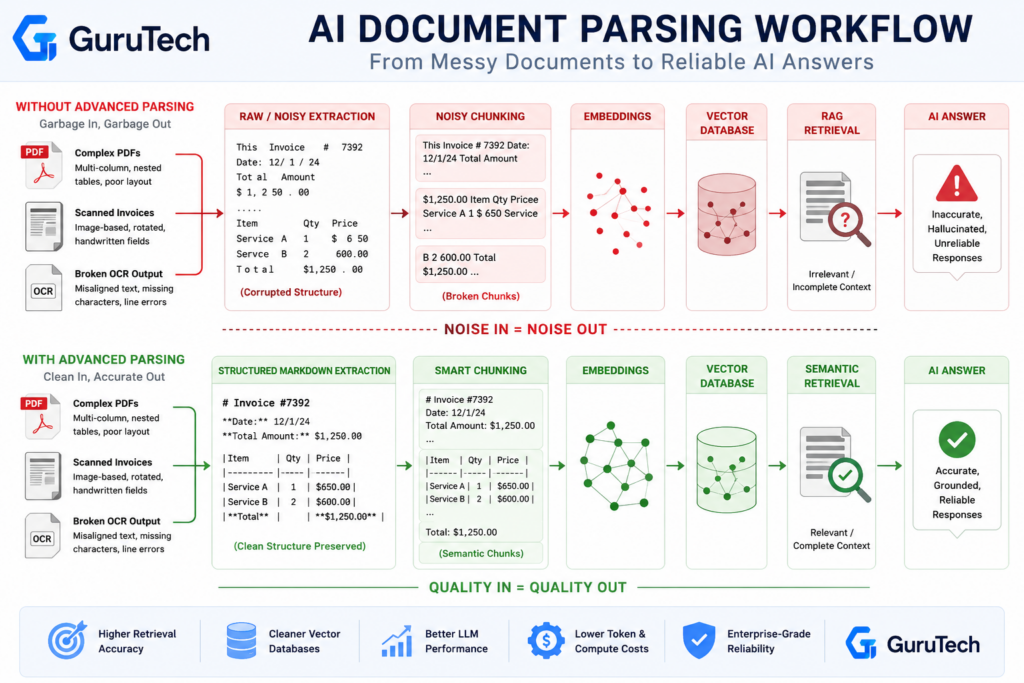
The Mechanics of Data Destruction: Why Traditional Parsers Fail
Traditional parsers operate on rigid rule-based logic that assumes documents follow predictable hierarchies and formatting conventions. When PDFs deviate from expected structures—nested tables, multi-column layouts, rotated text blocks—these systems fragment content into incoherent chunks that poison downstream RAG pipelines.
The most enterprise AI hallucinations stem from upstream parsing failures rather than model deficiencies.
PDF format design exacerbates this fragility. Unlike HTML’s semantic markup, PDFs store content as rendering instructions—coordinates, fonts, drawing commands—without inherent document structure.
Extracting text from PDFs remains architecturally problematic because parsers must reverse-engineer logical reading order from visual positioning data.
Common failure modes include:
- Table decomposition errors where cell boundaries collapse into linear text streams
- Header/footer contamination bleeding metadata into body content during markdown text conversion
- Citation reference mangling that severs footnote-to-text associations
- Mathematical expression degradation reducing LaTeX formulas to ASCII gibberish
Legacy OCR systems compound these issues by treating documents as image-to-text translation tasks without semantic understanding. They extract character sequences but destroy spatial relationships essential for AI ingestion pipelines.
A scanned research paper becomes a flat text string where equations, captions, and prose merge indistinguishably.
Rule-based layout analysis fails on the long tail of document variants. Engineers maintain brittle heuristics—”text blocks within 12 pixels constitute paragraphs”—that break on unconventional designs.
This brittleness forces teams into perpetual maintenance cycles, patching parsers for each new document schema encountered in production systems.
Common AI Parsing Failures That Break RAG Pipelines
Most RAG systems fail at document parsing, not at retrieval or generation. When PDF parsing for LLMs goes wrong, the entire pipeline degrades silently.
Text extraction drops tables, merges columns, and loses hierarchical structure before embeddings are even computed. The failure chain follows a predictable pattern: corrupted parse output creates malformed chunks, weak embeddings encode incomplete context, and retrieval returns irrelevant results.
Your RAG system’s accuracy ceiling is your parser, not your model.
Multi-column layouts break reading order. Traditional parsers extract text from PDF left-to-right across the page, mixing content from separate columns. The output appears plausible but semantic meaning collapses.
OCR for AI systems compounds this when processing scanned documents with rotated pages or embedded fonts.
Table structures flatten into unstructured text. Cell boundaries disappear during markdown text conversion, destroying relationships between headers and data. Financial reports and technical specifications become unusable for RAG data ingestion without layout-aware parsing.
Visual noise contaminates chunks. Headers, footers, page numbers, and watermarks leak into extracted content. LLM data cleaning pipelines must filter these artifacts, but most teams discover contamination only after production deployment.
The limitations of rule-based extraction become apparent at enterprise scale. Confidence in parsed output requires validation layers that check for broken tables, missing sections, and malformed structure.
Parsing failures are silent, making them more dangerous than obvious errors. Detection strategies must run before AI ingestion pipelines commit corrupted data to vector stores.
The 2026 AI Ingestion Stack: Document Extraction Tools Compared
The production document AI stack has consolidated around vision LLMs and specialized extraction engines that handle PDF, DOCX, PPTX, TIF, PNG, JPG, and JPEG inputs for RAG pipelines and structured data workflows.
Mistral OCR 3 achieves 96.6% accuracy on tables and 88.9% on handwriting recognition, outperforming Azure and AWS Textract on complex layouts with checkbox recognition and multi-format ingestion across 60+ languages.
Google Document AI and Airparser dominate enterprise deployments for invoice and form extraction. Parseur handles email-attached document workflows with zonal OCR logic.
For RAG data ingestion specifically, teams layer vision LLMs over traditional AI OCR to extract text from PDF with layout preservation. They apply LLM data cleaning passes before markdown text conversion.
Advanced PDF understanding now relies on VLMs like GPT-4o that collapse OCR, layout analysis, and entity extraction into single API calls.
These systems ingest DOCX, PPTX, and TIFF formats without preprocessing, outputting structured markdown extraction ready for vector embedding.
The OCR model leaderboard for 2026 ranks models by OmniDocBench scores and inference speed. Docling emerges as the open-source alternative for teams requiring on-premise deployment.
Production AI ingestion pipelines now handle AI data extraction at scale with batch APIs processing 2,000+ pages per minute.
DocParserAI, SmartAI Parser, and ResumeAI Parser target vertical-specific workflows—contracts, receipts, and resumes—with pre-trained extraction schemas that reduce fine-tuning overhead compared to generic PDF parsing for LLMs approaches.
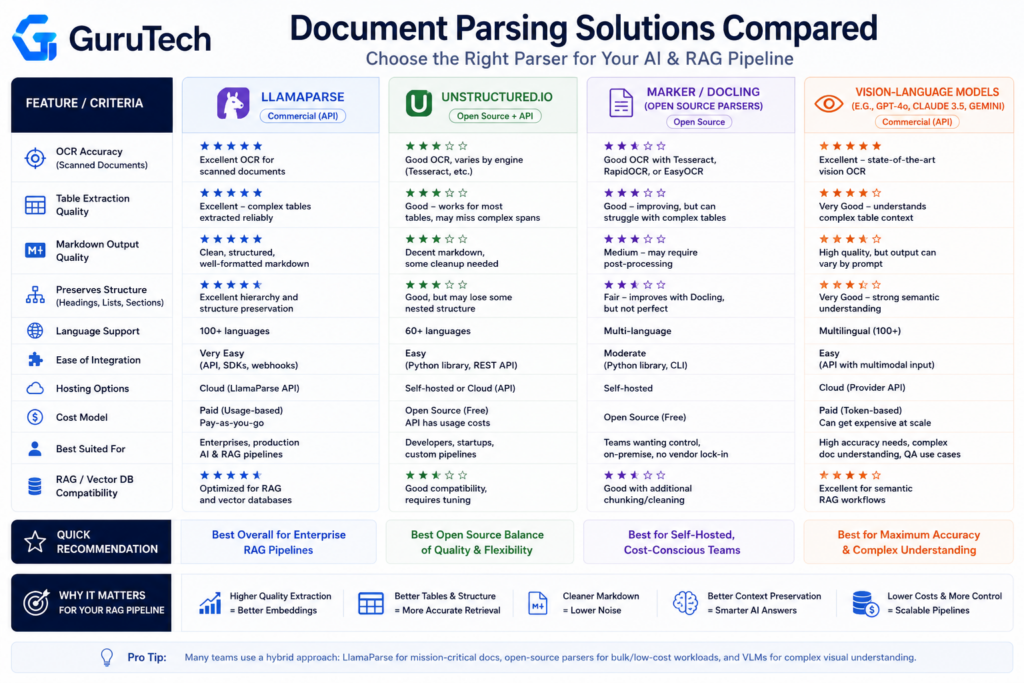
Why Markdown Became the Preferred AI Intermediary Format
Markdown emerged as the de facto intermediary format in AI ingestion pipelines because it preserves semantic structure while eliminating the token overhead that plagues HTML and proprietary formats.
When engineers extract text from PDF files or process DOCX documents for RAG data ingestion, the conversion target is almost universally markdown because LLMs can parse heading hierarchies, lists, and tables without wading through formatting artifacts.
The token efficiency advantage is measurable. HTML wraps content in <div> tags, class attributes, and styling metadata that consume tokens without contributing semantic value.
JSON introduces structural overhead with brackets, quotes, and key-value pairs. Markdown uses # for headings and - for lists, achieving the same structural clarity at a fraction of the token cost.
Format comparison for LLM processing:
| Format | Syntax Overhead | Structure Preservation | Token Efficiency |
|---|---|---|---|
| HTML | High | Good | Poor |
| JSON | Medium | Excellent | Medium |
| Markdown | Minimal | Good | Excellent |
| Plain Text | None | None | Excellent |
Markdown’s token efficiency directly reduces API costs in production RAG pipelines where thousands of documents flow through embedding models daily.
The format also creates natural chunking boundaries at header levels, solving a persistent problem in LLM data cleaning workflows where arbitrary character splits fragment semantic units.
OCR for AI systems outputs increasingly target markdown because downstream models trained on web text recognize the syntax natively.
Enterprise document processing systems now prioritize markdown text conversion as documents move from legacy formats into vector databases and retrieval systems.
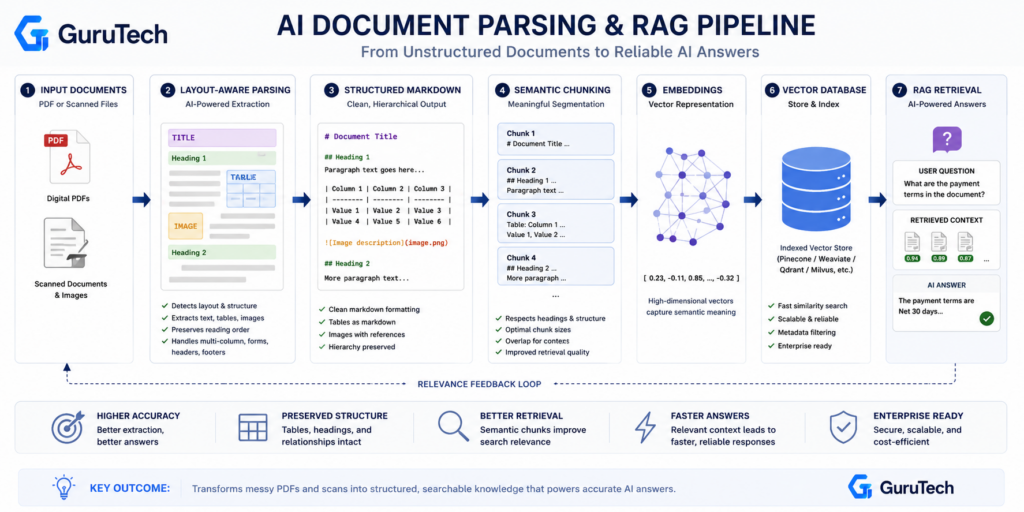
Step-by-Step Logic: Building a Clean AI Parsing Pipeline
A production-grade parsing pipeline requires four sequential transformations: breaking documents into logical units and isolating tabular structures from prose.
Splitting content into retrieval-optimized chunks and preparing vectors for semantic search completes the pipeline. Each layer enforces structure before passing data downstream.
Document Segmentation
Document identification begins by routing inputs through format-specific handlers based on MIME type and file signature validation. PDFs require different processors than DOCX or technical report formats.
Routing documents through tiered parsers by complexity ensures efficient resource allocation. Each parser extracts raw content while preserving structural metadata such as headings, page boundaries, and section hierarchies.
Layout analysis identifies visual blocks—headers, footers, multi-column regions, and embedded objects. Modern pipelines use vision transformers to detect reading order and hierarchy, avoiding reliance on coordinate-based heuristics.
The output is a JSON tree representing logical document structure, not just sequential text. Metadata extraction captures creation date, author fields, document type, and any embedded annotations or comments.
This metadata feeds downstream filtering and automated rule creation for document classification. Systems that handle massive document workloads tag each segment with provenance data to maintain audit trails through the entire pipeline.
Table Extraction
Tables require specialized extraction because LLMs struggle with implicit spatial relationships in plain text. Computer vision models detect table boundaries, then cell-level parsers reconstruct row-column grids.
Preserving merged cells, nested headers, and footnotes that anchor numeric data remains a core challenge. Automatic extraction converts tables into structured formats like CSV or JSON arrays.
For RAG data ingestion, markdown tables offer readability while maintaining column alignment. The parser must decide whether to inline tables within surrounding text or split them into separate retrieval units with cross-references.
Complex tables in financial documents or scientific papers demand customizable parsing rules. Engineers define cell validation schemas, handle spanning headers, and map abbreviations using domain lexicons.
Output quality depends on the system’s ability to represent hierarchical row groupings and multi-level column headers without flattening semantic relationships.
Text Splitting and Chunking
LLM data cleaning begins after extraction by normalizing whitespace, removing artifacts from OCR errors, and standardizing unicode encoding. Chunking strategies then divide content into token-limited segments that fit model context windows while respecting semantic boundaries.
Sentence-based splitting preserves grammatical integrity but creates uneven chunk sizes. Paragraph-level chunks maintain topic coherence but may exceed token limits in dense prose.
Hybrid approaches use recursive splitting—start with sections, subdivide by paragraphs, then truncate at sentence boundaries when necessary. Overlap between adjacent chunks prevents context loss at boundaries.
A 10-15% overlap ensures that concepts spanning chunk edges remain retrievable. Chunk metadata includes parent document ID, section title, page number, and character offsets for precise citation retrieval.
Embedding Preparation
The final stage transforms chunks into vector representations through ai_prep_search operations. Text undergoes tokenization, normalization, and encoding through embedding models optimized for semantic similarity.
Dense vectors enable cosine-distance comparisons during retrieval. Preprocessing removes stopwords, applies stemming, and filters non-semantic tokens like pagination markers.
Some pipelines generate multiple embeddings per chunk—one for dense retrieval, another for hybrid search combining keyword and vector signals. Metadata fields become filterable attributes in the vector database schema.
Systems that upload files through batch APIs require queueing logic to throttle concurrent embedding requests. Rate limits and retry policies prevent pipeline failures during high-volume ingestion.
The output is a searchable index where each vector links back to source text. This enables RAG systems to ground LLM responses in retrieved document fragments.
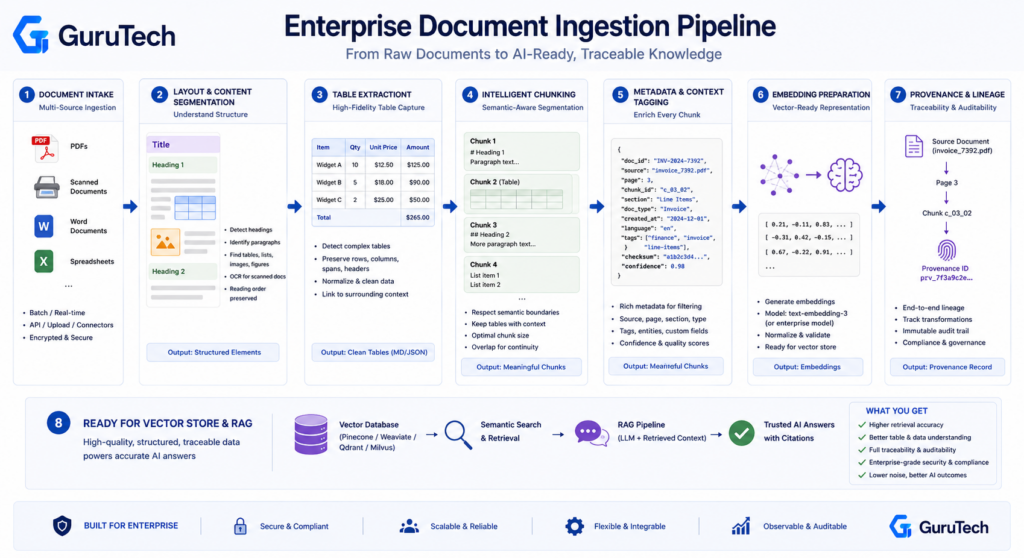
Why Clean Parsing Matters for AI Automation Systems
Clean parsing directly determines the reliability of downstream AI automation systems. When document parsing transforms unstructured files into machine-readable structures, any extraction errors propagate through RAG pipelines, corrupting retrieval accuracy and generating hallucinated responses.
Poor LLM data cleaning creates cascading failures across integrations. Production document automation requires deterministic data extraction that maintains semantic relationships between text, tables, and metadata.
Systems that extract text from PDF without preserving structural hierarchy produce flattened content that destroys contextual information needed for accurate embedding generation. This breaks RAG data ingestion workflows where vector stores depend on coherent semantic chunks.
Critical requirements for production parsing:
- Format preservation: Markdown text conversion must maintain document structure for chunking strategies
- API compatibility: REST API endpoints need consistent JSON schemas for downstream integrations
- Execution flexibility: Serverless compute and local execution options prevent vendor lock-in
- Data governance: Unity Catalog integration ensures parsed outputs meet compliance requirements
- Workflow orchestration: Webhooks enable event-driven architectures for export automation
OCR for AI systems introduces additional complexity when processing scanned documents. Character recognition errors compound during structured markdown extraction, requiring validation layers before feeding content into LLM contexts.
AI ingestion pipelines must implement correction loops that verify extracted data against schema constraints. Document processing at scale demands repeatable parsing that handles format variations without manual intervention.
Automated document parsing powered by AI and ML eliminates template dependencies. Production systems still need deterministic outputs for financial reconciliation, contract analysis, and compliance workflows where extraction accuracy directly impacts business logic execution.
Preparing for the Generation Layer
Once document parsing extracts structured content from PDFs and other formats, the generation layer requires specific data transformations to maximize LLM performance. Teams must convert parsed outputs into clean markdown text that preserves hierarchical structure while removing artifacts that degrade retrieval quality during RAG data ingestion.
The ai_parse_document function outputs structured JSON that downstream systems can process for content summarization and context assembly. This JSON output contains document chunks with embedded metadata, enabling filtering strategies based on section type, confidence scores, or semantic relevance.
LLM data cleaning at this stage involves normalizing table structures, resolving cross-references, and standardizing header hierarchies across document collections.
Critical preprocessing tasks include:
- Text normalization: Removing OCR errors and standardizing character encodings
- Chunk boundary optimization: Splitting content at logical breaks rather than arbitrary token limits
- Metadata enrichment: Tagging chunks with document type, page numbers, and structural roles
- Format conversion: Transforming proprietary formats into markdown text conversion for consistent LLM consumption
AI ingestion pipelines must account for AI function availability constraints when deploying parsing workflows across regions. Production systems typically implement validation layers that filter AI outputs based on confidence thresholds before passing data to vector databases.
Integration frameworks like LlamaIndex provide specialized connectors for structured markdown extraction. This enables agentic AI systems to query parsed documents with semantic precision.
The ai_prep_search function in Document Parsing workflows specifically optimizes parsed content for retrieval operations, handling tokenization and embedding preparation without manual intervention.
Frequently Asked Questions
Production document parsing systems require architectural decisions around ingestion pipelines, quality measurement frameworks, parsing strategy selection, RAG integration patterns, security controls, and deployment topology. These decisions directly impact throughput, accuracy, and operational risk.
How do you architect a production-grade document ingestion pipeline that handles PDFs, scanned images, and Office formats with consistent layout-aware extraction and schema normalization?
A robust ingestion pipeline begins with format normalization. PDFs require rendering to high-resolution images (300 DPI minimum) using pdf2image or PyMuPDF before feeding to vision-language models.
Office formats (DOCX, PPTX) need conversion through LibreOffice headless mode or dedicated converters that preserve layout semantics. Scanned images enter directly after preprocessing that includes deskewing, contrast normalization, and noise reduction for low-quality faxes or mobile captures.
The layout-aware extraction layer applies a vision-language model that processes document images holistically rather than treating them as linear text streams. This approach preserves spatial relationships between labels and values, table cell associations, and multi-column layouts that OCR-then-parse workflows destroy.
Schema normalization happens post-extraction through JSON Schema validation with type coercion, field mapping between document-specific terminology and canonical field names, and conflict resolution when multiple extraction candidates exist for a single field.
Pipeline resilience requires retry logic with exponential backoff for transient failures, dead-letter queues for documents that fail extraction after N attempts, and idempotency keys derived from document content hashes to prevent duplicate processing.
Format detection runs before parsing to route documents to specialized handlers—invoices to invoice-tuned models, contracts to long-context processors, and forms to field-extraction optimized endpoints.
What evaluation methodology and ground-truth strategy best measures extraction quality for tables, forms, and key–value pairs across heterogeneous document templates and languages?
Ground-truth creation for document parsing requires human annotation of representative samples stratified by document type, layout complexity, language, and quality (born-digital versus scanned versus mobile-captured).
Annotators mark field boundaries with bounding boxes, label each field semantically, and transcribe exact values including formatting like decimal precision and date formats. A minimum of 50-100 annotated documents per major template variation provides statistical validity for accuracy measurement.
Table extraction quality demands cell-level accuracy metrics rather than whole-table pass/fail. The evaluation framework compares extracted tables against ground truth using edit distance on cell values, structural similarity measuring row and column preservation, and header-mapping correctness for multi-level column headers.
Form extraction tracks field-level precision and recall, treating each form field as an independent extraction task where false positives (hallucinated fields) and false negatives (missed fields) are weighted equally.
Key-value pair extraction evaluation measures exact-match accuracy for fields where precision matters (amounts, dates, identification numbers) and fuzzy-match accuracy using Levenshtein distance for fields where minor OCR errors are acceptable (company names, addresses).
Cross-lingual evaluation requires native speakers to validate extraction accuracy since multilingual documents frequently mix languages within single fields. Regression testing against the annotated corpus runs on every model update to detect accuracy degradation on specific document classes.
How should an enterprise choose between OCR-first, layout-model-first, and multimodal parsing approaches to optimize latency, accuracy, and cost across high-volume workloads?
OCR-first architectures using Tesseract or cloud OCR APIs followed by rule-based extraction deliver sub-second latency and minimal compute cost but require extensive template maintenance and fail on layout variations.
This approach suits high-volume processing of strictly formatted documents from a small set of known templates where layout never changes—government forms, standardized invoices from integrated suppliers, or internally generated reports.
Layout-model-first approaches apply document layout analysis models like LayoutLM or Donut that segment documents into regions (text blocks, tables, figures) before extracting content from each region. These models achieve higher accuracy on structured documents with complex layouts but require fine-tuning on domain-specific documents and impose 2-5 second per-page latency.
Enterprises processing insurance claims, legal filings, or medical records where layout complexity is high but document types are limited benefit from this architecture.
Multimodal parsing using vision-language models processes document images directly without separate OCR or layout analysis stages. This approach generalizes across document types without fine-tuning, handles multilingual and mixed-language documents natively, and maintains semantic understanding of document content.
Latency ranges from 3-8 seconds per page depending on model size and hardware, with costs of $0.01-0.05 per page on cloud endpoints. Enterprises with heterogeneous document sources, frequent template changes, or international operations find multimodal parsing delivers the best accuracy-maintenance tradeoff despite higher per-document cost.
What are the recommended patterns for integrating parsed document outputs into RAG pipelines, including chunking, citation anchoring, and provenance tracking back to page coordinates?
RAG pipelines consume parsed documents as structured markdown. Headings, tables, and lists preserve document semantics better than plain text.
The parser outputs markdown-formatted text with preserved structure. It also generates a metadata object containing document identifiers, page numbers, extraction timestamps, and bounding box coordinates for each extracted section.
This dual output enables both semantic search over structured content and precise citation retrieval.
Chunking strategies for parsed documents respect document structure boundaries. Sections under a single heading form natural chunks.
Table rows group together with table headers included in each chunk for context. Key-value pairs from forms chunk together by logical grouping, such as invoice header fields separate from line items.
Chunk size targets 500-1000 tokens to fit within embedding model context windows while maintaining semantic coherence. Each chunk embeds with metadata including source document ID, page number, section heading path, and bounding box coordinates.
The RAG retrieval layer returns relevant chunks and their provenance metadata. When the LLM generates an answer citing chunk C₁₇, the application maps C₁₇ back to its source document, page number, and bounding box coordinates.
The UI renders the source document with the cited region highlighted. This approach allows users to verify the LLM’s interpretation against source material.
Provenance tracking enables document-level access control. Retrieved chunks inherit permissions from their source documents, preventing information leakage across security boundaries.
How do you implement security and compliance controls (PII/PHI detection, redaction, encryption, audit logging, and retention) within an automated document parsing workflow?
Document ingestion pipelines handling sensitive data require fine-grained security and compliance controls at each stage of the workflow.
The first control layer is classification. Before documents move into parsing or embedding workflows, the system should detect PII, PHI, financial identifiers, customer records, contract terms, and other regulated fields. Sensitive values can then be masked, tokenized, or redacted before parsed text enters LLM prompts, vector databases, or downstream automation systems.
Encryption must apply both in transit and at rest. Source files, parsed markdown, extracted tables, embeddings, metadata stores, and audit logs should use encrypted storage with access controls tied to enterprise identity providers such as Okta, Microsoft Entra ID, or another centralized IAM layer. Short-lived access tokens and signed retrieval requests reduce the risk of unauthorized access inside multi-agent workflows.
Audit logging should capture document uploads, parser selection, extraction timestamps, model versions, redaction events, user access requests, retrieval queries, and downstream AI actions. These logs help support SOC 2, HIPAA, GDPR, financial-sector retention policies, and internal governance reviews.
Retention controls should define how long source files, parsed outputs, embeddings, and derived summaries remain available. When retention windows expire, the system should remove both the original document artifacts and their vector representations so sensitive content does not persist inside retrieval indexes.
High-security environments often deploy parsing workflows inside private cloud or self-hosted infrastructure. This design keeps regulated documents within controlled network boundaries while preserving the benefits of structured extraction, RAG retrieval, and AI-assisted automation.
Clean AI document parsing is not just an extraction problem. It is a governance layer that determines whether enterprise AI systems can safely transform messy source documents into reliable, auditable, and production-ready automation workflows.
Organizations deploying AI document parsing systems inside regulated industries must implement layered security controls before documents enter retrieval pipelines or vector databases. Personally identifiable information (PII), protected health information (PHI), financial records, and legal materials require automated classification and redaction workflows that operate during ingestion rather than after embedding generation.
Modern parsing pipelines apply entity-recognition models to identify names, addresses, medical identifiers, financial account numbers, and jurisdiction-specific regulated data fields. Sensitive content can then be masked, tokenized, or removed before downstream RAG systems process the extracted markdown.
Encryption must apply both in transit and at rest across document storage, vector indexes, metadata stores, and retrieval layers. Enterprise AI ingestion systems typically integrate with centralized identity providers such as Okta, Azure Active Directory, or IAM frameworks to enforce role-based access control policies across parsing and retrieval operations.
Audit logging requirements extend beyond simple upload tracking. Production systems must log document ingestion events, parsing model versions, retrieval requests, embedding operations, access attempts, and downstream AI interactions to satisfy compliance frameworks such as HIPAA, SOC 2, GDPR, and financial-sector retention mandates.
Retention management policies should automatically archive or purge parsed documents, embeddings, and temporary extraction artifacts after defined compliance windows expire. High-security environments increasingly deploy self-hosted parsing infrastructure with isolated inference servers and private vector databases to prevent sensitive enterprise documents from leaving internal network boundaries.
Final Thoughts: Parsing Is the Foundation of Enterprise AI Systems
AI document parsing is no longer a preprocessing utility hidden behind retrieval pipelines. It has become one of the most critical infrastructure layers inside modern enterprise AI architectures.
When parsing systems fail, downstream embeddings inherit corrupted context, semantic retrieval accuracy collapses, and AI agents generate unreliable outputs regardless of model size or orchestration complexity.
Organizations building production-grade RAG systems, automation workflows, and multi-agent AI architectures increasingly recognize that clean ingestion pipelines determine whether AI deployments scale reliably under real-world document variance.
Modern parsing infrastructure must preserve layout semantics, reconstruct tables accurately, normalize markdown structures, and maintain provenance metadata throughout the retrieval lifecycle. These ingestion decisions directly influence vector database quality, semantic routing precision, and downstream generation accuracy.
Now that we have successfully parsed messy PDFs, spreadsheets, and scanned documents into structured markdown data, the next stage is generation. In the next guide, we will explore how AI agents can programmatically transform structured markdown into fully formatted PowerPoint presentations, executive reports, and production-ready business deliverables.