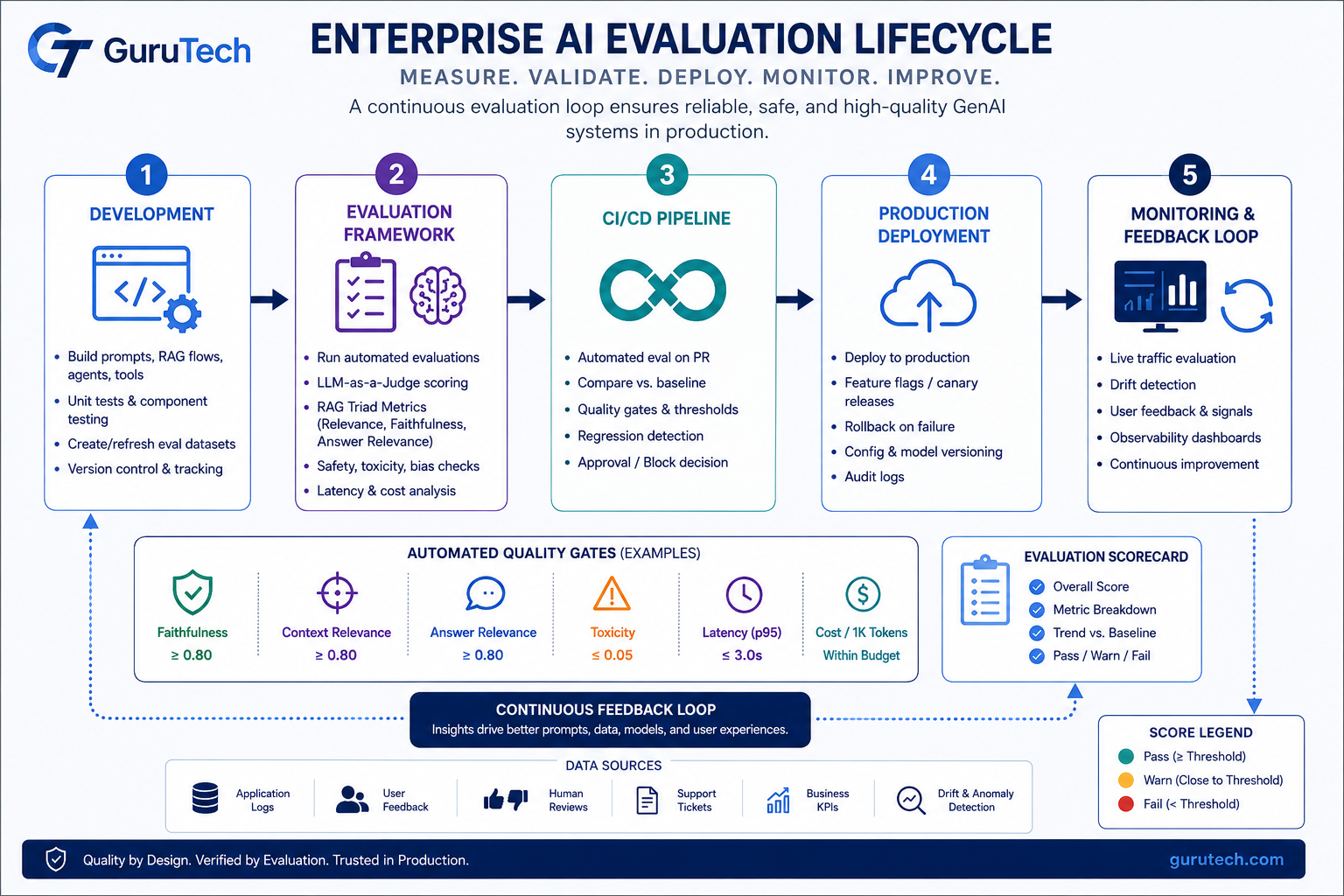
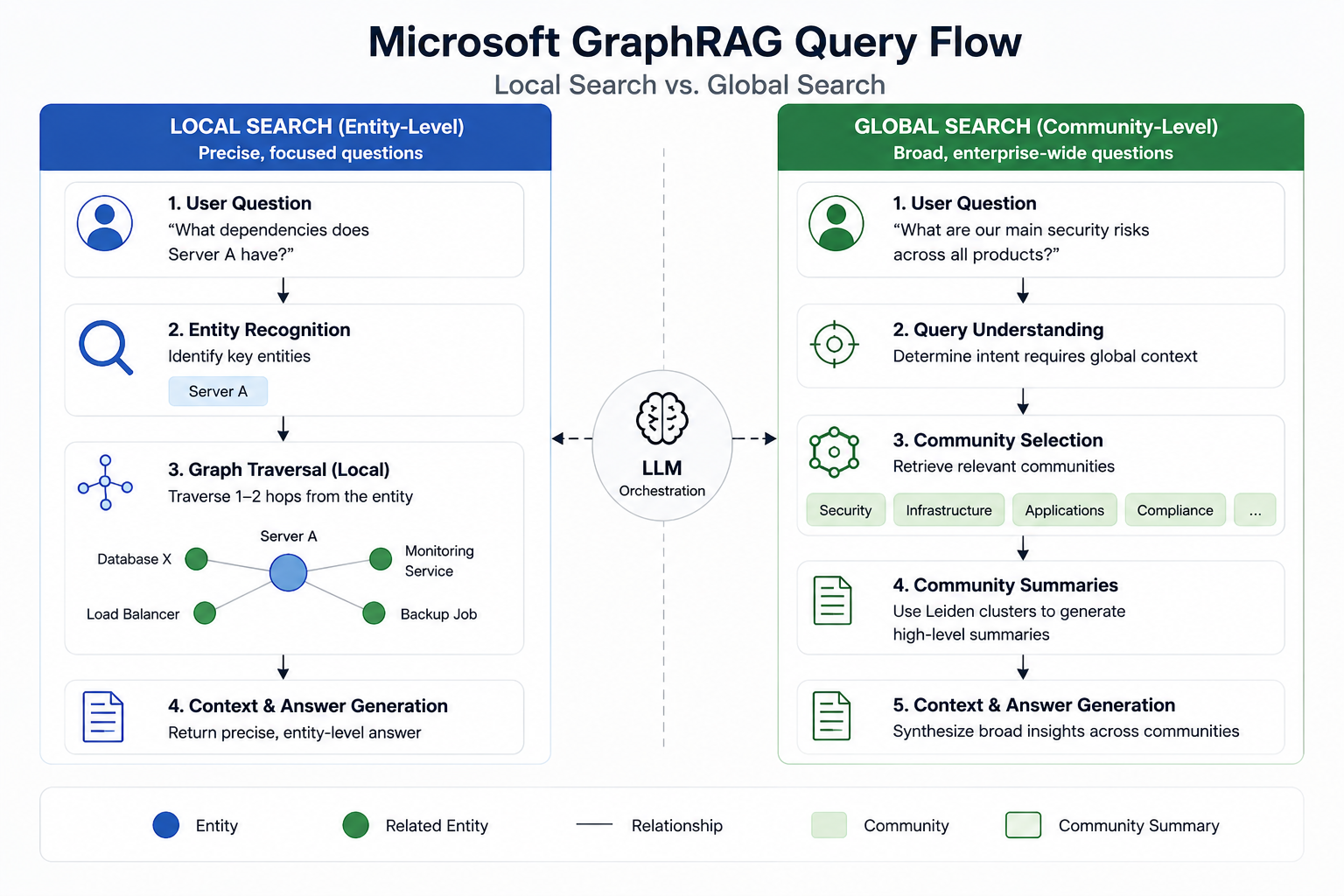
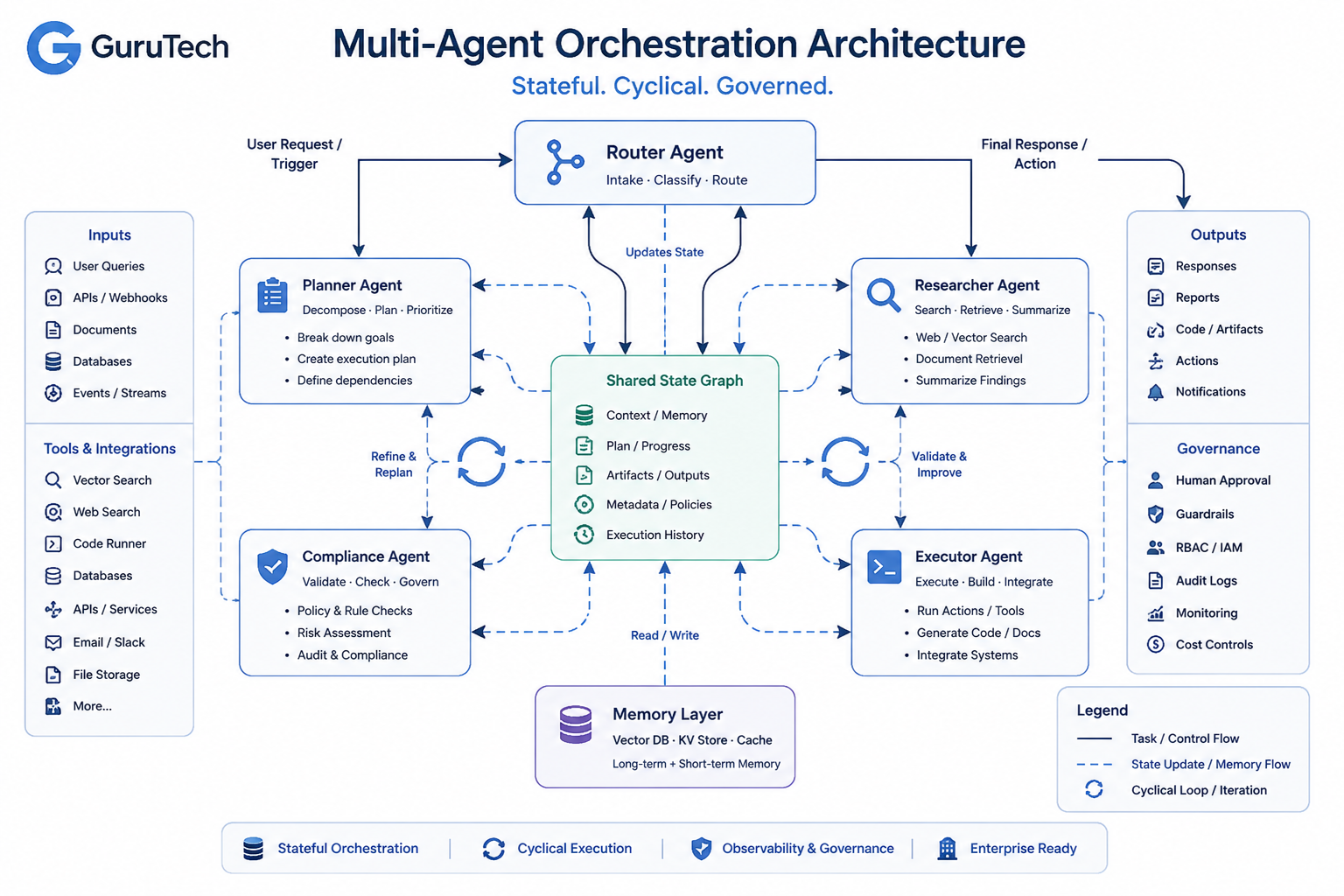
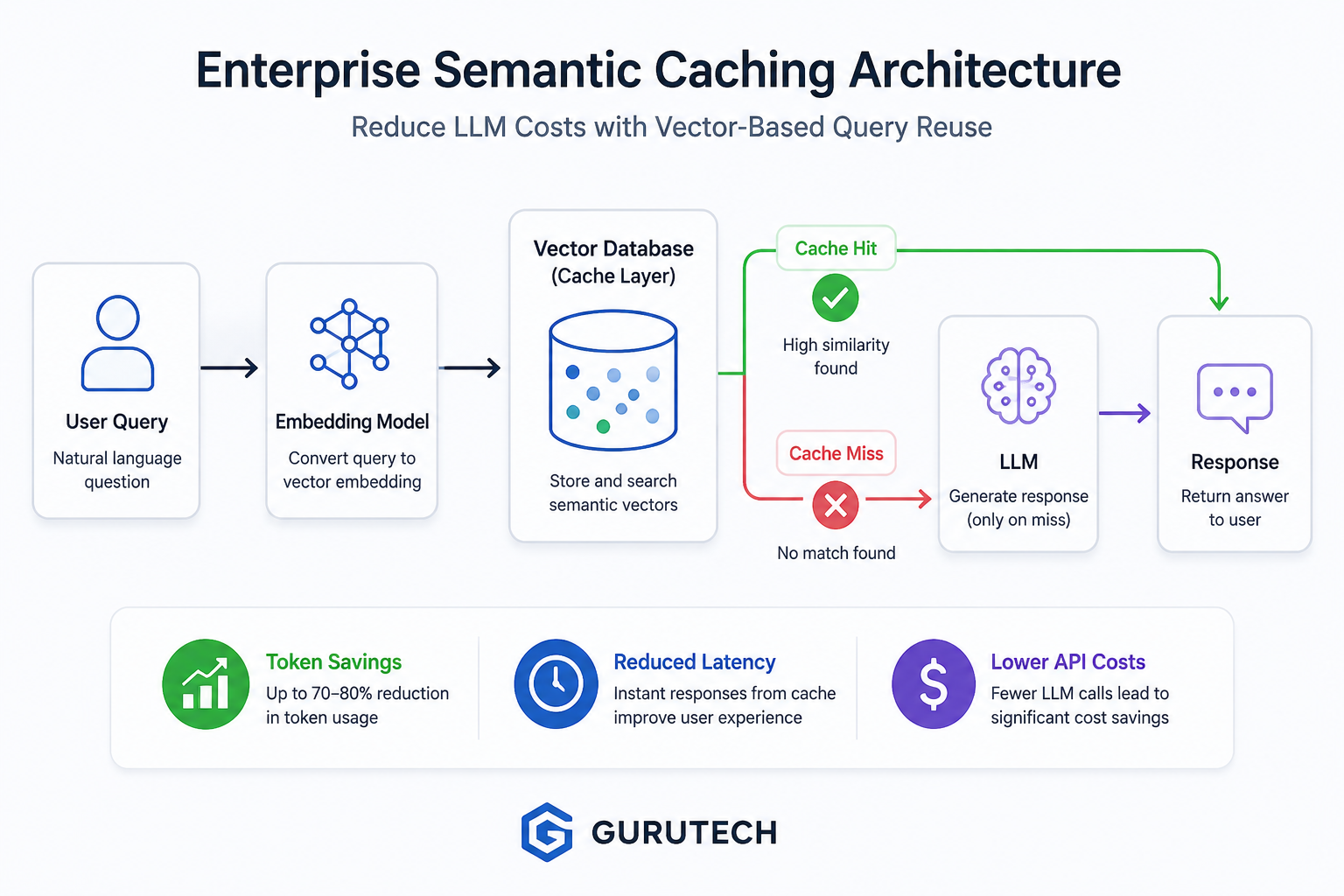
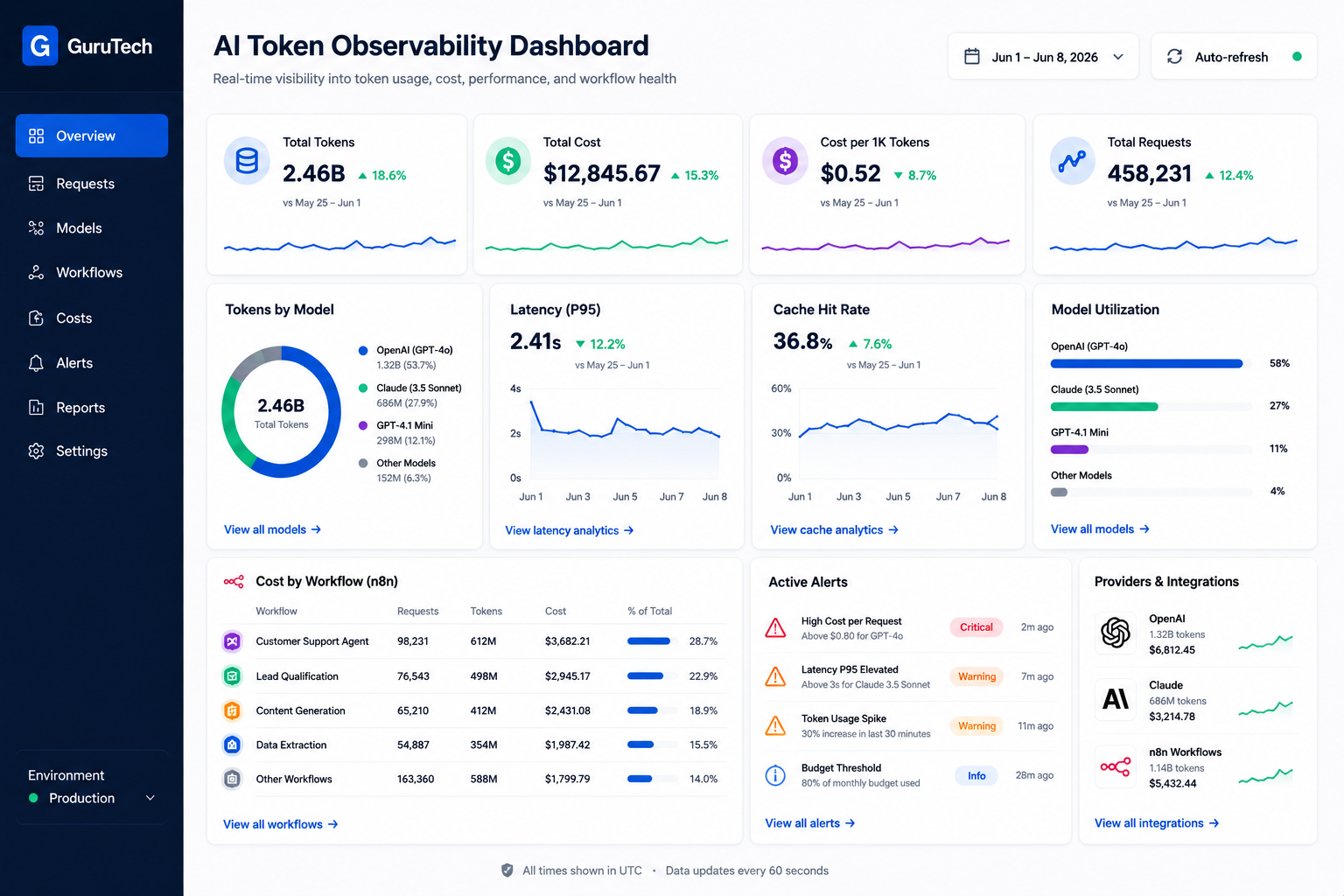
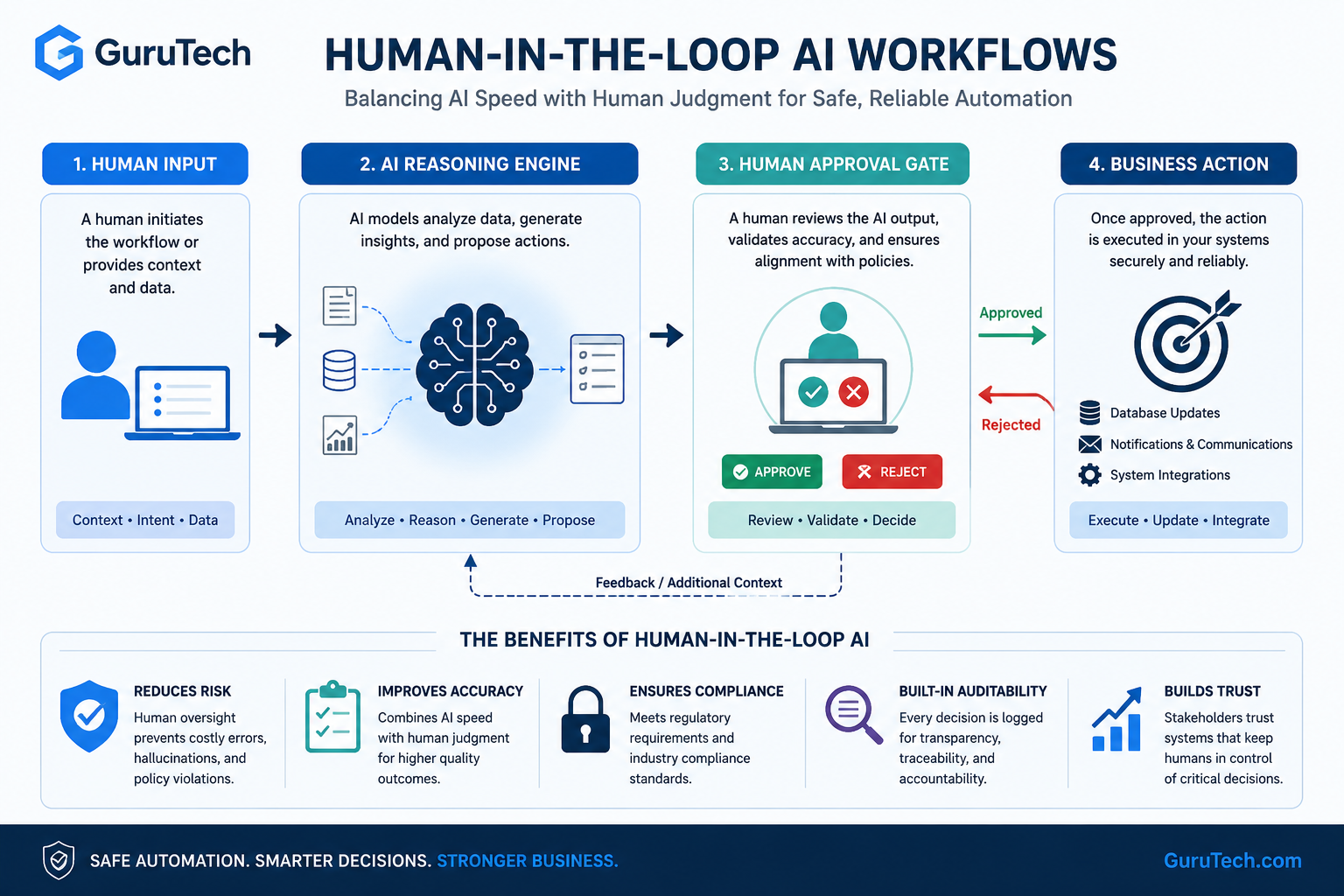
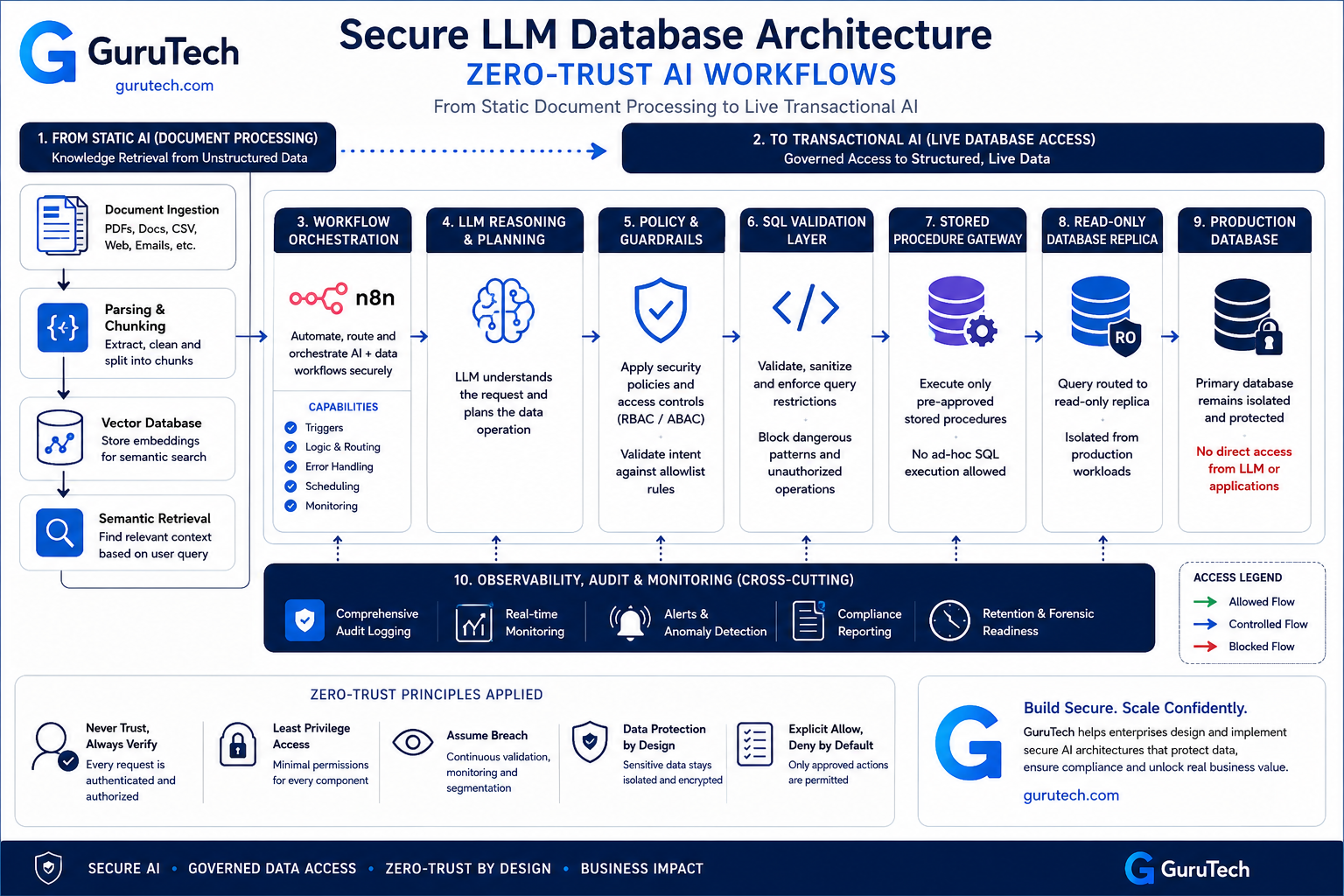
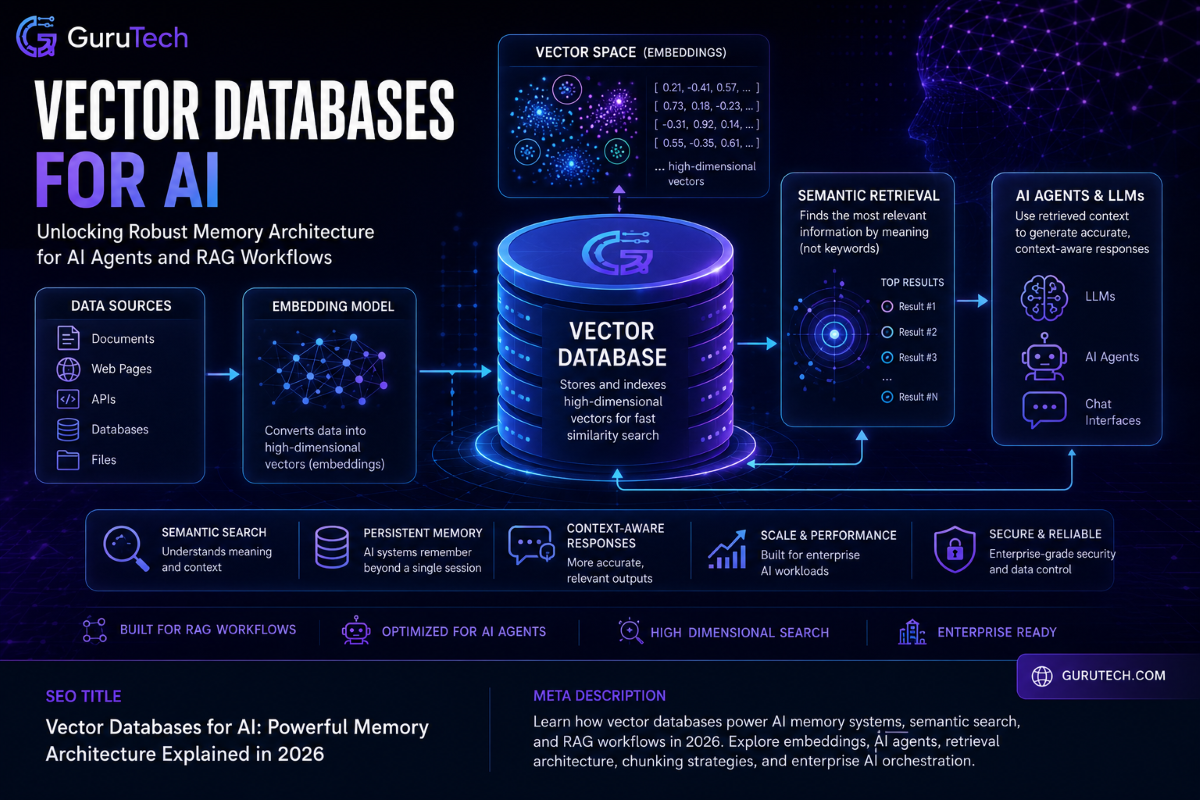
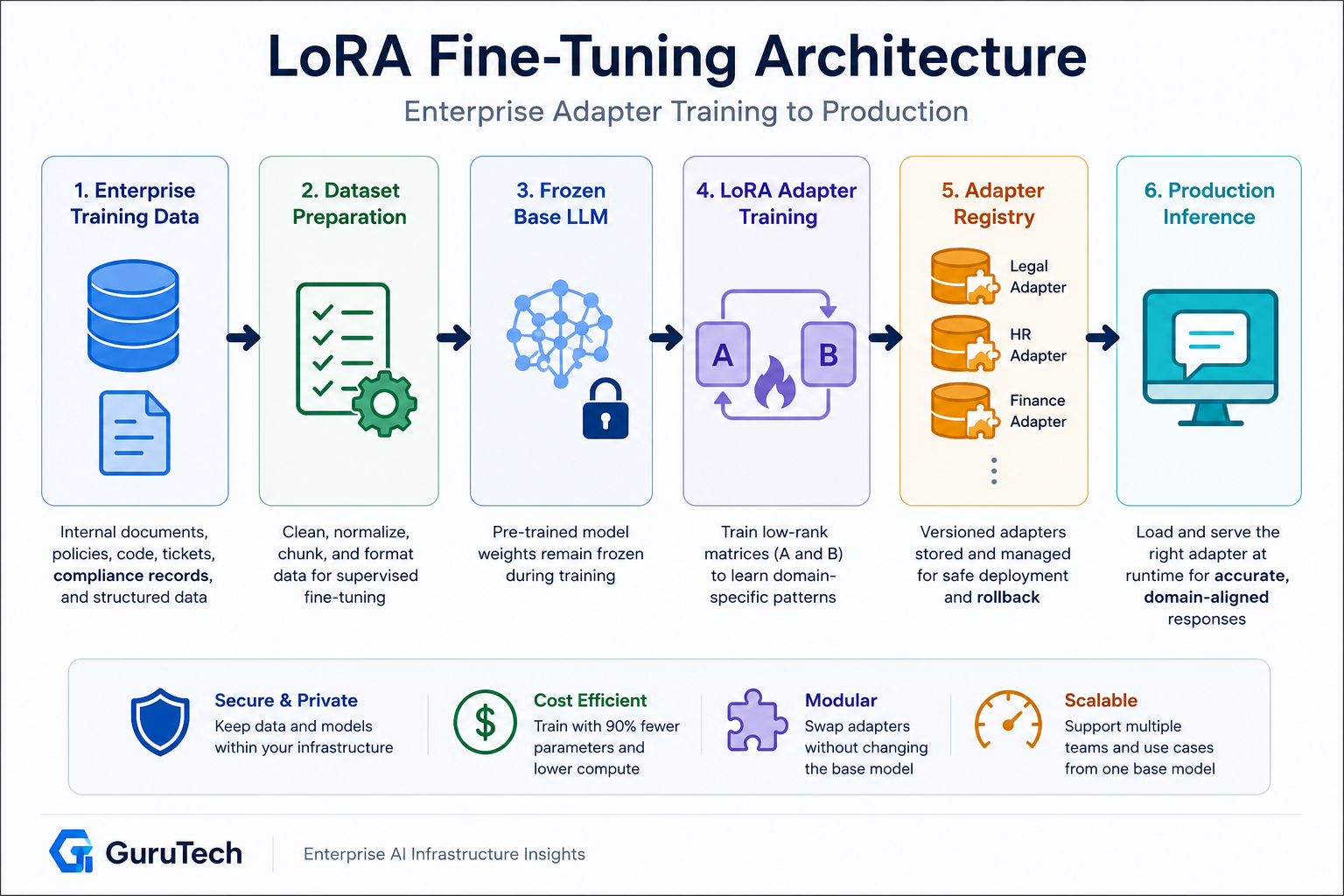
LoRA Fine Tuning Architectures: Advanced Guide to Enterprise AI Deployment
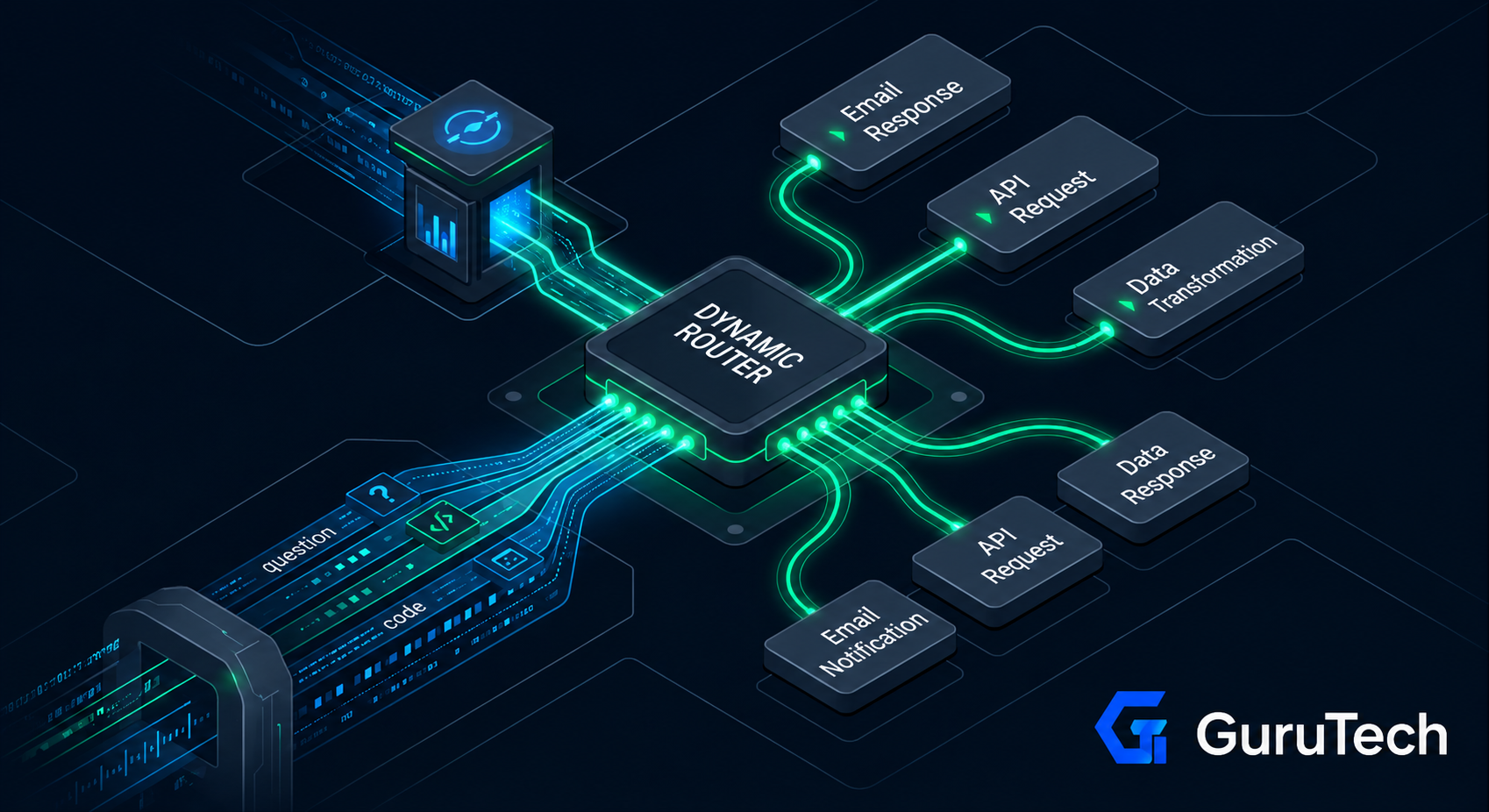
Many organizations successfully deploy Retrieval-Augmented Generation (RAG) for dynamic knowledge retrieval but eventually discover that retrieval alone cannot teach a model proprietary reasoning patterns, company-specific terminology, structured output formats, or internal coding conventions. RAG excels at surfacing relevant context from vector databases, yet the base model continues to generate responses using its pre-trained behavior rather … Read more