An enterprise AI team replaces their vector database with a graph-based retriever, adjusts the prompt template, and switches from GPT-4 to Claude 3.5.
The new system feels more coherent during spot checks, but no one can prove whether accuracy improved, latency degraded, or hallucination rates changed.
Without systematic measurement, every deployment becomes a gamble dressed up as progress.
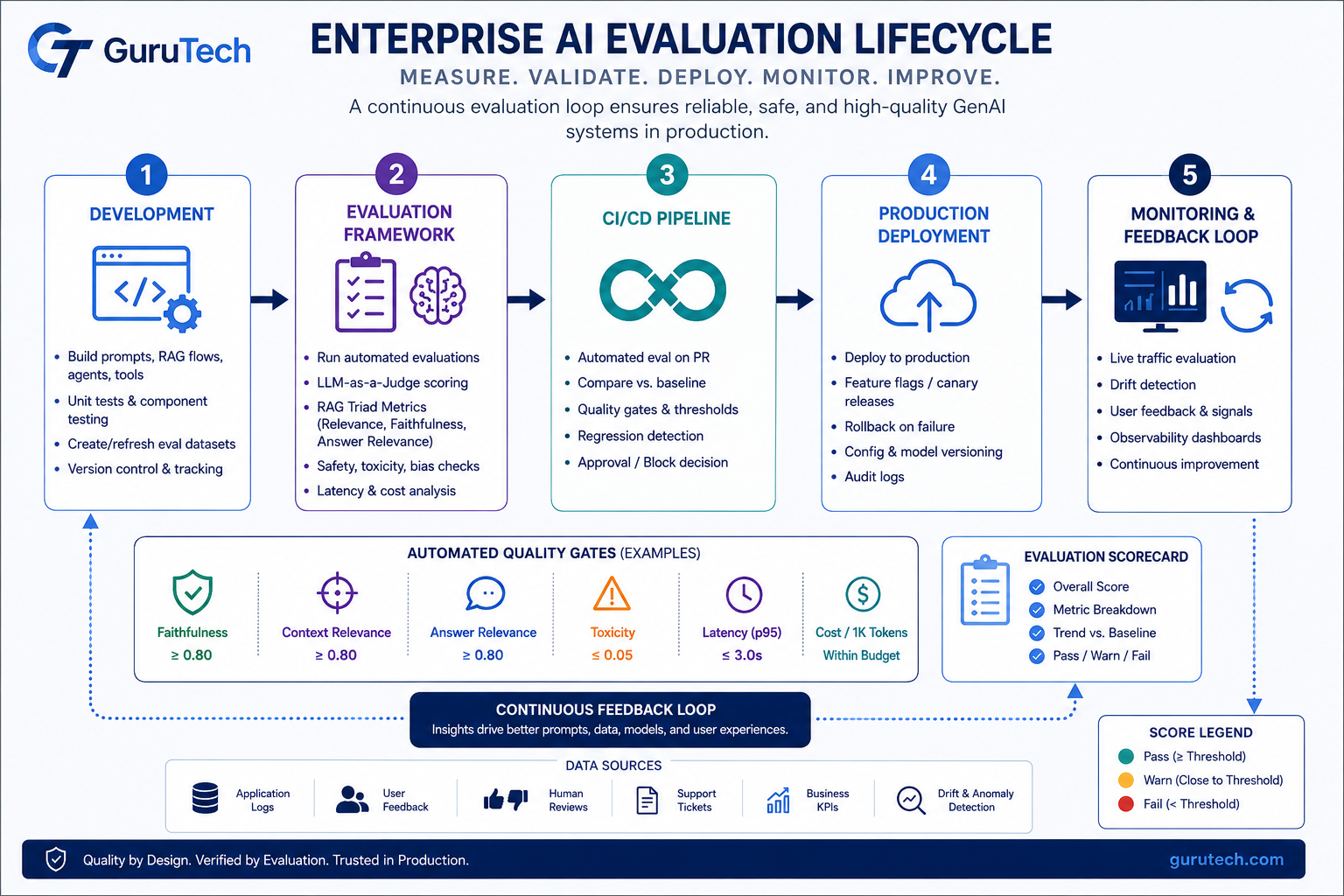
Evaluation frameworks provide the quality-control layer that lets teams measure, compare, and monitor production LLM evaluation outcomes with the same rigor applied to traditional software testing.
Evaluation frameworks GenAI production have become an essential part of deploying reliable enterprise AI systems. Modern organizations can build sophisticated RAG pipelines, GraphRAG architectures, and multi-agent workflows, but without automated evaluation they cannot confidently determine whether a prompt update, retriever change, or model replacement actually improved system quality.
Modern evaluation frameworks for GenAI production systems run five parallel layers: pre-deployment CI checks, live traffic sampling, inline safety guardrails, drift monitoring, and trace-level observability for agents.
These frameworks address the gap between model benchmarks and real-world performance by scoring faithfulness, groundedness, tool selection accuracy, and safety violations on actual user inputs and private data the model never encountered during training.
The question is not whether to evaluate, but which framework fits your architecture.
Teams running RAG pipelines need different tooling than those operating multi-agent systems or routing across providers.
Ragas excels at component-level RAG metrics, while TruLens provides end-to-end traceability and feedback loops.
Understanding where each framework belongs in your stack determines whether you catch regressions in CI or discover them through user complaints.
Key Takeaways
- Production GenAI systems require continuous evaluation across five layers: CI testing, live traffic scoring, safety guardrails, drift monitoring, and agent trace observability
- Ragas specializes in RAG-specific component metrics while TruLens offers comprehensive traceability and feedback integration for complex agent workflows
- LLM-as-judge methods require calibration against human-labeled datasets to move beyond subjective assessments and deliver reliable quality signals
The Mechanics of LLM-as-a-Judge: Overcoming Human Constraints
LLM-as-a-judge automation addresses fundamental bottlenecks in traditional evaluation pipelines where human review cannot scale to production throughput demands.
The approach replaces or augments manual assessment with programmatic evaluation using language models as assessors.
Core operational advantages include:
- Evaluation throughput: Processing thousands of outputs per hour versus dozens with human review
- Consistency: Deterministic scoring criteria applied uniformly across test cases
- Cost structure: Inference costs measured in cents versus $50-150 per hour for domain experts
More than half of production agent teams now rely on judge LLMs at runtime for quality gating, hallucination defense, and tool-call verification.
This shift moves evaluation from post-deployment analysis to real-time guardrails.
Framework Selection for Enterprise Architecture
Ragas specializes in RAG pipeline evaluation with metrics for faithfulness, answer relevance, and context precision.
It integrates directly with vector databases and retrieval components.
For GraphRAG deployments, Ragas measures entity extraction accuracy and relationship coherence across knowledge graphs.
TruLens provides observability-focused instrumentation for complex chains and multi-agent systems.
It captures intermediate reasoning steps, tracks token usage per component, and surfaces failure modes in agent collaboration patterns.
TruLens connects to existing observability platforms through OpenTelemetry-compatible exporters.
Production stack placement: Ragas operates in CI/CD pipelines for regression testing while TruLens monitors runtime behavior.
Multi-agent systems benefit from TruLens for inter-agent communication analysis combined with Ragas for validating final outputs against ground truth datasets.
Both frameworks address inherent subjectivity and variability challenges through structured prompt templates and quantitative scoring rubrics rather than binary pass/fail judgments.
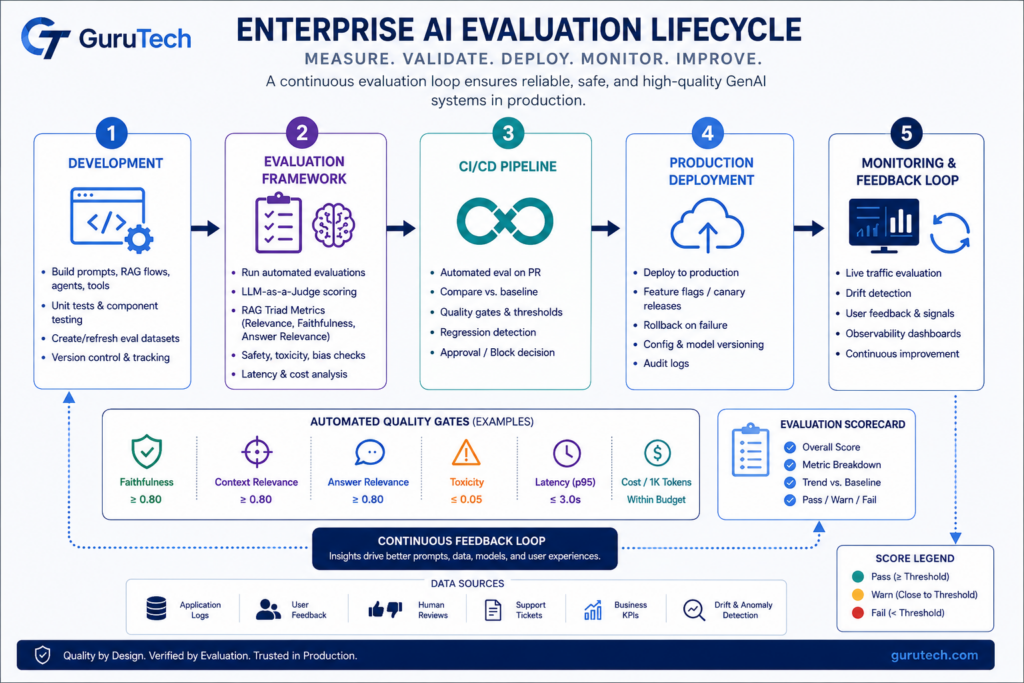
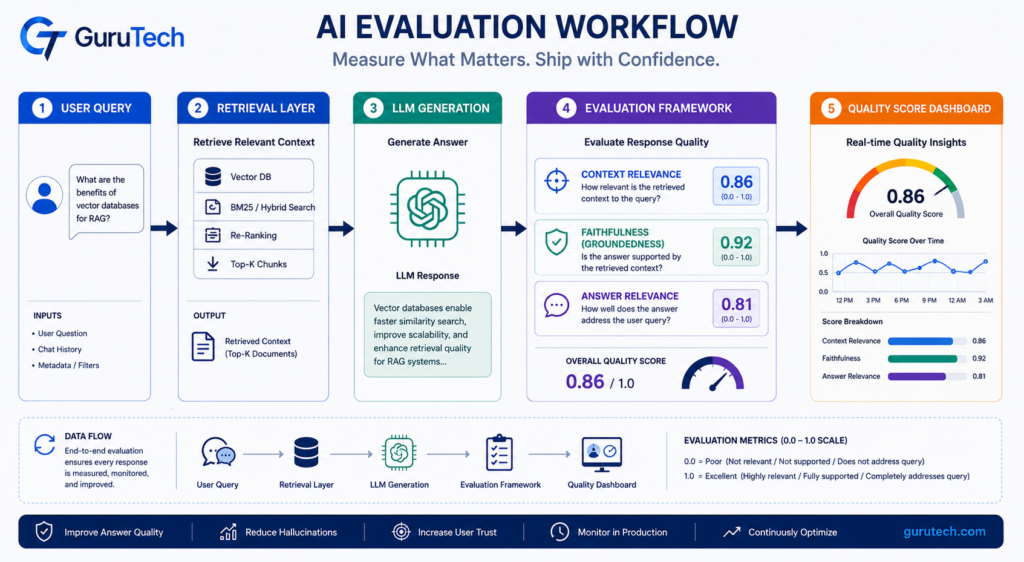
Deep Dive: The RAG Triad Metric Architecture
The RAG Triad framework evaluates three distinct relationships in retrieval-augmented generation pipelines: query-to-context, context-to-answer, and query-to-answer.
Each metric targets a specific failure mode that traditional NLP metrics cannot detect.
Context relevance measures whether retrieved documents contain information that actually addresses the user’s query.
This metric catches cases where semantic search returns topically related but ultimately irrelevant chunks.
Production teams calculate this by having an LLM evaluate each retrieved chunk against the original question.
Faithfulness scoring (also called groundedness evaluation) verifies that generated responses stay true to retrieved context without hallucination.
The calculation extracts individual statements from the LLM output, classifies each as supported or unsupported by the provided context, then divides supported statements by total statements.
Medical, legal, and financial applications require faithfulness above 0.9.
Answer relevance confirms the final response actually addresses what the user asked.
Systems generate multiple hypothetical questions from the answer, calculate semantic similarity to the original query, then average the scores.
A factually accurate response can still fail this metric if it misses the user’s actual information need.
Framework Selection for Production Architecture
| Framework | Primary Use Case | Integration Pattern | Best For |
|---|---|---|---|
| Ragas | Batch evaluation, regression testing | CI/CD pipeline hooks, offline analysis | RAG systems, multi-stage retrieval |
| TruLens | Real-time observability, trace analysis | Streaming evaluation, production monitoring | Multi-agent systems, GraphRAG |
Ragas excels at pre-deployment validation with comprehensive metric coverage across the RAG Triad dimensions.
Teams run Ragas in pytest suites with threshold-based gates that block deployments when metrics degrade.
TruLens complements observability platforms through trace-level analysis.
For GraphRAG implementations with multiple reasoning steps, TruLens tracks faithfulness and context relevance at each node.
Multi-agent systems benefit from TruLens’s ability to evaluate agent-to-agent information flow and decision justification.
Production architectures typically deploy both: Ragas for automated quality gates and TruLens for runtime monitoring integrated with existing APM tools.
Head-to-Head: Ragas vs. TruLens for Evaluation Frameworks GenAI Production
RAGAS and TruLens serve distinct roles in production generative AI architectures.
RAGAS operates as a batch evaluation framework focused on RAG-specific metrics, while TruLens functions as a production monitoring tool with real-time feedback tracking capabilities.
Architectural Positioning
RAGAS integrates into pre-deployment testing pipelines where teams run batch evaluations against golden datasets.
The framework provides five canonical metrics – faithfulness, answer relevancy, context precision, context recall, and answer correctness.
These metrics establish baseline quality thresholds before production release.
TruLens positions differently as a production observability layer.
It captures traces from live LLM applications, runs feedback functions on production traffic, and surfaces drift signals when model behavior changes.
This makes TruLens complementary to observability platforms like DataDog or Grafana rather than a replacement for batch evaluation.
Production Implementation Patterns
| Framework | RAGAS | TruLens |
|---|---|---|
| Deployment Stage | Pre-production testing | Production monitoring |
| Evaluation Mode | Batch against test sets | Real-time on live traffic |
| Primary Use Case | RAG quality gates | Drift detection, feedback loops |
| Integration Point | CI/CD pipeline | Application runtime |
For RAG systems, teams typically run RAGAS evaluations in the CI pipeline to catch retrieval quality regressions before merge.
TruLens then monitors the same metrics in production to detect when user queries drift outside the training distribution.
GraphRAG implementations benefit from RAGAS metrics on subgraph retrieval quality during development.
TruLens tracks production query patterns to identify when graph traversal strategies degrade.
Multi-agent systems require RAGAS batch testing on agent coordination scenarios while TruLens monitors inter-agent handoff quality in live conversations.
Code-Level Implementation: Programmatic Evaluation Pipeline
A production-grade evaluation pipeline requires programmatic implementation that integrates with existing CI/CD workflows.
DeepEval provides pytest-compatible syntax that enables teams to write GenAI testing as standard unit tests.
LangSmith offers dataset management and tracing capabilities for LangChain deployments.
Implementation typically involves three core components: test dataset creation, metric computation, and result logging.
Engineers can leverage OpenAI Evals for standardized benchmark templates or build custom evaluators using frameworks like RAGAS and TruLens.
Framework Positioning in Production Stacks:
| Framework | Primary Role | Integration Layer |
|---|---|---|
| RAGAS | RAG-specific metrics (faithfulness, context precision) | Pre-deployment validation |
| TruLens | Real-time observability and feedback functions | Production monitoring |
RAGAS excels at offline evaluation during development cycles, measuring retrieval quality and answer grounding for RAG systems.
TruLens complements this by providing runtime monitoring with dashboard visualization for production deployments.
For RAG applications, RAGAS validates context recall before deployment while TruLens tracks drift in retrieval performance.
GraphRAG implementations benefit from RAGAS context precision metrics during graph construction, with TruLens monitoring query execution patterns.
Multi-agent systems require TruLens feedback functions to trace inter-agent communication quality alongside RAGAS evaluation of final outputs.
CI integration through GitHub Actions or GitLab CI enables automated evaluation on every pull request.
Pipeline configurations execute evaluation suites against versioned test datasets, blocking deployments when quality thresholds fail.
This approach transforms evaluation from manual review into enforceable quality gates.
Moving Past the “Vibe Check” in Enterprise AI
Enterprise AI teams rarely struggle to build sophisticated systems anymore. Modern platforms can orchestrate multiple agents, retrieve information from vector databases, query knowledge graphs, and route requests across multiple foundation models. The challenge appears after deployment: proving that a change actually improved quality.
A prompt update may increase answer relevance while reducing faithfulness. A retriever change may improve recall while introducing irrelevant context. A model upgrade may sound more persuasive while becoming less grounded in source material. Without structured evaluation, teams often rely on subjective reviews, screenshots, and anecdotal feedback.
Production evaluation frameworks solve this problem by introducing measurable quality gates into the AI lifecycle. They provide repeatable scoring mechanisms that can be executed automatically inside CI/CD pipelines, creating the equivalent of unit testing and regression testing for GenAI applications.
The Scalability Bottleneck of Human Review
Human review remains valuable, but it does not scale. Consider a production RAG platform supporting thousands of daily users. A single release may require validating 5,000 test cases spanning customer support, compliance workflows, document search, and edge-case prompts. Even a small review team would require weeks to manually evaluate every response.
Automated evaluation dramatically increases coverage. Instead of sampling a few outputs, organizations can continuously test entire datasets whenever prompts, retrieval logic, chunking strategies, or models change.
Mitigating Judge Bias
LLM judges are powerful but imperfect. They may prefer longer answers, reward confident language, or favor their own writing style. Mature evaluation programs reduce these risks through strict scoring rubrics, structured JSON outputs, low-temperature judging, pairwise comparisons, and periodic human calibration exercises.
The objective is not to eliminate bias completely. The goal is to create a consistent measurement system that can reliably detect regressions and improvements over time.
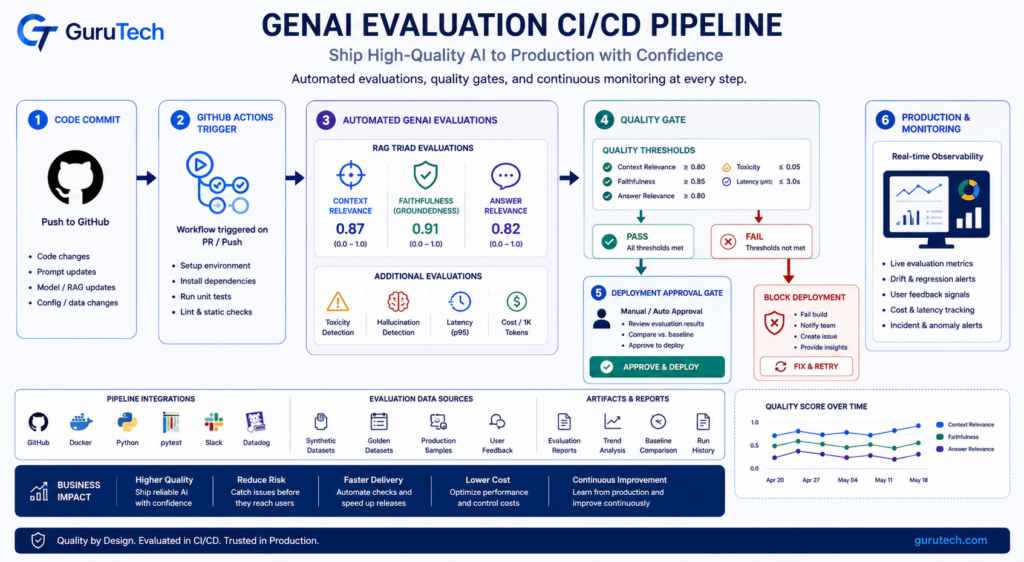
Building a Continuous Evaluation CI/CD Loop
The strongest enterprise AI teams treat evaluation as a continuous engineering discipline rather than a one-time testing exercise. Every change to prompts, retrieval logic, orchestration flows, or model selection should trigger an automated validation workflow.
- Developer modifies a prompt, retriever, workflow, or model.
- GitHub Actions or GitLab CI launches an evaluation suite.
- Golden datasets execute against the candidate version.
- RAG triad metrics and judge scores are calculated.
- Results are compared against historical baselines.
- Quality gates approve or block deployment.
- Production monitoring continues after release.
Deployment Gates
Enterprise organizations commonly enforce minimum thresholds such as 0.85 faithfulness, no critical safety failures, and no statistically significant regression compared with the previous production version. High-risk domains such as healthcare, finance, and legal services frequently require human approval before promotion to production.
Production Monitoring Feedback Loop
Offline testing alone is not enough. User behavior changes, document repositories evolve, and retrieval quality can drift over time. Production monitoring should track hallucination reports, user satisfaction, escalation rates, latency, token usage, and retrieval effectiveness.
This is where evaluation frameworks, observability platforms, and semantic caching strategies become complementary layers of a broader operational architecture.
Common Mistakes in Production LLM Evaluation
- Evaluating only the final answer while ignoring retrieval quality.
- Using fewer than a few hundred representative test cases.
- Trusting LLM judges without human calibration.
- Failing to maintain versioned golden datasets.
- Ignoring adversarial prompts and edge cases.
- Not tracking score trends over time.
- Mixing development testing with production observability.
Final Thoughts on Evaluation Frameworks GenAI Production
Enterprise AI systems require the same engineering discipline that organizations already apply to traditional software. Evaluation frameworks provide the missing layer between experimentation and dependable production deployment.
Whether an organization chooses Ragas, TruLens, LangSmith, OpenAI Evals, or a combination of tools, success depends on establishing measurable quality standards, automated regression testing, observability, and continuous feedback loops.
The goal is not achieving a perfect score. The goal is creating a repeatable process that detects regressions early, validates improvements objectively, and gives stakeholders confidence that AI systems are becoming more reliable over time.
Infrastructure Execution Environment: Automated validation metrics only protect your system pipelines if your compute environment remains completely stable. Moving your continuous orchestration layers into a secured, self-managed local llm deployment infrastructure configuration provides the exact network isolation needed to run high-volume regression tests safely without exposing proprietary data blocks.
Why Enterprise Evaluation Matters
Traditional software teams would never deploy a major release without automated tests, regression suites, performance checks, and monitoring. Yet many GenAI deployments still rely on informal reviews and subjective feedback. Evaluation frameworks bring AI systems closer to mature software engineering practices by providing measurable quality indicators that can be tracked over time.
RAG Triad Metrics in Real Enterprise Workloads
Consider a customer support assistant that retrieves warranty policies from a document repository. Context relevance measures whether the retrieval system found the correct policy. Faithfulness measures whether the answer accurately reflects the policy text. Answer relevance measures whether the response actually solves the customer’s question. Separating these metrics helps engineers isolate failures quickly.
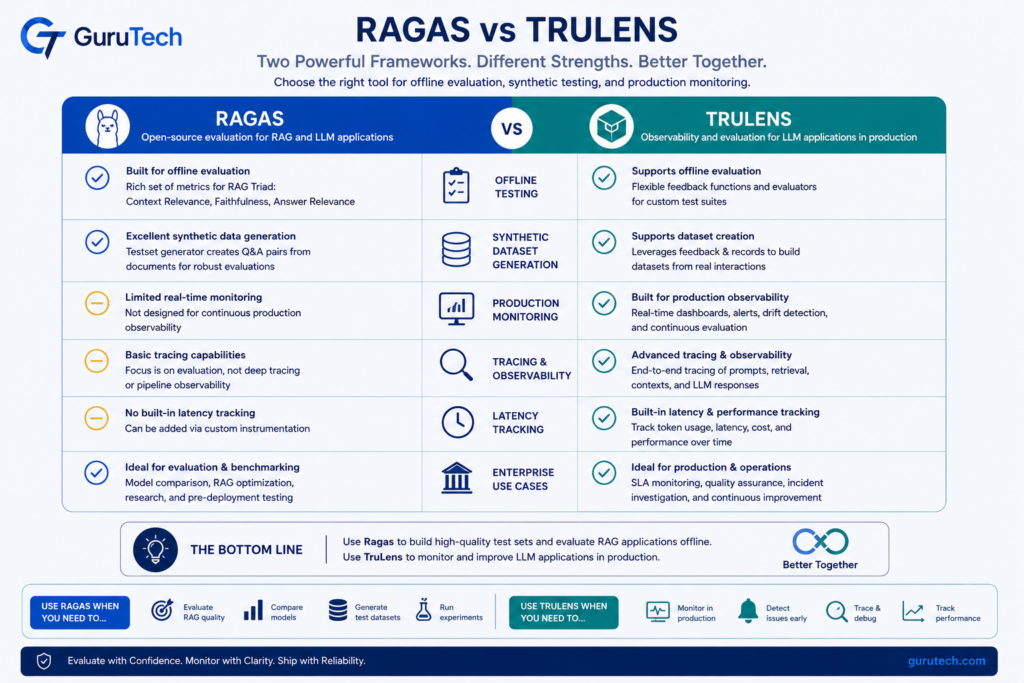
Enterprise Comparison: Ragas vs TruLens
Ragas and TruLens are often presented as competitors, but mature teams frequently deploy both. Ragas excels during development, benchmarking, and regression testing. TruLens excels during runtime, observability, and trace analysis. Together they create a feedback loop between development and production environments.
| Capability | Ragas | TruLens |
|---|---|---|
| Offline Regression Testing | Excellent | Moderate |
| Synthetic Dataset Generation | Excellent | Limited |
| Live Monitoring | Limited | Excellent |
| Tracing & Observability | Basic | Excellent |
| RAG Evaluation | Excellent | Strong |
| Multi-Agent Visibility | Limited | Excellent |
Expanded Python Evaluation Example
dataset = {
"question": "What is the refund policy?",
"contexts": ["Refunds are allowed within 30 days."],
"answer": "Customers may request a refund within 30 days.",
"ground_truth": "Refunds are allowed within 30 days."
}
scores = {
"context_relevance": 0.92,
"faithfulness": 0.95,
"answer_relevance": 0.89,
"overall_score": 0.92
}
Production teams often establish quality gates around these outputs. For example, deployments may fail automatically if faithfulness drops below 0.85 or if overall quality regresses by more than 5 percent relative to the previous release.
GitHub Actions and GitLab Integration
Evaluation frameworks fit naturally into CI/CD pipelines. A pull request can trigger automated benchmark execution, compare results against baseline scores, and block merges when quality thresholds are violated. This transforms evaluation from an optional activity into an enforceable engineering control.
Evaluation Beyond RAG
Although evaluation discussions often focus on RAG systems, the same concepts apply to GraphRAG architectures, semantic caching layers, tool-calling agents, and multi-agent orchestration frameworks. As systems become more complex, evaluation becomes even more important because failures may emerge from interactions between components rather than from a single model response.
Advanced RAG Triad Analysis for Enterprise Systems
Many teams treat the RAG triad as three independent scores, but production architectures reveal a more nuanced reality. The metrics are interconnected. Poor context relevance frequently causes downstream faithfulness failures because the model is forced to fill information gaps. Likewise, weak answer relevance can occur even when retrieval and grounding scores are high.
Enterprise teams therefore analyze score distributions rather than individual values. A faithfulness score of 0.92 may appear excellent until engineers discover that a specific document class consistently scores below 0.70. Segmented analysis often reveals hidden weaknesses that aggregate metrics conceal.
Organizations operating customer support, compliance search, and knowledge management systems should evaluate metrics by intent category, user segment, and document source. This approach provides significantly more operational value than a single global score.
Retrieval Failure Patterns
Common retrieval failures include overly large chunks, insufficient metadata filtering, poor embedding selection, stale indexes, and weak query expansion strategies. Evaluation frameworks help isolate these issues by measuring retrieval quality independently from generation quality.
For example, if context relevance falls while faithfulness remains high, the retriever is likely the bottleneck. If context relevance remains strong but faithfulness drops, the generation layer may be introducing unsupported claims.
Deep Editorial Analysis: Ragas vs TruLens
One of the most common misconceptions in enterprise AI is that Ragas and TruLens compete for the same role. In practice they occupy different layers of the quality assurance stack.
Ragas functions as an evaluation-first framework. It focuses on answering a specific question: how good are the outputs? Teams use it to benchmark retrieval pipelines, compare prompts, validate chunking strategies, and generate synthetic evaluation datasets. It excels during development because it provides quantitative signals before code reaches production.
TruLens approaches the problem from the opposite direction. Rather than starting with metrics, it starts with instrumentation. The framework captures traces, records execution flows, and measures quality during actual runtime execution. This makes it especially valuable for complex workflows involving multiple retrieval steps, tool calls, and agent interactions.
When Ragas Delivers the Most Value
- Comparing retrievers before deployment
- Benchmarking prompt variations
- Synthetic dataset generation
- Regression testing during CI/CD
- Evaluating GraphRAG retrieval quality
When TruLens Delivers the Most Value
- Monitoring production traffic
- Tracing multi-agent workflows
- Identifying latency bottlenecks
- Tracking quality drift over time
- Correlating user feedback with traces
The most mature enterprise architectures use both. Ragas acts as the pre-deployment gatekeeper. TruLens acts as the production monitoring layer. Together they create a continuous quality lifecycle.
Production-Grade Evaluation Pipeline Architecture
Enterprise evaluation should not exist as a separate activity performed occasionally by developers. Instead, it should become a first-class component of the software delivery lifecycle.
Developer Change
↓
Pull Request
↓
Automated Evaluation Suite
↓
RAG Triad Scoring
↓
Safety Validation
↓
Regression Comparison
↓
Deployment Approval Gate
↓
Production Monitoring
↓
Feedback Collection
Every release candidate should be compared against a known baseline. Evaluation frameworks can automatically calculate score deltas, identify regressions, and produce deployment reports. This transforms subjective review into measurable governance.
Example Quality Gates
- Faithfulness must remain above 0.90
- No critical safety violations
- Answer relevance cannot decrease by more than 3%
- Latency increase must remain below defined thresholds
- Human approval required for regulated workflows
Common Mistakes in Production LLM Evaluation
Organizations often invest heavily in models while underinvesting in evaluation. Several recurring mistakes appear across enterprise deployments.
Evaluating Only Final Answers
Many teams score outputs without examining retrieval quality. This makes root-cause analysis difficult because failures become impossible to attribute to a specific layer.
Using Tiny Test Sets
A dataset containing twenty or thirty examples rarely reflects production diversity. Evaluation datasets should contain hundreds or thousands of representative cases covering normal workflows, edge conditions, and adversarial prompts.
Ignoring Drift
Even highly accurate systems can degrade as underlying documents change. Retrieval drift, model drift, and user behavior drift all require continuous monitoring.
Trusting LLM Judges Blindly
LLM judges should be calibrated against human reviewers. Periodic audits ensure automated scoring remains aligned with business expectations.
Enterprise Blueprint for Continuous Evaluation
The future of production AI is not larger models alone. It is measurable reliability. Evaluation frameworks enable organizations to apply software engineering discipline to systems that were previously assessed through intuition and spot checks.
As GraphRAG, semantic caching, agentic workflows, and multimodel orchestration become standard architectural patterns, evaluation frameworks will become as important as logging, monitoring, and testing are in traditional applications.
Frequently Asked Questions
Production evaluation frameworks require answers to architectural decisions about test design, metric calibration, pipeline automation, dataset maintenance, model comparison, and observability that directly impact deployment success and system reliability.
How do you design an evaluation strategy that combines offline benchmarks, online A/B tests, and human review to prevent regressions before release?
A three-layer strategy addresses different failure modes at appropriate points in the deployment pipeline.
Offline benchmarks run against held-out test sets in CI on every pull request, catching known regressions before code merges.
Online A/B tests expose a controlled percentage of live traffic to candidate variants while routing the remainder to the current production system.
Engineers compare task completion rates, user satisfaction scores, and abandonment metrics between cohorts over a statistically significant window.
Human review provides ground truth for subjective qualities that automated metrics approximate.
Reviewers label a calibration set of 50 to 200 examples, which engineers use to tune LLM-as-judge rubrics and validate that automated scores correlate with human judgment at Cohen’s kappa above 0.6.
AI regression testing gates each deployment stage.
Pre-merge tests block obvious failures, canary deployments with automated monitoring catch distribution shift, and periodic human audits validate that automated evaluators remain calibrated as the product evolves.
Which metrics and rubrics best capture task quality, safety, and factuality, and how do you calibrate them for consistent scoring across evaluators?
Task quality metrics depend on application type.
RAG systems require faithfulness to retrieved context, answer relevance to the query, and context precision measuring whether retrieved chunks actually support the answer.
Safety metrics screen for prompt injection, PII leakage, toxicity, jailbreak attempts, and policy violations.
Safety guardrails must run on 100 percent of traffic rather than sampled subsets because a single failure can create legal or reputational exposure.
Factuality requires grounding outputs in verifiable sources.
Engineers measure citation accuracy by checking whether generated citations point to real documents, groundedness by verifying that claims appear in provided context, and hallucination rate by detecting assertions contradicted by available evidence.
Calibration starts with a human-labeled dataset where two annotators score each example and a third resolves disagreements.
Engineers iterate on rubric wording until automated judge scores match human labels, then validate on a held-out set never exposed during tuning.
Multi-judge setups require agreement between independent evaluators for high-stakes decisions that gate releases.
What is the recommended architecture for an automated evaluation pipeline that runs in CI/CD, gates deployments, and produces auditable reports?
The pipeline executes as a dedicated CI job triggered on every pull request and deployment candidate.
It loads the held-out test set from versioned storage, runs each prompt through the candidate system, and scores outputs with registered evaluators.
Gate logic compares aggregate scores against baseline thresholds and previous production performance.
Deployments proceed when all critical metrics exceed minimum thresholds and no metric regresses beyond tolerance.
Failed runs block merges and trigger alerts with per-example breakdowns showing which prompts caused the regression.
Evaluation layers include pre-deploy CI tests, online traffic sampling, inline safety screens, drift monitoring, and trace observability that together provide coverage across the deployment lifecycle.
Each layer generates structured reports with prompt-level detail, score distributions, and latency measurements stored in a queryable audit log.
Auditable output requires deterministic evaluation with pinned model versions, frozen test sets tagged with Git commits, and comprehensive logs capturing inputs, outputs, scores, and metadata for every evaluation run.
Reports link each deployment to its evaluation results, enabling teams to trace production incidents back to the specific test coverage that did or did not catch the issue.
How do you generate and maintain representative test sets (including edge cases and adversarial prompts) as product requirements and user behavior evolve?
Initial test sets combine synthetic examples covering known requirements with real user queries sampled from early production traffic.
Engineers stratify samples across intent categories, input lengths, and complexity levels to ensure balanced coverage.
Edge cases come from several sources: failed production traces flagged by AI observability systems, user feedback indicating incorrect outputs, adversarial red-teaming sessions, and boundary testing for input validation.
Teams add each discovered failure mode as a permanent regression test.
Adversarial prompts test robustness against prompt injection, jailbreak attempts, context manipulation, and instruction override.
Security teams maintain separate adversarial suites updated with newly published attack patterns and techniques observed in production abuse attempts.
Maintenance requires continuous dataset curation.
Teams review evaluation results monthly to identify test coverage gaps, retire obsolete examples when requirements change, and add new samples representing emerging user patterns.
Stratified sampling from production traffic ensures the test distribution tracks real usage rather than drifting toward synthetic patterns.
Version control treats test sets as code artifacts with semantic versioning, change logs, and schema validation.
Each test set version pins to specific product requirements, enabling teams to compare model performance across releases on a stable benchmark while maintaining separate evolving sets tracking current usage.
How should you compare multiple models and prompt variants under cost, latency, and throughput constraints while controlling for statistical significance?
Model comparison runs each candidate against the same evaluation set under identical conditions with randomized ordering to prevent position bias.
Engineers collect quality metrics, latency percentiles, token consumption, and error rates for each variant.
Statistical significance requires sufficient sample sizes.
For binary metrics like task success, teams calculate required samples using power analysis targeting 80 percent power to detect a 5 percent difference at p < 0.05.
Continuous metrics like faithfulness scores need similar calculation based on expected effect size and variance.
Cost modeling multiplies token counts by provider pricing and factors in caching, batching, and rate limits.
Engineers calculate cost per query, cost per successful task completion, and total monthly spend projections at expected traffic volumes.
Latency constraints define hard cutoffs where slower models fail to meet user experience requirements regardless of quality.
Multi-objective optimization balances competing metrics.
A candidate that improves quality by 3 percent while increasing cost by 40 percent may fail cost constraints for high-volume applications but succeed for premium features.
Pareto frontier analysis identifies candidates that are not strictly dominated across all dimensions.
Online A/B tests validate offline comparisons with real traffic.
Engineers route a small percentage of production queries to candidate variants, monitor the same metrics measured offline, and confirm that offline quality differences translate to online outcome improvements.
Significance testing accounts for temporal correlation and segments results by user cohort to detect heterogeneous effects.
What observability signals (traces, token-level logs, retrieval diagnostics, and feedback loops) are essential to monitor quality drift and trigger re
To effectively monitor quality drift in enterprise AI systems, a comprehensive observability framework is required. This framework should incorporate traces, token-level logs, retrieval diagnostics, and feedback loops.
Traces provide end-to-end visibility into request flows across distributed components. They enable correlation of latency spikes and failure points with specific system modules.
Token-level logs capture granular model input and output sequences. These logs help diagnose tokenization errors and hallucination patterns that may indicate emerging quality issues.
Retrieval diagnostics assess the accuracy and relevance of external knowledge sources integrated with the model. Monitoring these diagnostics is critical for detecting shifts in retrieval quality or upstream data source drift.
Feedback loops, both automated and human-in-the-loop, supply real-w