Most enterprises deploying Retrieval-Augmented Generation systems quickly discover that vector search alone cannot handle complex organizational knowledge.
GraphRAG architecture for enterprise AI combines knowledge graphs with vector embeddings to enable multi-hop reasoning, relationship-aware retrieval, and hierarchical query strategies that traditional semantic similarity approaches cannot achieve.
Microsoft’s GraphRAG implementation represents a production-grade reference architecture that extracts entity relationships, applies Leiden clustering for community detection, and supports both global and local retrieval patterns across enterprise knowledge bases.
The architectural decision between vector-only RAG and graph-enhanced retrieval hinges on query complexity, relationship density, and reasoning requirements.
While cosine similarity over vector embeddings handles simple semantic search effectively, GraphRAG addresses enterprise gaps by modeling explicit entity connections and hierarchical summaries.
Production implementations must balance token consumption during graph construction, infrastructure overhead for graph stores like Neo4j or AWS Neptune, and maintenance costs associated with graph drift as source documents evolve.
Building enterprise GraphRAG systems requires integration of extraction pipelines, hybrid retrieval orchestration, and observability frameworks that track both vector index performance and graph traversal efficiency.
LlamaIndex workflows provide abstraction layers for combining vector similarity with graph-based context, while semantic caching reduces redundant LLM calls during entity extraction and summarization phases.
Organizations must evaluate security implications of exposing relationship data, governance requirements for knowledge provenance, and multi-agent coordination patterns when graph exploration spans multiple reasoning steps.
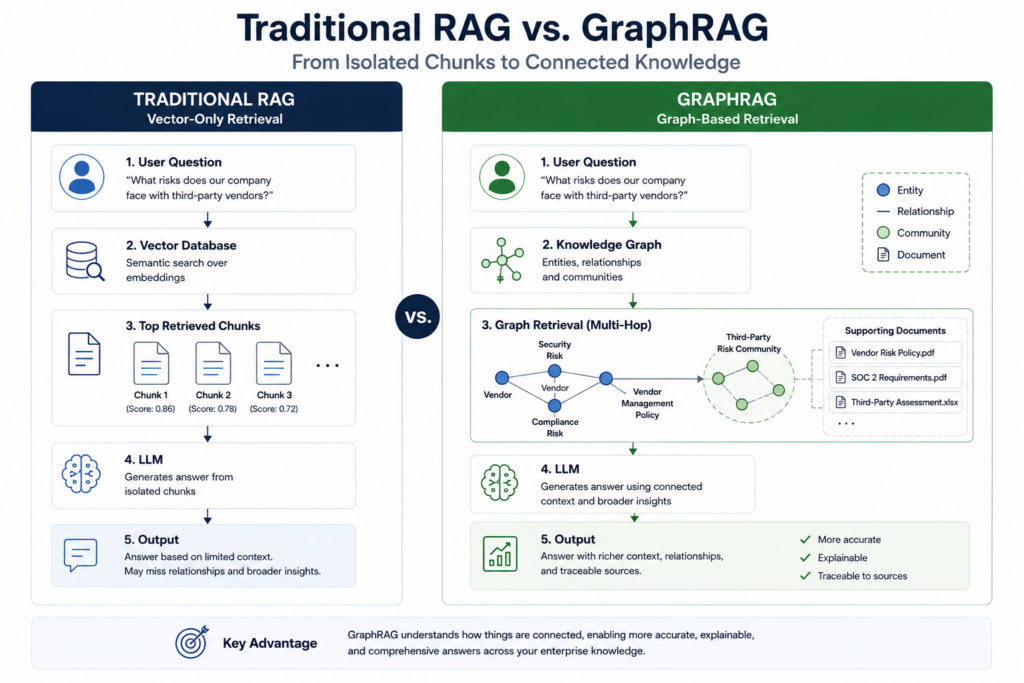
The Limits of Vanilla Vector RAG in Enterprise Environments
Vanilla vector RAG is powerful when the task is to find the most semantically similar passage for a narrowly scoped question. It works well for direct lookups such as policy definitions, product facts, troubleshooting steps, or document-level Q&A. In those cases, a user prompt is embedded, compared against stored chunk embeddings, and the closest matches are passed to the LLM as context.
The problem appears when enterprise questions are not local. Architects, analysts, auditors, and operations teams often ask questions that require synthesis across departments, systems, documents, projects, controls, vendors, and owners. A vector database can retrieve text that sounds similar, but it does not naturally understand that one application depends on a shared database, that the database supports a regulated workflow, that the workflow is owned by a specific team, and that the same team has unresolved security findings in another system.
This is the roadblock that GraphRAG architecture is designed to solve. Instead of treating every document chunk as an isolated semantic object, GraphRAG extracts entities and relationships from enterprise content and stores them as a structured knowledge graph. The LLM can then retrieve not only similar passages, but also connected people, systems, controls, risks, projects, and dependencies.
This does not replace vector databases for AI. It extends them. Vector search remains useful for semantic recall, while graph traversal provides relationship-aware context assembly. In a mature enterprise system, both retrieval patterns operate together: vectors find relevant language, and graphs explain how the retrieved entities are connected.
However, this additional intelligence comes with a cost. GraphRAG requires repeated LLM calls for entity extraction, relationship mapping, claim detection, community summarization, and sometimes query-time graph reasoning. Without an enterprise semantic caching layer, the same entities and summaries may be regenerated repeatedly, causing API cost, latency, and token consumption to increase quickly as the corpus grows.
For enterprise architects, the practical question is not whether GraphRAG is more advanced than vector search. The real question is whether the organization’s data relationships are important enough to justify a graph extraction pipeline, a graph database, retrieval orchestration, governance controls, and ongoing graph maintenance.
Key Takeaways
- GraphRAG architecture integrates knowledge graphs with vector embeddings to enable relationship-aware retrieval and multi-hop reasoning beyond traditional semantic search capabilities
- Production systems require balancing entity extraction costs, graph maintenance overhead, and infrastructure decisions between Neo4j, AWS Neptune, or hybrid vector-graph stores
- Enterprise deployment demands observability frameworks, semantic caching strategies, and governance controls for relationship data exposure and knowledge provenance tracking
Transforming Unstructured Data: Mechanics of Enterprise Knowledge Graphs
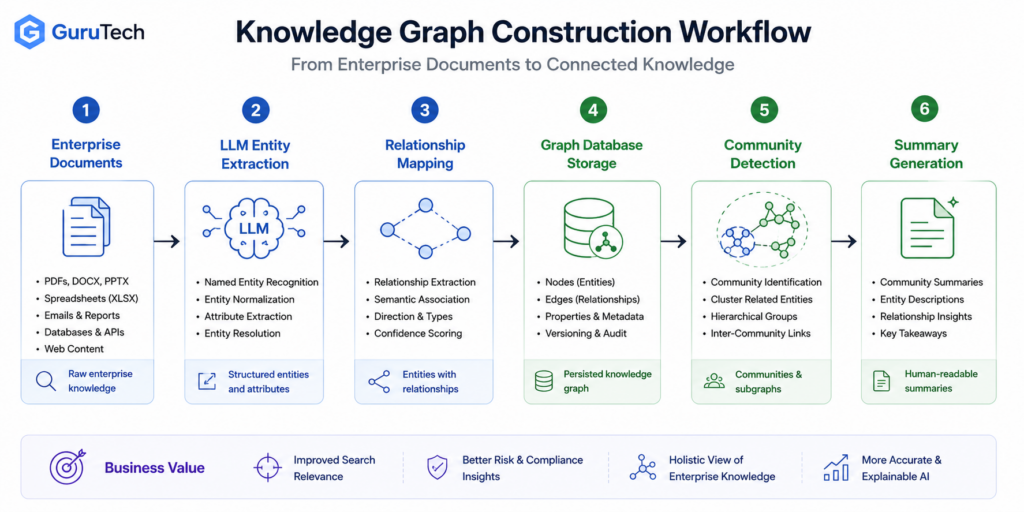
Enterprise knowledge graph construction converts raw documents into structured entity-relationship models through LLM-driven extraction pipelines.
Community detection algorithms identify semantic clusters for improved multi-hop reasoning and query performance.
Entity and Relationship Extraction Through LLMs
LLM-based extraction pipelines process enterprise documents to identify entities and their relationships through prompted inference or fine-tuned models.
The extraction phase typically uses GPT-4 or domain-adapted models to parse unstructured text and output structured triples in (subject, predicate, object) format.
Production implementations face a fundamental tradeoff between extraction quality and computational cost.
Dependency parsing achieves 94% of LLM-based performance while reducing token consumption by orders of magnitude.
This approach leverages syntactic structure to extract subject-verb-object patterns without expensive model inference.
Extraction Pipeline Components:
- Entity recognition with coreference resolution to canonical forms
- Relationship mapping through dependency grammar or LLM prompting
- Relation embeddings generated via text-embedding-3-large or similar models
- Subgraph extraction for one-hop traversal during retrieval
Hybrid architectures combine lightweight parsers for high-volume content with LLM extraction for critical documents requiring maximum accuracy.
The extracted triples populate graph databases like Neo4j or in-memory stores such as iGraph, with each entity and relation stored alongside vector embeddings for hybrid retrieval workflows.
Clustering with Community Detection Algorithms
Community detection partitions the knowledge graph into semantic clusters that share topical coherence, enabling efficient graph summarization and targeted retrieval.
The Leiden algorithm represents the current standard for knowledge graph construction in production GraphRAG systems due to its superior modularity optimization and scalability compared to earlier methods like Louvain clustering.
Graph algorithms evaluate modularity scores to identify densely connected subgraphs while minimizing inter-community edges.
Each detected community receives an LLM-generated summary that captures the collective semantic context of its constituent entities and relationships.
Community Detection Parameters:
| Parameter | Purpose | Enterprise Setting |
|---|---|---|
| Resolution | Controls cluster granularity | 0.8-1.2 for document corpora |
| Min cluster size | Filters noise communities | 5-10 entities typical |
| Iteration limit | Balances quality vs speed | 10-20 iterations sufficient |
Graph traversal strategies leverage these communities during query execution.
Global queries aggregate community summaries for broad questions spanning the entire corpus.
Local queries perform targeted one-hop traversal within specific communities identified through vector similarity to the query embeddings, reducing latency while maintaining retrieval precision for domain-specific questions.
Architectural Comparison: Microsoft GraphRAG Versus Standard Vector Retrieval
Microsoft GraphRAG introduces a five-stage indexing pipeline with community detection and hierarchical summarization, contrasting sharply with vector RAG’s embed-and-retrieve pattern.
The two architectures diverge most significantly in their handling of distributed reasoning tasks and upstream token consumption during index construction.
Global Versus Local Query Performance
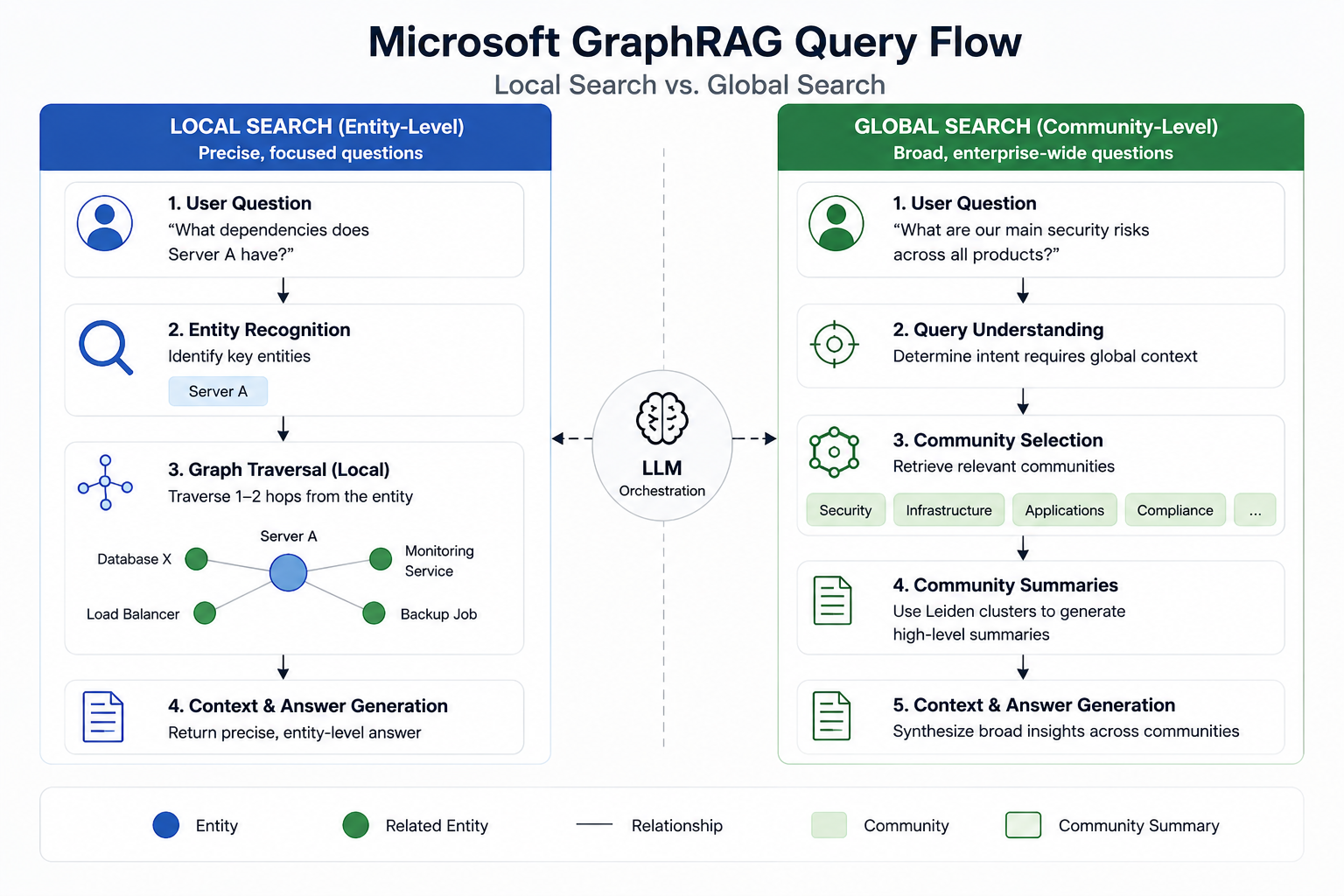
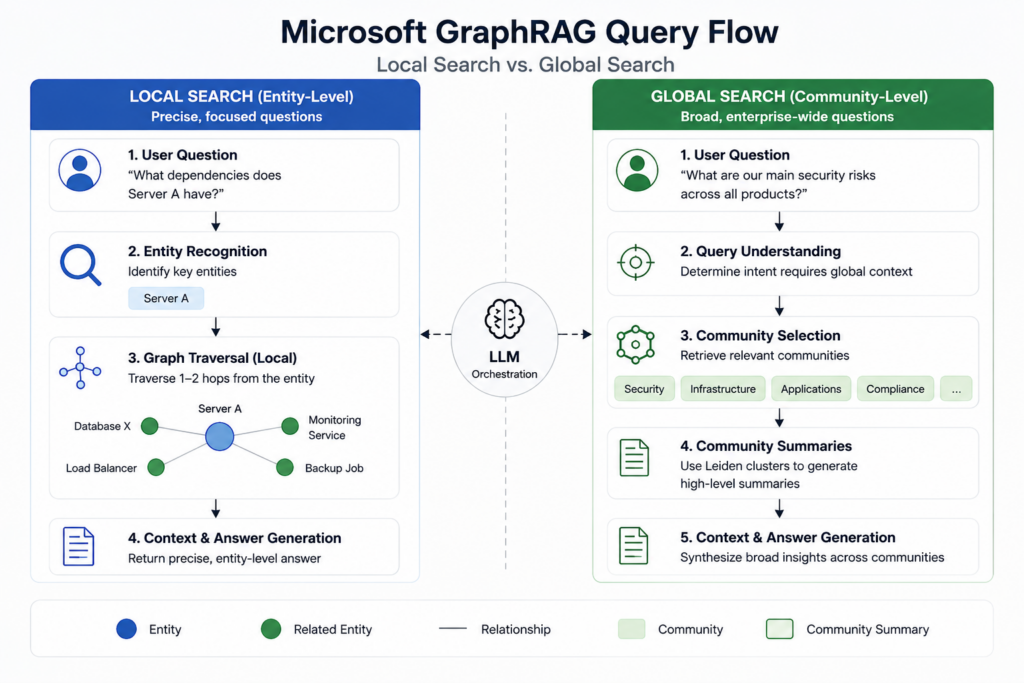
Microsoft GraphRAG employs dual query modes that fundamentally alter retrieval mechanics.
Global search operates against community summaries generated through Leiden clustering, enabling dataset-wide aggregation without traversing individual chunks.
This approach delivers 85%+ accuracy on multi-hop reasoning tasks where vector RAG typically plateaus at 70%.
Local search combines entity-based graph traversal with vector similarity, ranking results through reciprocal rank fusion.
Production deployments show 86% accuracy on complex queries versus 32% for vector-only systems, a 54-point differential driven by relationship-aware context assembly.
Vector RAG fails on schema-bound queries requiring aggregation across disconnected entities.
Microsoft’s architecture addresses this through community detection, which groups related entities during indexing and pre-generates summaries at multiple hierarchical levels.
When queries demand cross-document synthesis, global search retrieves these pre-computed community abstractions rather than reassembling context at runtime.
LightRAG and HippoRAG implement cascaded retrieval with graph expansion as a fallback layer, while FastGraphRAG reduces latency through lazy entity resolution.
Hybrid retrieval strategies combine vector-first ranking with selective graph traversal, applying re-ranking models only after initial candidate filtering to manage computational overhead.
Indexing Token Overhead and Cost Implications
Microsoft GraphRAG consumes 80 to 2,000 tokens per input token during index construction, driven by entity extraction, relationship mapping, community summarization, and graph embedding.
At 2026 pricing, processing 10 million tokens costs $80 to $2,000 depending on model selection and summarization depth.
Vector RAG indexes at 1:1 token ratios with negligible overhead beyond embedding API calls.
This creates a 25x to 250x cost delta favoring vector approaches for static knowledge bases with infrequent updates.
Graph maintenance introduces ongoing costs absent from vector systems.
Entity drift, relationship decay, and schema evolution require periodic re-indexing.
Enterprises running Neo4j or AWS Neptune must provision vector indexes alongside graph storage, duplicating infrastructure for hybrid retrieval workflows.
LlamaIndex GraphRAG workflows mitigate overhead through incremental indexing, processing only document deltas rather than full corpus regeneration.
Semantic caching reduces redundant entity extraction when documents share common entities, particularly effective in regulatory compliance and legal research applications where entity vocabularies remain stable.
Production teams deploying LazyGraphRAG defer community detection until query time, trading indexing cost for retrieval latency.
This pattern suits environments with sparse query distributions where pre-computing all community summaries wastes resources.
GraphRAG Architecture for Enterprise AI Stack: Neo4j and LlamaIndex Integration
Enterprise GraphRAG deployments require orchestrating property graph stores with entity extraction pipelines and query routing mechanisms.
The integration layer coordinates knowledge graph construction, community detection algorithms, and hybrid retrieval strategies across distributed infrastructure.
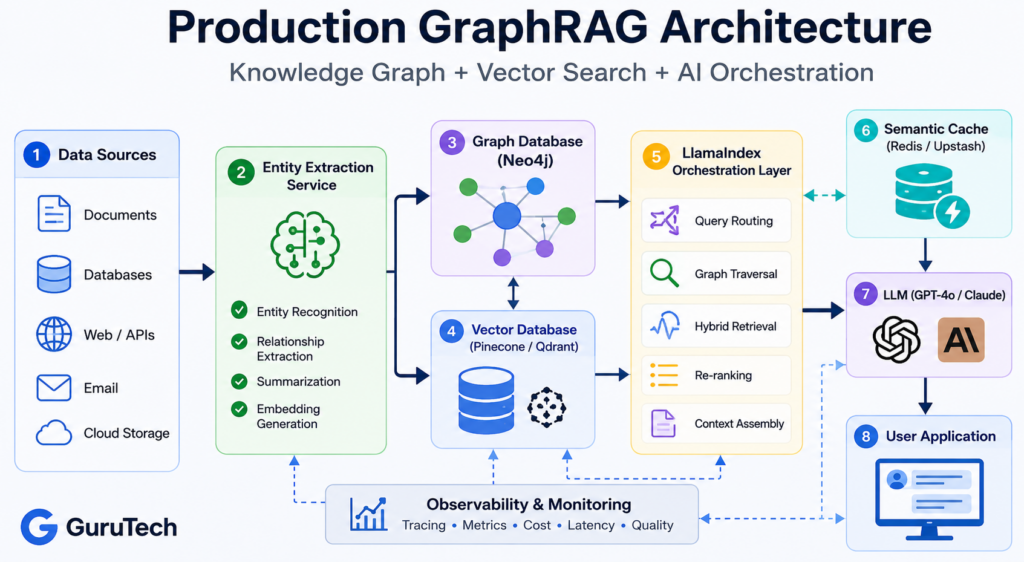
Implementing the Graph Database Layer
Neo4j serves as the primary property graph store for most GraphRAG implementations using LlamaIndex, handling relationship-aware queries through Cypher statements while maintaining entity metadata and community hierarchies.
The database layer extends beyond simple triple storage to support hierarchical Leiden clustering for community detection, with configurable max_cluster_size parameters that determine graph partitioning granularity.
AWS Neptune provides an alternative for organizations standardized on AWS infrastructure, though it requires additional abstraction layers to support the same property graph operations.
The choice between Neo4j and Neptune depends on existing infrastructure commitments, Cypher query optimization requirements, and graph data science library compatibility.
Hybrid storage architectures combine graph databases with vector databases for semantic similarity operations.
Milvus and LanceDB handle embedding storage and approximate nearest neighbor searches, while Neo4j maintains the structural relationships and community summaries.
This separation enables independent scaling of vector search workloads versus graph traversal operations.
The GraphRAGStore class implementation demonstrates production patterns for coordinating these systems.
It extends Neo4jPropertyGraphStore with community detection algorithms, relationship description caching, and summary generation workflows that minimize redundant LLM calls during query execution.
Automating Multi-Agent Orchestration for Dynamic Querying
Multi-agent architectures enable dynamic graph exploration patterns where specialized agents handle entity extraction, relationship mapping, community summarization, and query routing decisions.
Function calling mechanisms coordinate agent workflows, determining when to execute local queries against specific communities versus global queries across the entire knowledge graph.
The orchestration layer implements semantic caching strategies that store community summaries and frequently accessed subgraph patterns.
Cache invalidation policies must account for graph drift as new documents update entity relationships and community structures.
Production systems typically implement time-based expiration combined with change detection on community membership.
Query routing agents analyze natural language questions to determine optimal retrieval strategies:
| Strategy | Use Case | Infrastructure Load |
|---|---|---|
| Local community search | Specific entity relationships | Low token consumption |
| Global graph traversal | Cross-domain synthesis | High LLM call volume |
| Hybrid vector + graph | Semantic similarity with context | Balanced compute distribution |
Token consumption becomes a critical cost factor during indexing and query execution.
GraphRAGExtractor processes document chunks with configurable max_paths_per_chunk limits to control extraction granularity versus API costs.
Dataflow pipelines batch entity extraction operations and implement retry logic with exponential backoff for rate-limited environments.
Production deployments require observability into graph maintenance operations.
Key metrics include community stability, relationship density, and query latency distributions across different retrieval strategies.
Code-Level Blueprint: Structuring a Python Graph Extraction Pipeline
A production-grade graph extraction pipeline begins with the GraphGenerator class as a modular wrapper over three core components: document processing, entity extraction, and relationship mapping.
The architecture leverages a factory pattern that enables runtime provider substitution across language models, storage backends, and vector stores without requiring pipeline modifications.
Core Pipeline Components
| Component | Implementation | Configuration Method |
|---|---|---|
| Document Parser | Docling, custom readers | Environment variables |
| LLM Provider | LiteLLM wrapper, custom | Factory registration |
| Entity Extractor | SpaCy, GPT-4o | Dependency parsing |
| Graph Storage | Neo4j, Neptune, igraph | Provider factory |
| Chunking Strategy | Hierarchical chunking | Indexing pipeline config |
The indexing pipeline implements a stateful workflow from document loading through community detection.
Engineers structure extraction logic by registering custom implementations through factory methods rather than modifying core library code.
The LiteLLM wrapper abstracts API calls to GPT-4o and alternative models while maintaining cache coherence across retry attempts.
Example Python Graph Extraction Schema
GraphRAG pipelines need strict schemas because graph databases become difficult to maintain when entity names, relationship labels, and metadata fields are inconsistent. A typed extraction contract prevents the LLM from inventing arbitrary node types or producing malformed relationships that cannot be merged cleanly into Neo4j, Neptune, or another graph store.
from typing import Literal, List, Optional
from pydantic import BaseModel, Field, ValidationError
EntityType = Literal[
"Person", "Team", "Application", "Database", "Server",
"Policy", "Control", "Vendor", "Project", "Risk"
]
RelationshipType = Literal[
"OWNS", "DEPENDS_ON", "CONNECTS_TO", "MANAGES",
"GOVERNED_BY", "MITIGATES", "SUPPORTS", "EXPOSES_RISK"
]
class Entity(BaseModel):
id: str = Field(description="Stable canonical identifier, not a display label")
name: str
type: EntityType
source_document: str
confidence: float = Field(ge=0.0, le=1.0)
class Relationship(BaseModel):
source_id: str
target_id: str
type: RelationshipType
evidence: str = Field(description="Short source text supporting the edge")
confidence: float = Field(ge=0.0, le=1.0)
class GraphExtraction(BaseModel):
entities: List[Entity]
relationships: List[Relationship]
raw_extraction = {
"entities": [
{
"id": "app_customer_portal",
"name": "Customer Portal",
"type": "Application",
"source_document": "security-review-q3.md",
"confidence": 0.94,
},
{
"id": "db_customer_records",
"name": "Customer Records Database",
"type": "Database",
"source_document": "security-review-q3.md",
"confidence": 0.91,
},
{
"id": "control_encryption_at_rest",
"name": "Encryption at Rest Control",
"type": "Control",
"source_document": "security-review-q3.md",
"confidence": 0.88,
},
],
"relationships": [
{
"source_id": "app_customer_portal",
"target_id": "db_customer_records",
"type": "DEPENDS_ON",
"evidence": "The customer portal reads account profile data from the customer records database.",
"confidence": 0.92,
},
{
"source_id": "control_encryption_at_rest",
"target_id": "db_customer_records",
"type": "MITIGATES",
"evidence": "Encryption at rest is required for the customer records database.",
"confidence": 0.89,
},
],
}
try:
graph_payload = GraphExtraction.model_validate(raw_extraction)
except ValidationError as error:
raise ValueError(f"Invalid graph extraction output: {error}")
print(graph_payload.model_dump_json(indent=2))
This schema gives the extraction layer a controlled vocabulary for nodes and edges. In production, the same pattern can be extended with tenant IDs, access-control labels, document lineage, timestamped extraction metadata, and model version information. Those fields become critical when GraphRAG is deployed in regulated environments where every generated relationship must be traceable back to a source document.
Graph Construction Sequence
Hierarchical chunking precedes parallel entity extraction and claim detection workflows.
Entity embeddings feed into community detection algorithms while maintaining bidirectional references to source chunks.
The architecture separates indexing and retrieval concerns through distinct workflow registrations.
Production implementations configure providers via environment variables mapped to factory-registered classes.
Custom dependency parsing integrates with SpaCy pipelines for domain-specific entity recognition.
The graph storage layer abstracts vendor differences between Neo4j’s property graphs and Neptune’s RDF structures through the GraphRAG Knowledge Model abstraction.
Operational Challenges of GraphRAG
GraphRAG is not simply a better retrieval method that can be enabled as a checkbox. It introduces a new operational layer that must be designed, monitored, and governed like any other enterprise data platform. The main risk is that teams underestimate the complexity of maintaining a living knowledge graph after the first proof of concept succeeds.
Token Consumption During Indexing
Traditional vector RAG usually requires chunking, embedding, and storage. GraphRAG adds entity extraction, relationship inference, claim detection, graph summarization, and community-level report generation. Each step can require additional LLM calls. For a static corpus this may be acceptable, but for active enterprise content such as tickets, project documentation, security findings, and support knowledge bases, the indexing pipeline can become a recurring cost center.
This is why GraphRAG should be paired with cost controls from the beginning. Teams should cache repeated extraction outputs, batch document updates, use cheaper models for low-risk extraction tasks, and reserve stronger models for high-value relationship inference. A mature AI token observability dashboard should track token usage by pipeline stage rather than only measuring total application spend.
Knowledge Graph Drift
Enterprise graphs drift because the enterprise itself changes. Applications are retired, teams reorganize, vendors change contracts, policies are updated, and infrastructure dependencies shift. If the graph is not refreshed, the system can produce confident answers based on stale relationships.
Production teams need incremental indexing, source-document version tracking, graph invalidation rules, and scheduled community summary regeneration. The goal is not to rebuild the entire graph after every document update. The goal is to identify which entities, edges, and communities are affected by the change and refresh only those graph regions.
Entity Resolution Challenges
Entity resolution is one of the hardest practical problems in GraphRAG. The same system may be called “Customer Portal,” “Portal App,” “CP Web,” or “customer-portal-prod” across different documents. Without canonicalization, the graph becomes fragmented and query results become inconsistent.
Architects should define normalization rules, controlled vocabularies, entity aliases, confidence thresholds, and human-review workflows for ambiguous matches. For high-risk domains such as compliance, security, finance, and healthcare, human-in-the-loop review is often necessary before newly inferred relationships are promoted into the production graph.
Observability Requirements
Vector RAG observability usually focuses on retrieval relevance, latency, embedding quality, and answer faithfulness. GraphRAG requires additional telemetry: graph traversal depth, community selection accuracy, edge confidence, relationship density, stale-node ratio, cache hit rate, and global-versus-local query routing decisions.
These metrics help architects diagnose whether a failed answer came from poor vector recall, incorrect entity extraction, weak graph connectivity, outdated community summaries, or an LLM generation issue. Without this visibility, GraphRAG systems become difficult to debug because failures can originate from multiple layers of the retrieval stack.
Semantic Caching as a Cost Control Layer
Semantic caching becomes more important in GraphRAG than in basic RAG because many queries repeatedly touch the same high-value entities, communities, and summaries. Caching can reduce repeated extraction, repeated summarization, and repeated traversal interpretation. This is especially valuable for enterprise domains with stable vocabulary, such as security controls, compliance frameworks, product catalogs, and internal application inventories.
The cache should not only store final answers. It should also cache intermediate artifacts such as normalized entities, extracted triples, community summaries, graph traversal results, and common query plans. This turns semantic caching into an infrastructure component rather than a simple response optimization.
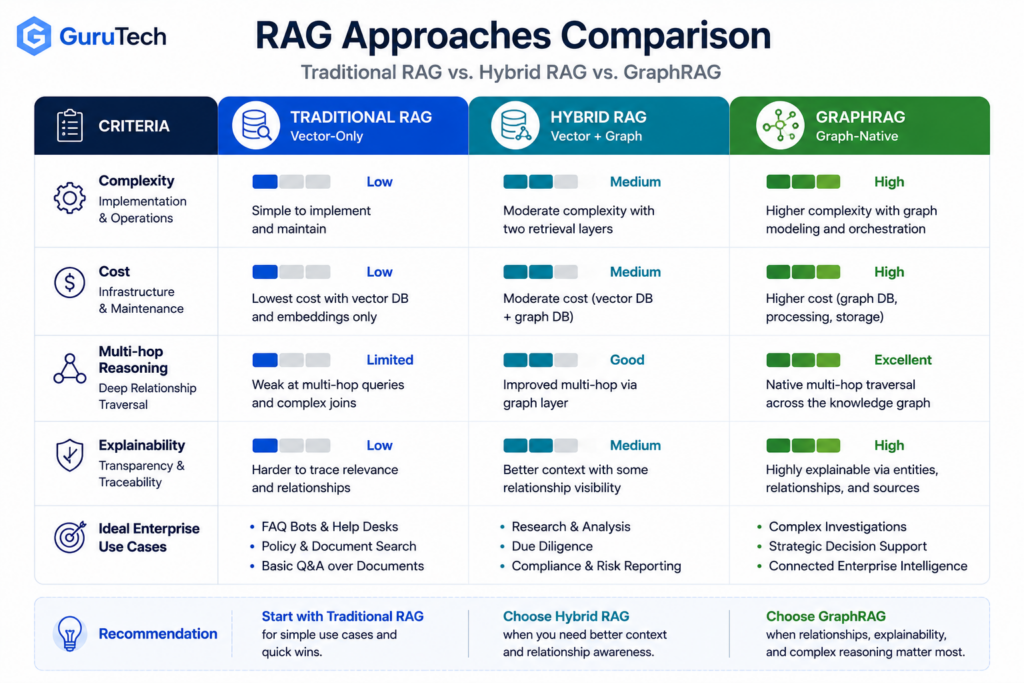
Traditional RAG vs Hybrid RAG vs GraphRAG
The safest way to evaluate GraphRAG is to compare it against simpler retrieval architectures. Many enterprise use cases do not need a full graph layer. Others fail specifically because the system lacks structured relationships. The following matrix gives architects a practical way to decide which level of retrieval infrastructure is justified.
| Capability | Traditional RAG | Hybrid RAG | GraphRAG |
|---|---|---|---|
| Primary Retrieval Method | Vector similarity over document chunks | Vector search plus metadata filters or reranking | Vector search plus knowledge graph traversal |
| Implementation Complexity | Low | Medium | High |
| Indexing Cost | Low | Medium | High |
| Multi-Hop Reasoning | Weak | Moderate | Strong |
| Explainability | Limited to retrieved chunks | Moderate with metadata and citations | High with entity paths and relationship evidence |
| Best Fit | Document Q&A, support articles, policy lookup | Enterprise search with filters, ranking, and mixed data types | Compliance, security, dependency mapping, research synthesis |
| Main Risk | Misses relationships across documents | Can become complex without graph-level structure | High engineering overhead and graph maintenance |
Decision Criteria: When to Justify Enterprise Graph Infrastructure
Enterprise teams evaluating GraphRAG must assess whether knowledge graph infrastructure justifies the complexity and cost compared to traditional vector-based retrieval.
The decision hinges on query complexity, accuracy requirements, and knowledge management maturity rather than technical novelty.
Primary Justification Triggers
Organizations should consider GraphRAG when multi-hop reasoning becomes critical for business operations.
Vector search degrades significantly on relationship-dependent queries where entities connect across multiple documents.
Graph-based retrieval achieves 85%+ accuracy on complex queries compared to 70% for vector-only systems.
Infrastructure Investment Thresholds
| Criteria | Vector RAG Sufficient | GraphRAG Required |
|---|---|---|
| Query Patterns | Single-entity similarity | Multi-hop traversal, temporal reasoning |
| Latency Tolerance | <100ms | 200-400ms acceptable |
| Accuracy Requirements | 70-75% | 85%+ with explainability |
| Cost per 1M Queries | $200-500 | $800-1,500 justified |
| Data Relationships | Minimal entity connections | Rich relationship networks essential |
Migration and Scalability Considerations
Legacy code migration to GraphRAG requires entity extraction pipelines, relationship mapping workflows, and graph construction automation.
Custom code migration demands expertise in Neo4j, AWS Neptune, or comparable graph databases alongside vector infrastructure for hybrid approaches.
Scalable retrieval depends on community detection algorithms like Leiden clustering for graph partitioning and semantic caching to reduce token consumption during repeated graph traversals.
Enterprise observability must track graph drift, relationship accuracy degradation, and indexing costs as knowledge bases expand beyond initial deployment scope.
Frequently Asked Questions
GraphRAG implementations in production environments raise critical questions around integration patterns, infrastructure design, security controls, and operational monitoring that directly impact system reliability and enterprise compliance requirements.
What enterprise architecture patterns work best for GraphRAG?
GraphRAG integration typically follows a layered architecture that positions the knowledge graph as a middle tier between data lakes and application APIs.
The ingestion layer connects to existing data lakes through stream processors or batch ETL pipelines that feed the entity extraction workflow.
Most enterprise deployments implement Microsoft’s GraphRAG architecture with a separation between indexing and query pipelines.
The indexing pipeline extracts entities and relationships from source documents, then stores them in a graph database like Neo4j or AWS Neptune.
The query layer sits behind API gateways that handle authentication, rate limiting, and request routing between traditional vector search and graph-based retrieval.
Hybrid architectures combine vector stores for semantic search with graph databases for relationship traversal.
LlamaIndex GraphRAG workflows enable this pattern by routing queries based on complexity—simple factual queries hit vector indexes while multi-hop reasoning questions trigger graph traversal with community-aware retrieval.
API gateways expose both global and local query strategies as separate endpoints.
Global queries leverage pre-computed community summaries generated through Leiden clustering for dataset-wide questions.
Local queries traverse the graph from specific entities to answer precise questions about relationships.
How should indexing and retrieval pipelines be designed for GraphRAG to support multi-tenant isolation, lineage, and deterministic rebuilds in production?
Multi-tenant GraphRAG systems require namespace isolation at both the graph database and vector store layers.
Each tenant receives a dedicated graph partition or subgraph with separate embedding indexes to prevent data leakage.
Graph databases like Neo4j support this through label-based isolation or database-level separation in enterprise editions.
Indexing pipelines must maintain complete lineage from source documents through entity extraction to final graph structures.
This requires capturing extraction timestamps, LLM versions, prompt templates, and community detection parameters in metadata tables.
Production GraphRAG implementations store this lineage data alongside graph nodes to enable debugging and compliance audits.
Deterministic rebuilds depend on versioned entity extraction prompts and frozen embedding models.
GraphRAG systems cache LLM responses using input prompt hashes to ensure identical extractions during reprocessing.
The knowledge graph construction pipeline must be idempotent, producing identical graph structures when run against the same source data and parameters.
Incremental indexing requires tracking document versions and changed entities.
When documents update, the pipeline identifies affected graph nodes and re-extracts only the modified sections.
Community detection reruns on affected subgraphs while preserving stable community IDs elsewhere to maintain query consistency.
What are the key infrastructure tradeoffs between running GraphRAG components on Kubernetes versus managed services, and how do they affect latency, cost, and operability?
Kubernetes deployments provide control over resource allocation and enable co-location of embedding models with graph databases to minimize network latency.
Container orchestration allows horizontal scaling of entity extraction workers during bulk indexing operations.
However, teams must manage graph database clustering, backup strategies, and persistent volume management.
Managed services like AWS Neptune or Azure Cosmos DB with Graph API reduce operational overhead but introduce network hops between compute and storage layers.
Latency increases when embedding generation runs in Kubernetes pods while graph traversal executes in a managed service across availability zones.
This latency compounds during multi-hop queries that alternate between vector search and graph operations.
Cost structures differ significantly between approaches.
Self-hosted Neo4j on Kubernetes incurs compute and storage costs based on provisioned resources, while managed graph databases charge for throughput, storage, and query execution.
Token consumption for entity extraction dominates indexing costs regardless of infrastructure choice, but managed services add per-request charges that accumulate during high-frequency query patterns.
Operability tradeoffs center on observability and failure modes.
Kubernetes deployments require custom monitoring of graph query performance, cache hit rates, and embedding latency.
Managed services provide built-in metrics but limit access to internal query plans and graph statistics needed for optimization.
How can GraphRAG be applied to large codebases to enable architecture-level Q&A while preserving access controls and minimizing IP leakage risk?
Codebase GraphRAG systems extract entities representing files, functions, classes, and dependencies as graph nodes.
Relationships capture import statements, function calls, inheritance hierarchies, and data flows.
This enables architecture queries like identifying all services that depend on a specific API or tracing data lineage through multiple microservices.
Entity extraction for code requires specialized prompts that understand programming languages and architectural patterns.
The extraction pipeline parses abstract syntax trees to identify structural elements, then uses LLMs to generate semantic descriptions and categorize components by architectural role.
Graph relationships encode both syntactic dependencies from static analysis and semantic relationships from code comments and documentation.
Access control preservation requires mapping code repository permissions to graph node labels.
Each entity carries metadata indicating which teams or roles can access it based on source file permissions.
Query pipelines filter graph traversal results by user permissions before returning answers, preventing exposure of restricted components.
IP leakage mitigation involves running entity extraction and embedding generation within the enterprise network perimeter rather than sending code to external LLM APIs.
Self-hosted embedding models and local LLM deployments keep source code isolated.
Query responses include only high-level architectural descriptions rather than exposing actual code snippets unless explicitly requested by authorized users.
Graph summarization techniques generate architecture documentation by clustering related components into communities.
These summaries describe system boundaries and interactions without revealing implementation details, supporting knowledge sharing across teams while protecting sensitive code.
Which security controls and governance mechanisms are required for GraphRAG in regulated environments (RBAC/ABAC, encryption, audit logging, and data residency)?
RBAC implementations in GraphRAG map user roles to graph query scopes that limit accessible entity types and relationship traversals.
ABAC extends this by evaluating document classification labels, data sensitivity tags, and contextual attributes like time of access before returning query results.
Graph databases enforce these controls through query-time filters that restrict node visibility based on security metadata.
Encryption requirements span multiple layers in GraphRAG architecture.
Data at rest encryption protects graph database storage volumes, vector indexes, and cached LLM responses.
In-transit encryption secures communication between embedding services, graph databases, and API gateways using TLS 1.3.
Final Thoughts
GraphRAG architecture is most valuable when enterprise AI systems need to understand how information is connected, not merely which document chunk is semantically similar to a prompt. For narrow factual lookup, traditional vector RAG is usually cheaper, faster, and easier to maintain. For broad synthesis questions, dependency analysis, compliance mapping, security reviews, and architecture-level reasoning, the graph layer can become the difference between a useful enterprise AI system and a retrieval demo that fails under real operational complexity.
The best implementation path is incremental. Start with a constrained domain such as application inventory, security controls, vendor relationships, customer support issues, or policy compliance. Build a small graph, validate entity quality, measure retrieval improvement, and compare cost against vector-only RAG. If the graph improves answer quality for high-value questions, expand gradually into additional data sources and relationship types.
Enterprise teams should also treat GraphRAG as an operational platform. That means semantic caching, observability, lineage tracking, access controls, graph refresh logic, and human validation for sensitive relationships. Without these controls, GraphRAG can become expensive, opaque, and difficult to trust.
Are current LLM applications hitting a wall with broad, synthesis-style questions? The next step is to inspect the structure of the data itself: the entities, dependencies, ownership models, risks, and relationships that vector search alone cannot see.