AI API costs are becoming one of the largest expenses for teams running automation workflows in 2026. A single agent session can become surprisingly expensive once prompts, context, tool calls, and output tokens are counted together.
Workflows that seemed affordable during testing can quickly scale to hundreds or thousands of dollars per month in production. What begins as a modest experiment with Claude or GPT-4o often turns into an ongoing expense that eats into margins faster than expected.
Most teams can reduce AI API costs by 50-80% through a combination of model routing, prompt optimization, caching strategies, and context management—without sacrificing output quality. Optimizing workflows makes the difference between sustainable automation and a budget that spirals out of control as usage scales.
The problem goes beyond choosing a cheaper model. Token waste happens across the entire request lifecycle—through bloated system prompts, redundant context windows, duplicate tool calls, and unnecessarily verbose outputs.
Teams that understand where tokens go and learn how to compress, cache, and route requests strategically can scale AI workflows profitably. Many businesses now look for ways to reduce AI API costs as production AI workflows become more expensive to operate.
Executive Summary: Why AI API Costs Are Rising Rapidly in 2026
AI inference costs now represent 85% of enterprise AI budgets, creating unexpected financial pressure for development teams. Token costs have actually decreased over the past 18 months.
Note: AI model pricing changes frequently, so the examples in this guide should be treated as planning estimates rather than fixed prices. Always verify current pricing before building cost forecasts.
The problem is volume at scale.
Production workloads generate token consumption that teams rarely predict during development. A customer service bot processing 10,000 tickets daily at 2,000 tokens per ticket creates 20 million tokens in API calls each day.
At production scale, that single feature can become a meaningful monthly infrastructure expense.
Most engineering teams face a predictability gap. They test features in staging where usage is light and costs stay invisible.
They ship to production. Then 67% of engineering leaders report their AI API costs exceeded projections by more than 40%.
Key cost drivers in 2026:
- System prompts sent with every API call can account for $60,000-$120,000 annually before processing any user content
- Context window accumulation in multi-turn conversations increases per-call costs linearly with conversation length
- Output tokens cost 3-5x more than input tokens, making generation-heavy features significantly more expensive
- Token-based pricing scales with usage unlike traditional SaaS seat licensing
The first serious cost escalation conversation often happens shortly after production usage begins. Teams focus on making AI features work, not on token efficiency at production scale.
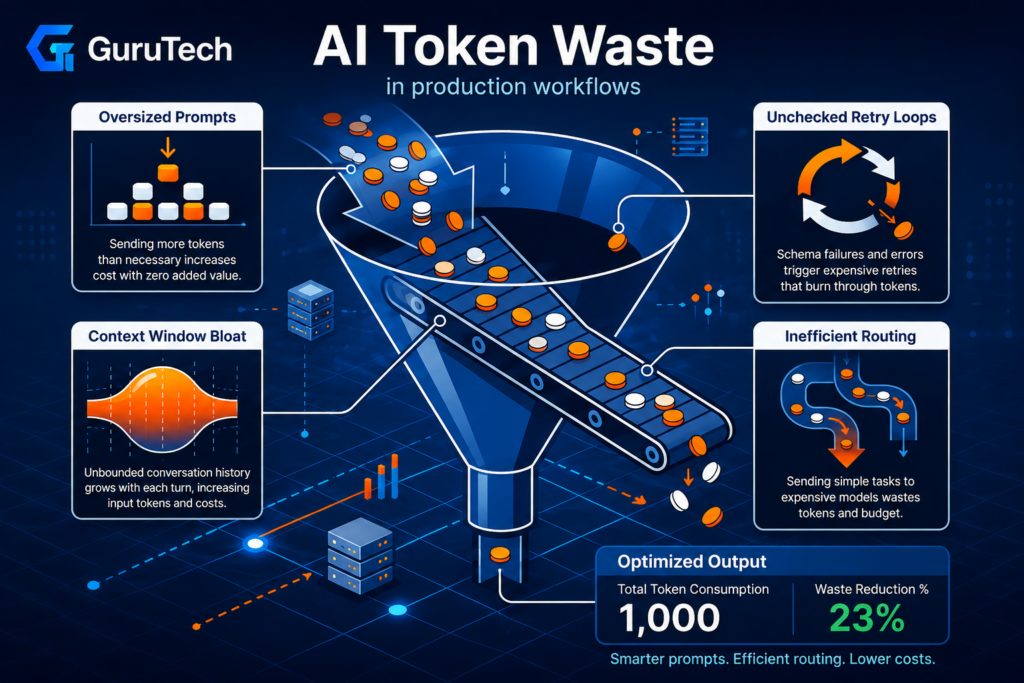
The 3 Hidden Leaks Draining Your AI API Budget
Most teams track their API calls and model choices but miss three patterns that can double their actual spend. These leaks involve how context grows over time, how conversation history accumulates tokens, and how structured outputs fail and retry.
Context Window Bloat
Each API request sends input tokens that include the prompt, instructions, and any context needed for the response. Many applications pass the same large system prompt on every call, even when parts of it aren’t relevant.
A typical example: an app sends 3,000 tokens of instructions defining ten different capabilities, but each user request only needs one or two of those capabilities. The other 2,500 tokens add cost on every call with no benefit.
Common sources of wasted input tokens:
- Full documentation passed with every request instead of relevant sections
- Lengthy system prompts that could be compressed to half the size
- Tool definitions for functions the current request won’t use
- Example outputs that demonstrate formatting but add 500+ tokens
Teams can cut input costs by 40-60% by trimming system prompts and only including context relevant to each specific request. A request that drops from 4,000 to 1,500 input tokens saves 62% on input costs immediately.
The Chat History Scaling Problem
Chat applications need conversation history to maintain context across turns. Most implementations append every exchange to the context window, so token counts grow linearly with conversation length.
A chat that starts at 500 tokens reaches 5,000 tokens after ten exchanges. By message twenty, the application sends 10,000+ input tokens per request.
The cost per message increases throughout the conversation while the value of old messages decreases.
Token growth in a typical chat:
| Messages | Input Tokens | Cost per Message (GPT-4) |
|---|---|---|
| 1-3 | 800 | $0.0014 |
| 10 | 4,500 | $0.0079 |
| 20 | 9,200 | $0.0161 |
| 50 | 22,000 | $0.0385 |
Teams that implement conversation summarization replace old messages with condensed summaries. After five exchanges, the system summarizes messages 1-3 into 200 tokens instead of keeping the original 2,000.
This keeps context windows stable regardless of conversation length.
Structured Output Retry Loops
Applications that request JSON or other structured formats face a specific cost trap. When the model returns malformed JSON, the application rejects it and retries.
Each retry sends the full input tokens again plus any output tokens from the failed attempt. A request with 2,000 input tokens that fails validation three times before succeeding burns 8,000 input tokens total instead of 2,000.
The application pays for four attempts but only gets one usable response.
Retry costs compound quickly:
- Original request: 2,000 input + 300 output = $0.0041
- First retry: 2,000 input + 250 output = $0.0039
- Second retry: 2,000 input + 280 output = $0.0040
- Third retry (success): 2,000 input + 300 output = $0.0041
- Total cost: $0.0161 (3.9x the expected cost)
Teams reduce retry costs by using native structured output modes when available and adding explicit formatting instructions with examples. They also implement output length control through max_tokens parameters.
Setting a token budget prevents runaway output tokens on failed attempts. Applications should also validate the prompt before sending expensive retry loops for requests that will predictably fail.
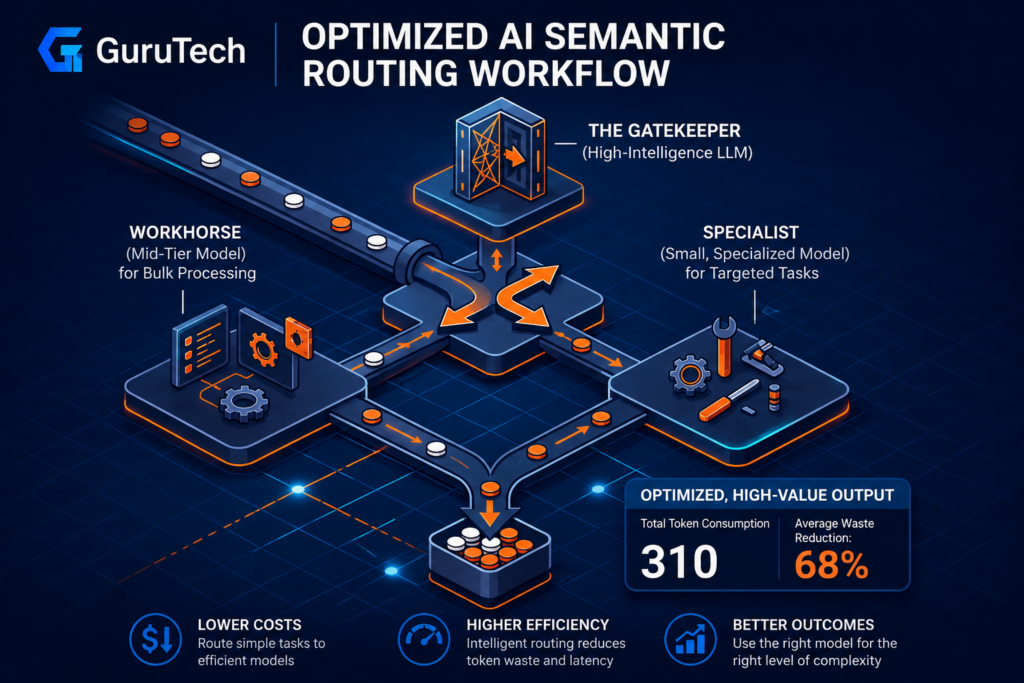
Blueprint: The Tiered Model Routing Architecture
A three-tier routing system matches task complexity to model cost. Classification at the entry point, mid-tier models handle structured work, and premium models are reserved for complex reasoning that actually requires their capabilities.
Tier 1: The Gatekeeper (Classification & Guardrails)
The first tier uses cheap models like GPT-4o-mini, Claude Haiku, or Gemini Flash to classify incoming requests and filter out tasks that don’t need expensive processing. These budget models are usually far cheaper than flagship reasoning models and are often fast enough for high-volume routing decisions.
Classification uses a simple prompt that categorizes requests by complexity: simple (FAQ, summaries), moderate (data extraction, formatting), or complex (multi-step reasoning, architecture decisions). The router can also apply guardrails here, rejecting malformed requests or triggering predefined responses for common questions.
Common Tier 1 Models:
- GPT-4.1 mini – General classification and routing
- Claude Haiku – Fast guardrail enforcement
- Gemini Flash – High-volume sorting tasks
- Mistral Small – Cost-effective triage
This gatekeeper layer prevents expensive models from wasting tokens on tasks a $0.15/million token model can solve. Smart model routing at this stage cuts 60-85% of API costs by ensuring only 15-20% of requests escalate to premium tiers.
Tier 2: The Workhorse (Data Processing & Extraction)
Mid-tier models like Claude Sonnet, GPT-4o, or DeepSeek V3.2 handle the majority of production work. These models typically sit in the middle of the cost curve and excel at structured tasks: parsing documents, generating code snippets, transforming data formats, and answering domain-specific questions.
The routing logic sends requests here when they require more nuance than Tier 1 but don’t need deep reasoning. A request to “extract all email addresses from this support ticket” goes to Tier 2.
A request to “design a microservices architecture for this use case” escalates to Tier 3.
Tier 2 Routing Rules:
| Task Type | Model | Cost Justification |
|---|---|---|
| Code generation (functions) | Claude Sonnet | Syntax accuracy |
| Document parsing | GPT-4o | Format flexibility |
| Data transformation | DeepSeek V3.2 | Speed and cost balance |
| Technical Q&A | Claude Sonnet | Context understanding |
Implementing tiered routing means 70-80% of traffic stops at this tier, avoiding the $15-75 per million token cost of flagship models.
Tier 3: The Specialist (Deep Reasoning & Synthesis)
Premium models like Claude Opus, GPT-5, or future reasoning-focused releases handle requests that require multi-step logic, creative synthesis, or domain expertise. These models are the most expensive tier, but they can deliver accuracy and reasoning quality that cheaper models may not match on complex tasks.
The router escalates to Tier 3 when it detects reasoning keywords (analyze, evaluate, design, refactor), multi-turn conversations requiring memory, or tasks where Tier 2 failed validation.
A one-line grep does not need GPT-5 or Opus, but architectural refactoring does.
Token optimization at this tier means aggressive context pruning. Only include the minimum necessary context rather than dumping entire codebases or documents into the prompt.
When Premium Models Are Actually Worth the Cost
Premium models make sense when the cost of task failure is higher than API costs. They also matter when output quality affects revenue or when human review time exceeds model expenses.
Scenarios requiring Claude Opus or GPT-5:
- Security code reviews where missed vulnerabilities create risk
- Customer-facing content where tone and accuracy affect brand perception
- Complex database query generation where errors break production systems
- Legal or compliance document analysis where mistakes have regulatory consequences
Paying $0.50 for a Claude Opus request is better than spending 30 minutes of engineer time at $100/hour fixing errors from a cheaper model.
When processing 10,000 simple requests, model selection determines the total cost structure.
The NVIDIA AI Blueprint for cost-efficient routing uses Tier 1 models for most traffic and reserves reasoning models for content that truly needs them.
Step-by-Step Logic for Building an Automated Semantic Router
A semantic router uses embeddings to classify requests and sends them to the right model. This method matches simple queries to cheaper models and directs complex requests to premium services.
The workflow starts with defining signals that detect patterns in incoming requests. These signals can be keyword matches, embedding similarity scores, or domain classifications.
A request like “What’s 2+2?” triggers different signals than “Prove the Riemann hypothesis using analytic continuation.”
Decision trees use these signals to pick which model handles each request.
The vLLM Semantic Router uses priority-based routing with higher priority rules evaluating first.
A rule set might look like this:
- Priority 100: Math proofs → expensive reasoning model
- Priority 80: Code debugging → local coding model
- Priority 1: Everything else → cheapest available model
Intelligent defaults help optimize tokens. The router should send 80-90% of requests to local or cheap models.
Only complex queries that need advanced reasoning go to premium APIs.
The architecture places the router between clients and backends as an Envoy External Processor.
Clients send standard OpenAI-compatible requests to a single endpoint. The router intercepts each request, runs classification, and forwards it to the selected model.
Clients never know which backend processed their query.
This setup can significantly reduce monthly inference costs for applications with many simple queries and occasional complex requests.
Advanced AI Cost Optimization Techniques
Companies can cut AI spending by 60-80% using methods like prompt compression, structured outputs, cached data, and batch processing. These strategies reduce token usage and take advantage of discounted pricing tiers.
Prompt Pruning & Semantic Compression
Prompt compression reduces the number of input tokens sent to AI models. This technique removes unnecessary words, repetitive instructions, and verbose examples from prompts.
Semantic compression keeps the meaning but cuts token count by 40-70%. Developers shorten system instructions by using abbreviations, removing filler words, and consolidating redundant context.
A 500-token prompt might compress to 150 tokens while maintaining output quality.
Token optimization works best when teams:
- Remove example demonstrations that the model already understands
- Replace long variable names with shorter versions
- Strip formatting characters and extra whitespace
- Consolidate multiple instructions into single statements
The max_tokens parameter controls output length and prevents runaway generation costs. Setting reasonable limits based on actual needs stops models from producing unnecessary content.
Native JSON Schema Enforcement
Structured output formats reduce token waste from parsing errors and retry requests. Native JSON schema enforcement makes models return valid formatted data on the first attempt.
Models that support schema constraints generate properly formatted responses without extra validation steps.
Benefits of schema enforcement:
- Fewer retries: Valid JSON on first attempt
- Lower token counts: No extra tokens for correction prompts
- Faster processing: Skip validation and parsing steps
- Predictable costs: Eliminate unexpected token spikes from errors
Teams specify exact field names, data types, and required properties. The model follows these rules during generation instead of needing post-processing cleanup.
Prompt Caching Strategies
Prompt caching stores frequently used prompt sections and reuses them at reduced rates. Cached input tokens can cost substantially less than regular input tokens, depending on provider pricing.
Most providers charge separately for cache creation tokens, cache read tokens, and cache writes. The first request creates the cache at standard rates.
Subsequent requests using the same cached content pay only the discounted cache read price.
Caching works best for:
- System instructions that remain constant
- Large context documents referenced repeatedly
- Fixed examples in few-shot prompts
- Shared conversation history across sessions
Cache duration varies by provider but usually lasts 5-60 minutes. Content that changes often doesn’t benefit from caching because cache creation costs offset the savings.
Batch Processing vs Real-Time Inference
The Batch API processes multiple requests together at 50% lower costs than real-time inference.
Batch requests complete within 24 hours instead of seconds, making them suitable for background tasks.
Batch processing works for data enrichment, content generation, evaluations, and non-urgent workloads. Teams collect requests into files, submit them as a single job, and retrieve results when processing finishes.
| Processing Type | Cost | Speed | Best For |
|---|---|---|---|
| Real-time | Standard | Instant | User-facing features |
| Batch | 50% off | Hours | Analytics, reporting |
Real-time inference is necessary for interactive applications where users expect immediate responses.
Background tasks like summarizing historical data or generating training examples should use batch processing for better cost optimization.
Routing logic decides which requests go to batch or real-time endpoints. Priority flags, user context, and urgency requirements help systems pick the most cost-effective method.
Real-World Strategies to Reduce AI API Costs in Production Workflows
A customer support platform processing 50,000 tickets per month can cut API costs by 65% with smart model routing and token management.
The workflow starts with tier-based routing. Simple requests like password resets go to GPT-4o-mini at $0.15 per million input tokens.
Medium-complexity issues like billing disputes route to a mid-cost model such as Claude Haiku.
Only complex technical problems escalate to a premium reasoning model.
Here’s the cost breakdown:
| Task Type | Monthly Volume | Model Used | Cost per 1K Tokens | Monthly Cost |
|---|---|---|---|---|
| Simple queries | 30,000 | GPT-4o-mini | $0.15 | $4.50 |
| Medium complexity | 15,000 | Claude Haiku | $0.80 | $12.00 |
| Complex issues | 5,000 | GPT-5.4 | $2.00 | $10.00 |
Total monthly cost: $26.50 for input tokens
Sending all 50,000 requests to the premium tier would cost significantly more. The tiered approach lowers the monthly bill by routing simple and moderate tasks to cheaper models.
Adding prompt caching creates extra savings. The system prompt with support guidelines spans 3,000 tokens.
With 90% cache discounts on repeated context, cached tokens after the first request drop to $0.08 per million for Haiku requests.
The platform also sets output limits. Support responses cap at 500 tokens to prevent unnecessary output costs while maintaining quality.
These proven strategies for reducing API spending work across different business types and volumes.
Summary & System Diagnostics
Teams need to track specific metrics to understand where their AI costs actually go.
The most important numbers to watch are cost per request, total token usage, and cache hit rate across all API calls.
Key Metrics to Monitor Daily:
- Cost per request – Shows the average spend for each API call
- Cache hit rate – Percentage of requests served from cache instead of hitting the API
- Token usage by endpoint – Identifies which features burn through the most tokens
- Rate limiting events – Tracks when applications hit provider limits
Most cloud providers offer built-in cost tracking tools.
Google Cloud Billing gives detailed breakdowns of API spending by project and service.
Teams should set up alerts when spending crosses specific thresholds.
A practical approach to tracking AI costs involves logging every API request with its token count and cost.
This data reveals patterns like which prompts cost the most or when duplicate calls happen.
Teams get the best results from cost monitoring when they check their metrics weekly.
They should look for sudden spikes in token usage or drops in cache hit rate.
These changes often signal inefficient prompts or broken caching logic.
| Metric | Good Target | Warning Sign |
|---|---|---|
| Cache hit rate | >60% | <40% |
| Cost per request | Stable or declining | Sudden increases |
| Duplicate calls | <10% of total | >20% of total |
Teams that implement token optimization strategies see measurable improvements within days.
For consultants and lean teams, the long-term advantage is not simply choosing the cheapest model. The advantage comes from designing an adaptive AI system that routes work intelligently, monitors cost continuously, and reserves premium reasoning only for the moments where it creates measurable business value.
Organizations that reduce AI API costs intelligently can scale automation systems more efficiently over time.
That is where AI cost optimization becomes more than prompt engineering. It becomes infrastructure strategy.