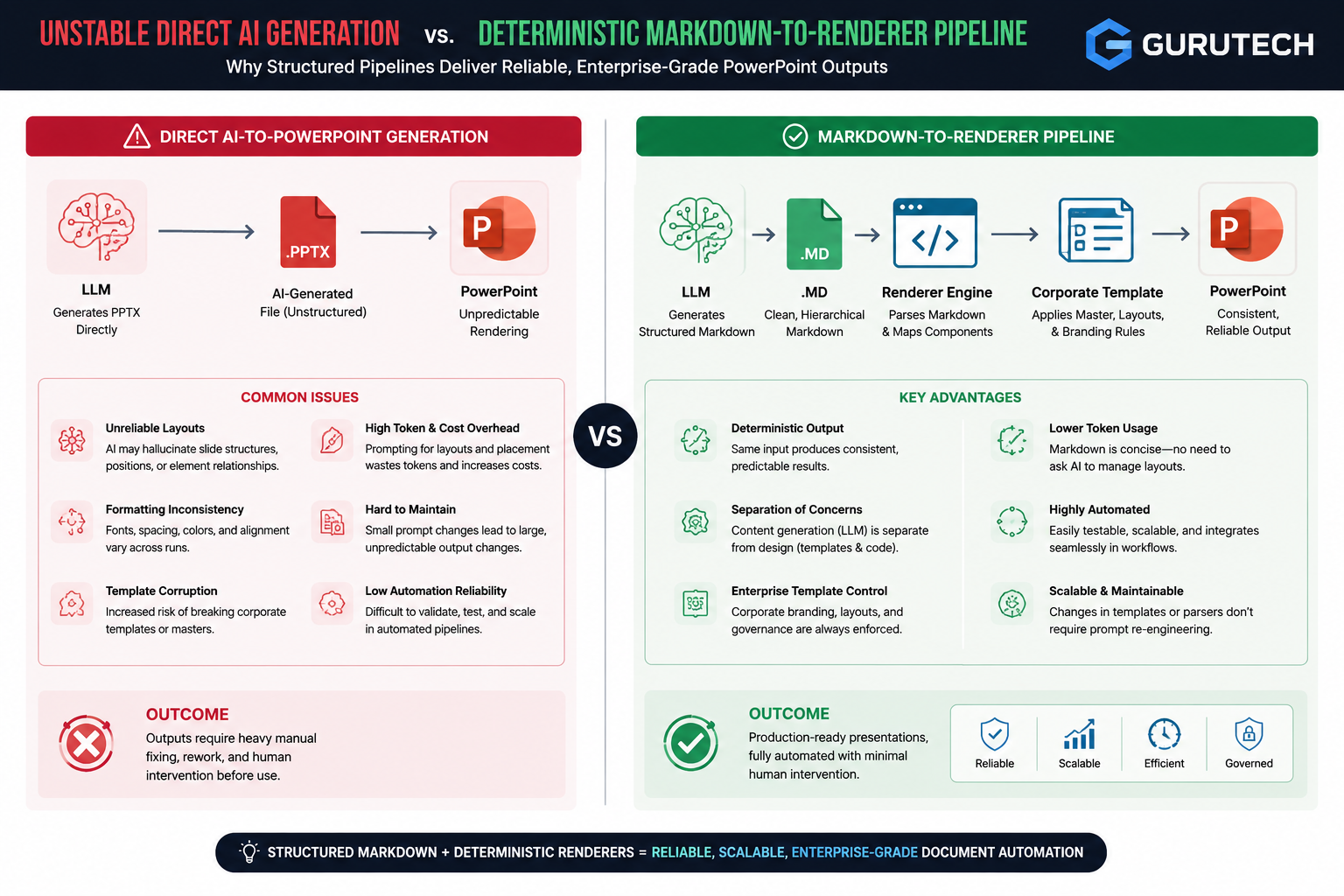
Most enterprise AI stacks today suffer from a critical last-mile gap: outputs from language models, retrieval systems, and orchestration layers still require manual formatting into presentation decks, reports, and client deliverables.
This guide continues the pipeline started in Advanced AI Document Parsing: once messy PDFs, scanned files, and enterprise reports have been converted into structured markdown, the next challenge is turning that clean AI output into native business assets such as PowerPoint decks, Word reports, and executive summaries.
Programmatic document generation eliminates this bottleneck by automating the creation of business documents directly from structured data and AI outputs, removing the need for employees to manually copy-paste content into Word files or PowerPoint slides. This infrastructure layer transforms AI systems from advisory tools into autonomous asset generators capable of producing finalized deliverables without human intervention.
The technical challenge involves bridging the gap between unstructured AI responses and rigidly formatted document templates.
While programmatic PDF generation from dynamic data has existed for years in invoice and reporting systems, modern AI workflows demand more sophisticated pipelines that can populate complex presentation structures, maintain brand governance, and handle variable-length content sections.
Implementation requires architectural decisions around template engines, rendering libraries, and integration points within existing orchestration frameworks.
Organizations implementing automated document generation workflows gain the ability to close feedback loops entirely within code, eliminating review queues where AI-generated insights wait for manual formatting.
The technical stack typically involves markdown-to-presentation converters, template versioning systems, and validation layers that ensure outputs meet enterprise quality standards before distribution.
Key Takeaways
- Programmatic document generation closes the last-mile gap in enterprise AI systems by automating the conversion of structured outputs into finalized business deliverables
- Implementation requires architectural decisions around template engines, rendering libraries, and orchestration integration points to maintain format consistency and brand governance
- Zero-human reporting loops become possible when document generation pipelines include automated validation layers and version-controlled template systems
The Copy-Paste Bottleneck in AI Automation Stacks
Over 800 million users engage with ChatGPT weekly through a repetitive workflow: prompt submission, output retrieval, application switching, and manual insertion.
This pattern persists across enterprise automation pipelines where LLM outputs require human intervention for transfer into target systems.
The architectural flaw centers on decoupled generation and insertion layers.
AI services produce text, structured data, or formatted content that remains isolated from document assembly engines.
Engineers implement workarounds through clipboard monitoring, temporary file systems, or manual API response handling.
Common integration gaps include:
- LLM APIs returning raw text requiring post-processing for document schema compliance
- Format conversion layers between AI output and document template engines
- State management failures when context spans multiple generation cycles
- Version control conflicts from asynchronous paste operations
AI output formatting introduces additional friction when generation systems lack native support for target document structures.
A model trained on markdown must undergo transformation pipelines to populate PPTX slide objects or PDF form fields.
Each conversion step adds latency and error surface area.
The shift from traditional coding bottlenecks to debugging and testing constraints demonstrates how acceleration in one pipeline stage exposes downstream limitations.
Document generation workflows exhibit identical behavior—faster content creation amplifies formatting, validation, and insertion overhead.
Production systems require programmatic handoff mechanisms that bypass manual intervention.
Direct API-to-document bindings, streaming insertion protocols, and schema-aware generation endpoints eliminate copy-paste cycles while maintaining deterministic output control.
Structural Advantages of Markdown-to-Presentation Pipelines
Markdown-to-presentation pipelines decouple content authoring from layout rendering, enabling programmatic manipulation at each transformation stage.
The Markdown processing pipeline converts source text through sequential markdown-it plugins, transforming input into presentation-ready HTML and CSS.
This architecture separates concerns between content definition, structural parsing, and visual rendering.
Version control integration operates natively since Markdown files exist as plain text.
Engineers track presentation changes through standard Git workflows without binary diff complications.
Marp’s ecosystem exports to multiple formats through single command execution, eliminating manual conversion overhead.
Key architectural benefits:
- Templating consistency: CSS themes apply uniformly across slide decks without per-slide adjustments
- Batch processing: Multiple presentations generate from parameterized Markdown sources
- API integration: Automated workflows ingest data and output slides programmatically
- Code block preservation: Syntax highlighting and formatting persist through the transformation chain
AI presentation automation leverages these pipelines for dynamic content generation.
Tools like PreGenie use multi-modal language models with Markdown-based frameworks like Slidev to produce presentation output from document inputs.
The framework’s flexibility accommodates programmatic insertion of generated content without layout recalculation overhead.
Python libraries such as MarkdownDeck provide programmatic control over Google Slides generation from Markdown sources.
Engineers define presentation structure in code while the pipeline handles layout computation and styling application.
This approach scales across enterprise environments where presentation generation integrates into larger document processing workflows.

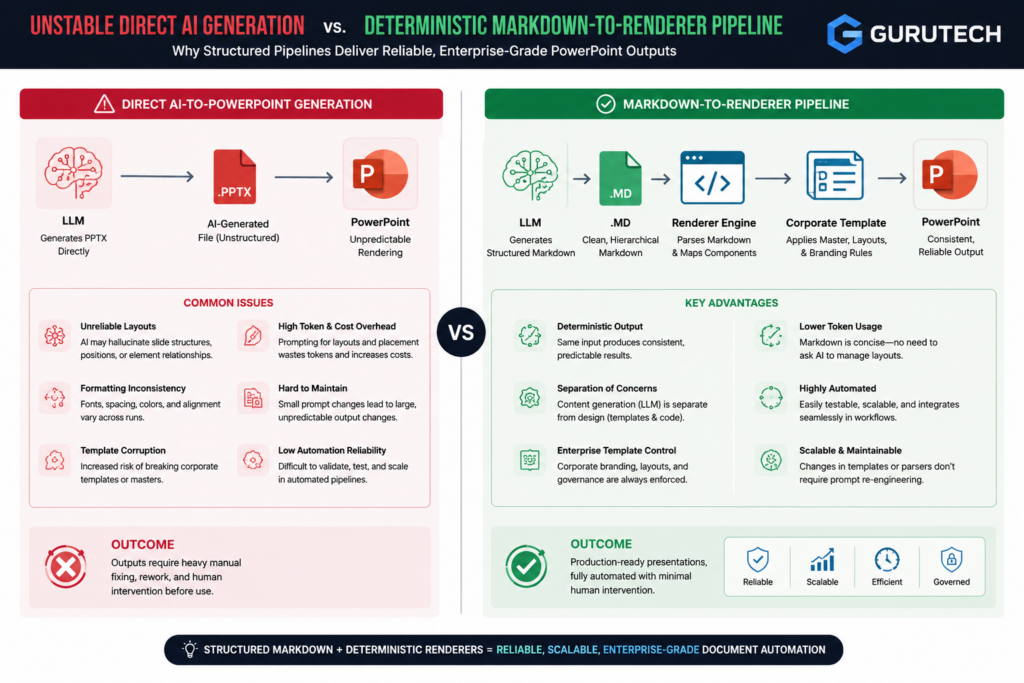
Blueprint: Architectural Layout of an Automated Document Generator
A programmatic document generator operates through four distinct layers that handle data ingestion, workflow coordination, template processing, and format conversion.
Each layer addresses specific technical requirements in enterprise document generation pipelines.
The Content Layer
The Content Layer manages data acquisition, validation, and preprocessing before documents enter the generation pipeline.
This layer connects to databases, APIs, message queues, and file systems to retrieve structured and unstructured content.
Data normalization occurs at this stage to ensure consistency across disparate sources.
The layer transforms raw inputs into standardized formats that downstream components can process reliably.
Schema validation prevents malformed data from propagating through the system.
Key responsibilities include:
- Database query execution and result set handling
- API endpoint polling and webhook processing
- File parsing for CSV, JSON, XML, and binary formats
- Data type conversion and field mapping
- Input validation against predefined schemas
For systems integrated with n8n document automation workflows, this layer often receives trigger events that initiate document generation jobs.
The Content Layer maintains connection pooling and implements retry logic for external data sources to handle transient failures without manual intervention.
The Orchestration Layer
The Orchestration Layer coordinates workflow execution, manages state transitions, and routes content through processing stages.
This layer implements the business logic that determines which templates to apply, what data transformations to execute, and how to handle conditional document sections.
Workflow engines at this level maintain execution context across asynchronous operations.
They track job status, manage dependencies between document sections, and coordinate parallel processing when multiple documents require simultaneous generation.
Core orchestration functions:
- Template selection based on document type and metadata
- Conditional logic evaluation for dynamic content inclusion
- Batch job scheduling and priority queue management
- Error handling and retry policy enforcement
- State persistence for long-running generation tasks
The orchestration layer interfaces with multi-agent architectures when semantic analysis or content retrieval requires specialized processing agents.
It maintains separation between workflow logic and rendering mechanics, enabling independent scaling of each concern.
The Rendering Layer
The Rendering Layer applies templates to processed data and generates intermediate document representations.
This layer handles layout calculations, style application, and content formatting according to the document schema definition.
Template engines at this level support variable substitution, iterative blocks for collections, and conditional segments.
The layer manages font embedding, image positioning, table generation, and page breaks to produce structured document trees.
Critical rendering operations:
| Function | Purpose |
|---|---|
| Template compilation | Parse and optimize template syntax for repeated execution |
| Variable binding | Inject data values into designated template placeholders |
| Layout computation | Calculate element positioning based on content dimensions |
| Style cascade | Apply CSS or style definitions to document elements |
| Asset resolution | Embed images, fonts, and external resources |
Programmatic layout algorithms replace static positioning rules to accommodate variable content lengths.
The rendering engine adjusts spacing, reflows text blocks, and manages overflow conditions without manual designer intervention.
The Output Layer
The Output Layer transforms intermediate document representations into target formats and handles delivery to storage systems or end users.
This layer executes format-specific serialization for PDF, DOCX, HTML, or other required outputs.
Programmatic PDF generation requires rasterization of vector elements, compression of embedded assets, and metadata injection for compliance tracking.
The layer applies digital signatures, encryption, and access controls when security requirements dictate.
Output processing includes:
- Format conversion and codec application
- Compression and file size optimization
- Metadata stamping (creation date, author, document ID)
- Digital signature application
- Delivery via file system, object storage, or API endpoints
The layer implements buffering strategies to manage memory consumption during large document generation.
It supports streaming output for progressive rendering and chunked transfers to client applications without loading entire documents into memory.
Comparative Analysis of Open-Source Document Rendering Engines
Enterprise document renderer comparison:
| Tool | Best Fit | Template Flexibility | Deployment Model | Complexity |
|---|---|---|---|---|
| python-pptx | Programmatic PowerPoint generation and slide component scripting | High for geometric layouts and corporate templates | Self-hosted Python worker | Medium |
| Pandoc | Markdown-to-DOCX and multi-format report conversion | Medium; strong for reports, weaker for complex slide geometry | CLI or containerized service | Low to Medium |
| Docxtemplater | Template-driven DOCX/PPTX generation from JSON payloads | High when business users maintain Word or PowerPoint templates | Node.js application or service | Medium |
| Carbone.io | Report automation from JSON data and office templates | High for operational reporting templates | Cloud or self-hosted options | Medium |
| PptxGenJS | Node-based PowerPoint generation for web automation stacks | High for custom slides, charts, and generated decks | Self-hosted Node worker | Medium |
Open-source PDF libraries span multiple language ecosystems with distinct architectural trade-offs for programmatic generation workflows.
PDF.js operates as a client-side rendering engine using HTML5 Canvas. This engine suits browser-based preview systems but does not support server-side batch processing.
Server-side generation requires different toolchains. pdfmake uses a declarative JSON structure for defining document layouts, enabling templated report generation through structured data mapping.
This approach scales efficiently in microservice architectures where document schemas remain consistent across invocations.
Python-Based Generation Pipelines
Python ecosystems support multiple rendering strategies beyond PDF-specific libraries. ReportLab handles direct PDF construction through programmatic APIs.
Markdown to docx automation flows through Pandoc or python-docx for DOCX generation. Template-driven workflows often chain markdown parsing with intermediate document object models before final rendering.
Engine Selection Criteria
| Requirement | Recommended Engine |
|---|---|
| Browser rendering | PDF.js |
| Templated reports | pdfmake |
| Python automation | ReportLab, python-docx |
| Multi-format output | Pandoc |
Docling represents a newer approach, combining layout analysis models with document conversion capabilities under MIT licensing. It runs on commodity hardware with controlled resource consumption, addressing deployment constraints in containerized environments.
For .NET workflows, commercial and open-source C# libraries like PuppeteerSharp and QuestPDF provide native integration points without cross-runtime dependencies.

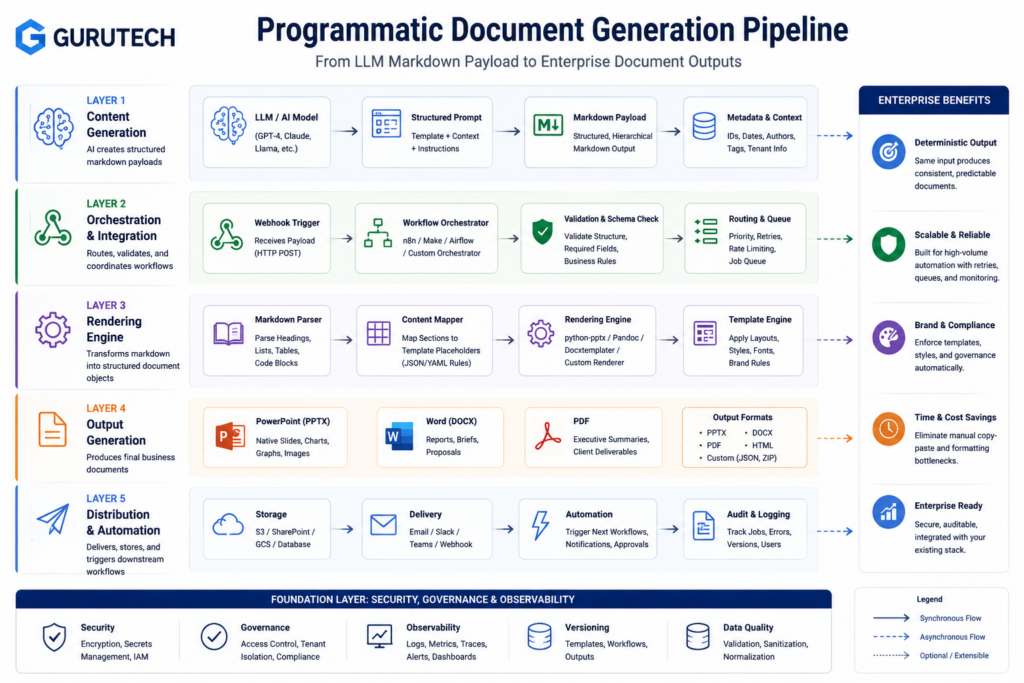
Template Governance in Enterprise Reporting Frameworks
Template governance establishes standardization protocols for document generation pipelines across distributed enterprise systems.
Organizations implementing programmatic reporting require centralized control over template versioning, access permissions, and modification workflows to prevent schema drift and maintain compliance with regulatory documentation requirements.
A governance framework template provides structured guidelines for managing template lifecycles within enterprise architecture contexts. The framework defines approval chains for template modifications, establishes audit trails for version control, and enforces naming conventions across template repositories.
Core governance components include:
- Version control integration with Git-based repositories for tracking template modifications
- Role-based access control (RBAC) limiting template editing permissions to authorized personnel
- Schema validation ensuring templates conform to organizational data models
- Dependency mapping tracking relationships between templates and data sources
- Audit logging maintaining records of template usage and modification history
Enterprise Architect documentation engines demonstrate how governance mechanisms integrate with template customization workflows. Organizations can adjust predefined templates while maintaining compliance boundaries through validation gates that verify structural integrity before deployment.
When line-of-business applications generate enterprise documents, synchronized governance processes manage template ingestion and updates from various sources. This architecture prevents template fragmentation while enabling localized customization within established parameters.
Implementation requires defining stakeholder responsibilities for template maintenance. Organizations establish review cycles for template deprecation and configure monitoring systems that flag unauthorized template modifications.
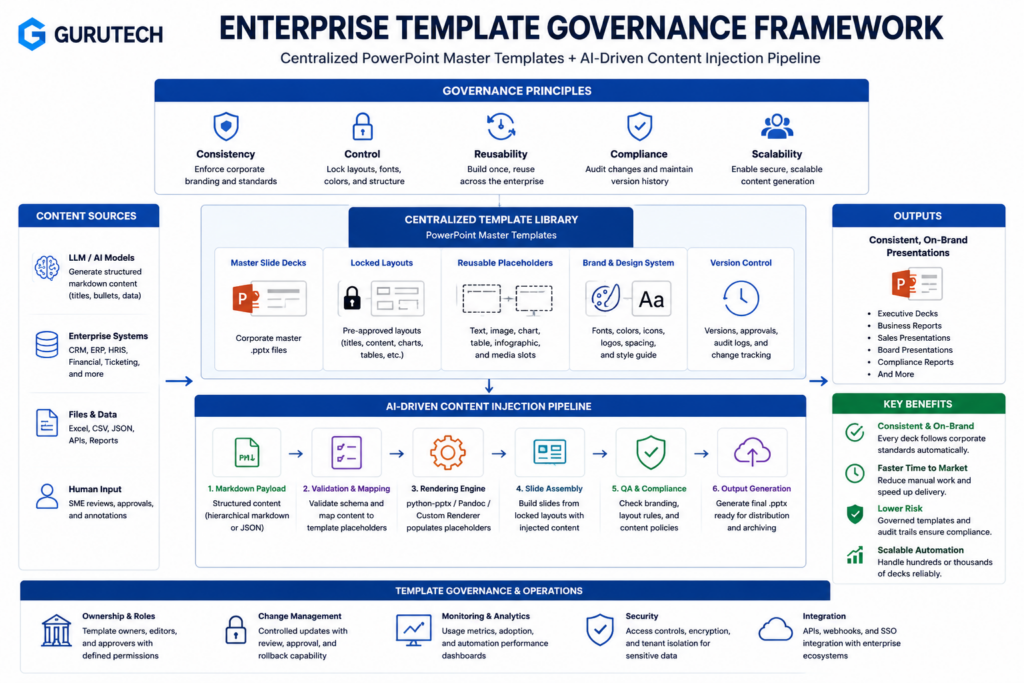
Step-by-Step Logic: Engineering a Reliable Markdown-to-PPTX Pipeline
Building a production-grade pipeline to automate markdown to PowerPoint requires structured conversion logic that handles template parsing, content mapping, and layout preservation.
Tools like python-pptx support programmatic slide generation from structured input, maintaining direct lineage between source content and rendered output.
The pipeline architecture operates in three discrete phases:
Phase 1: Template Extraction
Parse existing PPTX files to extract layout schemas, placeholder positions, and styling metadata. This creates a reusable template specification that defines slide structure independent of content.
Phase 2: Markdown Processing
Convert markdown syntax into an intermediate representation that maps headings to slide titles, lists to bullet points, and code blocks to formatted text boxes. Token-level parsing ensures accurate content segmentation.
Phase 3: PPTX Assembly
Inject processed content into template placeholders using coordinate-based positioning. The agent4ppt system demonstrates this approach through placeholder annotations that bind markdown elements to specific slide locations.
Version control integration becomes straightforward since markdown files track cleanly in git repositories. Automated PowerPoint generation pipelines benefit from separating content logic from presentation styling.
Error handling must account for template mismatches, oversized content blocks, and invalid markdown structures. Implement validation checkpoints between pipeline stages to catch conversion failures before PPTX rendering.
The md2pptx converter exemplifies this workflow by maintaining strict mapping between markdown structure and PowerPoint elements.
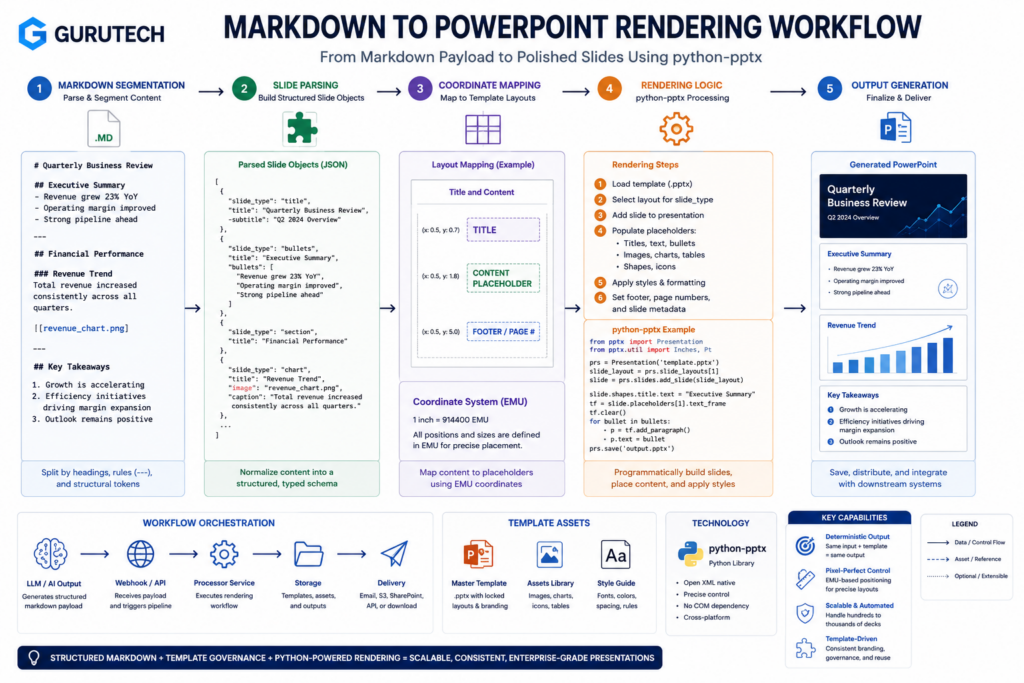
Using python-pptx for Enterprise Slide Rendering
A production markdown-to-powerpoint automation workflow usually treats the LLM output as content only. The rendering script owns the template, layout, coordinates, and corporate design rules. This separation keeps AI output formatting predictable while allowing the slide deck to remain native PowerPoint.
The following simplified python-pptx tutorial pattern shows the core rendering loop: parse structured markdown, map sections to placeholders, then save the final deck as a new asset.
from pptx import Presentation
from pptx.util import Inches
def build_deck(markdown_slides, template_path, output_path):
prs = Presentation(template_path)
title_layout = prs.slide_layouts[0]
content_layout = prs.slide_layouts[1]
for slide_payload in markdown_slides:
slide = prs.slides.add_slide(content_layout)
title = slide_payload["title"]
bullets = slide_payload.get("bullets", [])
slide.shapes.title.text = title
body = slide.shapes.add_textbox(
Inches(0.8), Inches(1.5), Inches(8.8), Inches(4.8)
)
frame = body.text_frame
frame.clear()
for item in bullets:
paragraph = frame.add_paragraph()
paragraph.text = item
paragraph.level = 0
prs.save(output_path)
# Example payload generated by an LLM or orchestration workflow
slides = [
{
"title": "Quarterly AI Operations Summary",
"bullets": [
"RAG retrieval accuracy improved after structured markdown normalization",
"Manual reporting time reduced by automated document rendering",
"Template governance preserved corporate slide standards"
]
}
]
build_deck(slides, "corporate-template.pptx", "ai-generated-report.pptx")
In production, this worker would run behind an orchestration layer such as n8n, receive a validated JSON or markdown payload by webhook, write the generated file to object storage, and return the final download link to the business workflow.
Enterprise Use Cases: Enabling Zero-Human Reporting Loops
Organizations deploy automated reporting pipelines that eliminate manual intervention between data extraction and final document delivery. These implementations target high-volume, time-sensitive workflows where consistency and audit trails matter more than creative flexibility.
Manufacturing and Supply Chain
Production facilities use agentic systems to generate shift reports, quality control summaries, and exception alerts without operator input. The autonomous execution patterns allow systems to retry failed data connections and formatting operations until document generation succeeds.
One deployment reduced report generation from six hours to under 15 minutes while saving over 24,000 planner hours annually.
Financial Services and Compliance
Risk management teams implement zero-human loops for regulatory filings, portfolio updates, and client statements. The architecture chains LLM-based extraction with template rendering engines, using tool execution patterns where Claude responds with tool_use blocks that trigger database queries, calculations, and PDF generation without human confirmation.
Healthcare Operations
Hospital systems generate patient discharge summaries, transfer documentation, and insurance pre-authorizations through fully autonomous pipelines. Multi-agent orchestration frameworks coordinate between EHR extraction, medical coding validation, and final document assembly.
The systems maintain audit logs for compliance while processing documents at sub-minute latency.
These implementations share common characteristics: structured data sources, well-defined output schemas, and deterministic validation rules that enable agents to operate without supervision.
The Future of Autonomous Asset Creation
The evolution from template-based generation to fully autonomous asset creation requires fundamental shifts in document orchestration architecture.
Automated document generation currently relies on predefined templates and structured data inputs, but emerging systems will synthesize assets from intent specifications and contextual requirements without human-defined templates.
Multi-agent architectures present the most viable path toward intelligent document generation at scale. These systems distribute document creation tasks across specialized agents that handle data retrieval, content structuring, regulatory compliance validation, and format optimization independently.
The coordination layer manages agent communication protocols and resolves conflicts between competing generation strategies.
Key architectural components include:
- Intent parsers that translate high-level requirements into executable generation pipelines
- Dynamic template synthesis engines that construct document structures from semantic models
- Validation frameworks that enforce regulatory constraints and brand consistency
- Version control systems adapted for AI-generated content lineage tracking
Asset management firms already face complex documentation requirements that demand real-time market data integration and regulatory compliance.
Autonomous systems will need to handle temporal dependencies, data provenance verification, and audit trail generation without manual intervention.
The transition from extraction-focused AI to generative intelligence shifts infrastructure requirements toward stateful orchestration platforms. These platforms must maintain context across document generations, learn from validation failures, and adapt output patterns based on downstream system feedback.
Implementation demands robust error handling for malformed outputs and fallback mechanisms when autonomous generation fails quality thresholds.
Frequently Asked Questions
Enterprise document generation systems require careful architectural decisions around template design, data integration, compliance controls, and rendering optimization to meet production-grade requirements for auditability, performance, and regulatory adherence.
What is programmatic document generation?
Programmatic document generation is the process of creating business documents automatically from structured data, markdown, JSON payloads, or AI-generated outputs. Instead of asking employees to copy text into PowerPoint, Word, or PDF templates manually, a rendering engine maps content into predefined layouts and produces native files such as .pptx, .docx, or PDF.
In enterprise AI systems, programmatic document generation usually sits after parsing, retrieval, and orchestration layers. A model generates structured markdown or JSON, an automation workflow validates the payload, and a rendering worker converts the payload into a formatted business asset. This makes reporting, compliance summaries, client decks, and executive briefings more repeatable, auditable, and scalable.
Can AI modify existing corporate PowerPoint templates directly?
AI can help generate content for existing corporate presentation templates, but the safest production architecture does not let the model directly edit slide geometry or raw PowerPoint internals. Instead, the AI produces structured markdown or JSON while a deterministic rendering layer controls the template, placeholders, fonts, colors, spacing, and slide master rules.
This architecture protects brand consistency and prevents unpredictable formatting errors. A script using python-pptx, PptxGenJS, Docxtemplater, or another rendering engine can open an approved corporate template, inject validated content into known placeholders, and save a clean output deck. The AI supplies the message; the rendering engine enforces the presentation system.
What is the best Python library for automated presentations?
For Python-based automated PowerPoint generation, python-pptx is usually the most practical starting point. It allows developers to create slides, add text boxes, insert images, manipulate placeholders, and control layout geometry using Python code.
python-pptx works especially well when teams need deterministic slide assembly from structured markdown or JSON outputs. It is not a design tool, so complex branding should still live inside a corporate master template. The Python worker should focus on mapping AI-generated content into approved slide structures. For Node-based workflows, PptxGenJS is a strong alternative; for Word reports, python-docx, Pandoc, Docxtemplater, or Carbone.io may be better choices depending on the template strategy.
How does markdown-to-powerpoint automation work?
Markdown-to-powerpoint automation usually starts with an AI model or workflow generating a structured markdown payload. Headings become slide titles, bullet lists become slide body content, tables become formatted components, and separators such as --- can mark slide breaks.
An orchestration layer such as n8n receives the markdown through a webhook, validates the structure, and sends it to a rendering worker. The worker parses the markdown into an intermediate slide array, maps each component to known coordinates or template placeholders, then saves the finished PowerPoint file. This approach separates LLM content generation from deterministic layout control, reducing formatting errors and making the pipeline easier to test, audit, and scale.
What security controls are needed for enterprise document generation?
Enterprise document generation systems need access control, tenant isolation, encryption, audit logging, and retention policies. The pipeline should validate user permissions before accessing source data, restrict templates by role, and prevent sensitive fields from entering unauthorized outputs.
For regulated workflows involving PII, PHI, financial data, or legal records, sensitive fields should be masked or tokenized before rendering when possible. Generated files should include metadata, classification labels, and immutable audit records showing which data sources, template versions, and rendering engines produced the final document. In multi-tenant environments, templates, inputs, and generated artifacts should remain isolated by customer or business unit.
Closing Thoughts: The Rise of Autonomous Business Deliverables
Programmatic document generation represents the final operational layer in modern enterprise AI systems. Organizations have already invested heavily in retrieval pipelines, orchestration frameworks, vector databases, and multi-agent reasoning architectures. The remaining bottleneck increasingly sits inside the delivery layer itself.
Most enterprise workflows still rely on humans to manually convert AI outputs into executive slides, compliance summaries, audit reports, and client-facing deliverables. That manual formatting loop creates latency, inconsistency, and operational drag across otherwise highly automated systems.Next Step in the Pipeline: Once your system generates a document, you cannot blindly trust the output without verification. Read our complete guide to selecting the best AI document generation tools to build an automated quality assurance layer.
The next generation of enterprise AI infrastructure will not stop at content generation. It will extend into deterministic rendering pipelines capable of transforming structured markdown and JSON payloads into native business assets automatically.
The organizations building competitive AI systems are no longer optimizing isolated prompts. They are engineering full-stack automation pipelines capable of transforming messy enterprise data into production-ready business deliverables with minimal human intervention.
As orchestration frameworks, template governance systems, and rendering engines mature, markdown-to-powerpoint automation and autonomous reporting pipelines will increasingly become standard infrastructure components inside enterprise operations.
If your organization still relies on manual copy-paste reporting workflows, document assembly bottlenecks, or inconsistent presentation formatting, now is the ideal time to begin designing deterministic document-generation layers into your AI stack.