Many organizations successfully deploy Retrieval-Augmented Generation (RAG) for dynamic knowledge retrieval but eventually discover that retrieval alone cannot teach a model proprietary reasoning patterns, company-specific terminology, structured output formats, or internal coding conventions.
RAG excels at surfacing relevant context from vector databases, yet the base model continues to generate responses using its pre-trained behavior rather than adapting to enterprise-specific requirements.
LoRA fine tuning architectures enable specialized LLM domain adaptation by injecting trainable low-rank matrices into transformer layers, reducing trainable parameters by 90% while changing model behavior to match proprietary workflows.
LoRA works by decomposing weight updates into smaller matrices through low-rank decomposition, which means organizations can fine-tune models on consumer GPUs rather than requiring clusters of A100s.
Full fine-tuning updates billions of parameters and demands massive infrastructure, making it prohibitively expensive for most teams.
This article examines the mathematics behind low-rank adaptation, production deployment architectures for serving multiple adapters, hyperparameter optimization strategies including rank selection and alpha scaling, QLoRA quantization for memory-constrained environments, inference patterns that merge or swap adapters at runtime, enterprise governance frameworks for versioning and evaluation, and operational blueprints for scaling LoRA across departments.
Engineers will find implementation guidance spanning PEFT configuration blocks, training pipeline design, and deployment patterns compatible with existing Kubernetes infrastructure.
Key Takeaways
- LoRA reduces trainable parameters by approximately 90% compared to full fine-tuning while maintaining model quality for domain-specific tasks
- Organizations can train and serve multiple task-specific adapters from a single frozen base model to reduce storage and memory overhead
- Production deployments require careful hyperparameter selection, adapter versioning strategies, and inference architectures that support runtime adapter swapping
The Mathematics of Parameter Efficiency: Intrinsic Rank Reduction
LoRA achieves sub-1% parameter training through matrix rank decomposition, freezing pretrained weights while injecting trainable low-rank matrices into specific transformer layers.
The technique reduces a 4.2 million parameter update matrix to 32,768 parameters using rank-8 decomposition.
Frozen Weight Matrices and Rank Decomposition
The pretrained weight matrix W₀ remains frozen during LoRA fine tuning.
Instead of updating W₀ directly, LoRA injects trainable low-rank matrices A and B that approximate the weight update ΔW.
The mathematical formulation follows:
W = W₀ + (α/r) × BA
Where W₀ represents the frozen pretrained weights, B has dimensions r × d, and A has dimensions d × r.
The rank r typically ranges from 4 to 64, with 8 being common for production deployments.
The scaling factor α/r controls adaptation strength.
Setting α equal to r maintains unit scaling, while α > r amplifies the low rank adaptation weights during inference.
The decomposition assumes weight updates contain redundant information that can be compressed into lower-dimensional subspaces.
Trainable Parameter Reduction
A standard transformer attention layer with d=2048 dimensions requires 4,194,304 parameters per weight matrix update.
LoRA with rank-8 reduces this to 32,768 parameters through the formula: n_trainable = r × (d_in + d_out).
| Configuration | Full Fine-Tuning | LoRA (r=8) | LoRA (r=16) |
|---|---|---|---|
| Query (2048×2048) | 4,194,304 | 32,768 | 65,536 |
| Key (2048×1024) | 2,097,152 | 24,576 | 49,152 |
| Value (2048×1024) | 2,097,152 | 24,576 | 49,152 |
| Total per layer | 8,388,608 | 81,920 | 163,840 |
For a 28-layer model targeting all attention projections, LoRA trains 2.3 million parameters versus 235 million for full fine-tuning.
The parameter efficiency derives from the low-rank constraint that captures task-specific adaptations in compressed subspaces.
Enterprise Compliance-Document Training Example
A financial services firm training a 7B parameter model on internal compliance documents faces memory constraints.
Full fine-tuning requires 28GB VRAM for model weights plus gradients and optimizer states, exceeding available A10 GPU capacity.
Applying LoRA with r=16 to query and value projections reduces trainable parameters to 0.12% of the model.
The adapter requires only 1.8GB additional VRAM, enabling training on commodity hardware while maintaining inference compatibility with existing Kubernetes deployments.
The compliance team stores LoRA weights separately from base model checkpoints in their vector database infrastructure.
This separation enables A/B testing between multiple domain-specific adapters without replicating the 7B base model, reducing storage costs from 140GB to 14GB across five task variants.
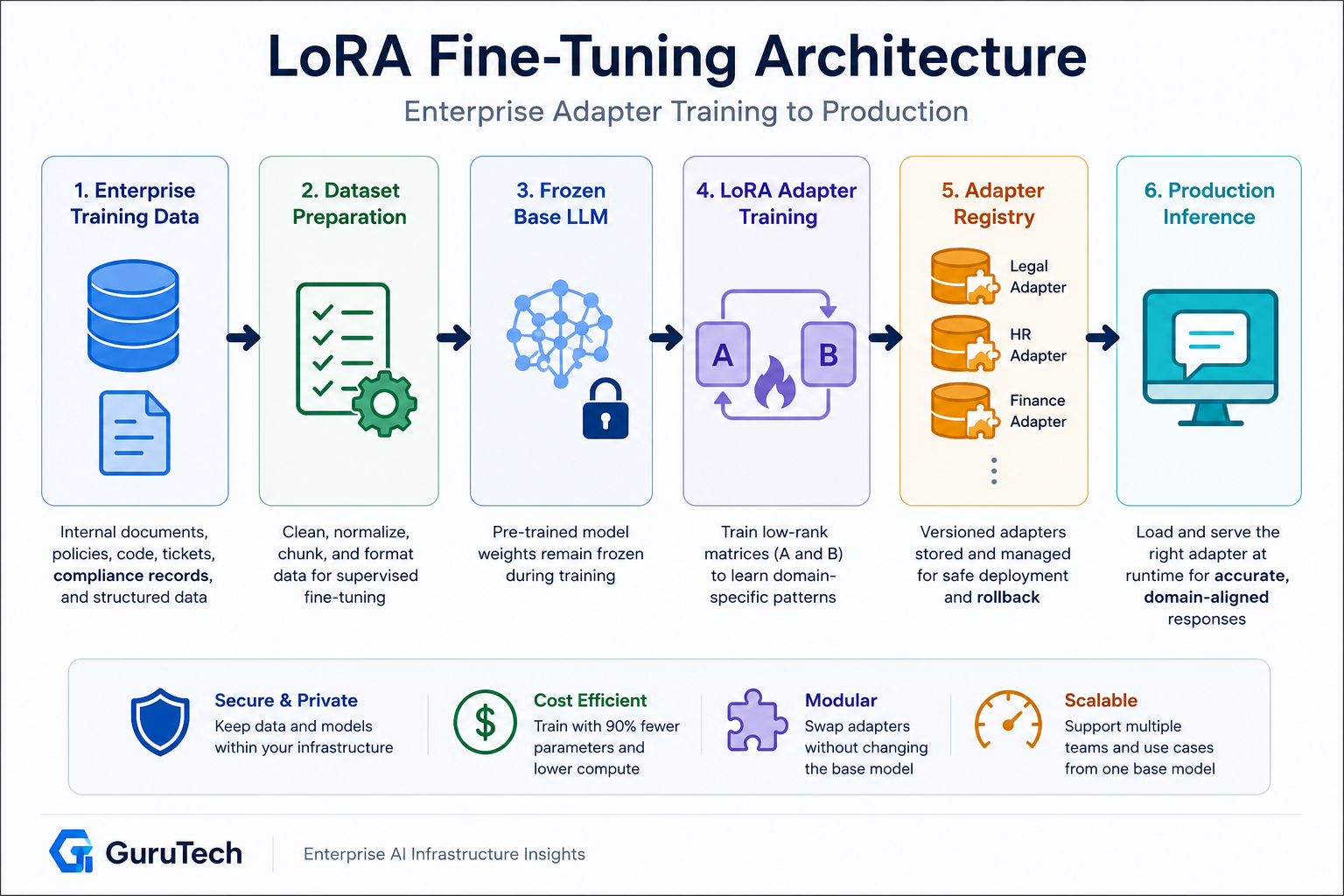
Enterprise LoRA Fine Tuning Architecture Pipeline
A production LoRA pipeline requires orchestrating data ingestion, training infrastructure, checkpoint management, and deployment automation.
Enterprise teams must balance computational efficiency with governance requirements while maintaining adapter versioning and quality gates.
Dataset Preparation and Instruction Formatting
Organizations typically maintain proprietary data across multiple silos including CRM systems, document repositories, and support ticket databases.
Engineers extract and transform this data into instruction-response pairs formatted as JSONL, where each record contains a prompt, completion, and optional metadata fields for tracking provenance.
The instruction format directly impacts adapter performance.
Most teams adopt the Alpaca format with clear demarcations like ### Instruction: and ### Response: sections, though some enterprises implement custom templates aligned with their domain terminology.
Data quality gates should validate response completeness, filter toxic content, and deduplicate near-identical examples.
Stratified sampling ensures balanced representation across business units or product lines.
A comprehensive enterprise fine-tuning guide emphasizes dataset diversity to prevent adapter overfitting to narrow use cases.
Engineers should maintain train/validation/test splits with 80/10/10 ratios, storing datasets in versioned object storage buckets with immutable timestamps.
Tokenizer Preprocessing and Supervised Training
The base model’s tokenizer must process instruction data before training begins.
Engineers configure padding strategies, truncation limits, and special token handling to match the foundation model’s specifications.
For domain-specific vocabulary like medical codes or financial instruments, teams may extend the tokenizer vocabulary, though this requires corresponding embedding layer adjustments.
Training configuration determines adapter quality and computational cost.
The rank parameter r controls LoRA matrix dimensions, typically ranging from 8 to 64 based on task complexity.
Lower ranks reduce parameters but may underfit complex enterprise domains.
Alpha values generally set to 2*r scale the adapter contribution during inference.
| Parameter | Typical Range | Enterprise Consideration |
|---|---|---|
| Rank (r) | 8-64 | Higher for specialized domains |
| Alpha | 16-128 | Usually 2x rank value |
| Dropout | 0.05-0.1 | Prevent overfitting on small datasets |
| Learning Rate | 1e-4 to 3e-4 | Lower for stability on proprietary data |
Teams implementing production LoRA fine tuning on AWS leverage distributed training across multiple GPU instances.
The PEFT library handles adapter injection into attention and MLP layers while freezing base model weights.
Gradient accumulation enables effective batch sizes that exceed single-GPU memory constraints.
Adapter Checkpoint Generation and Evaluation
Training produces adapter checkpoints at regular intervals, typically every 100-500 steps depending on dataset size.
Engineers configure automatic checkpoint saving to object storage with metadata including training step, loss metrics, and hyperparameter configurations.
Only adapter weights persist, not the full model, reducing storage requirements to tens of megabytes per checkpoint.
Evaluation runs after each checkpoint using held-out validation data.
Perplexity provides a baseline metric, but enterprise teams implement task-specific evaluations including accuracy on classification tasks or ROUGE scores for summarization.
Human-in-the-loop evaluation samples random predictions for subject matter expert review, catching edge cases that automated metrics miss.
The best checkpoint selection balances validation performance with business requirements.
Some organizations prioritize low latency and select smaller rank adapters, while others optimize purely for accuracy.
Automated evaluation pipelines gate checkpoint promotion, preventing underperforming adapters from reaching production environments.
Adapter Registry and Version Control
Enterprise teams maintain a centralized adapter registry cataloging all trained adapters with associated metadata.
This registry stores adapter identifiers, base model versions, training datasets, performance metrics, and approval status.
Engineers query the registry during deployment to retrieve the correct adapter for specific use cases.
Version control extends beyond Git to include adapter lineage tracking.
When teams retrain an adapter on updated data, the registry maintains parent-child relationships enabling rollback if the new version degrades performance.
Semantic versioning (major.minor.patch) signals breaking changes versus incremental improvements.
Access controls restrict adapter visibility based on data sensitivity.
Adapters trained on confidential financial data require elevated permissions, while general-purpose adapters remain broadly accessible.
The registry integrates with identity providers for authentication and maintains audit logs of all adapter downloads and deployments.
Deployment and CI/CD Integration
Deployment pipelines automate adapter promotion from development through staging to production environments.
Engineers define infrastructure-as-code templates specifying inference service configurations including GPU allocation, autoscaling policies, and model serving frameworks.
Cloud-native architectures for LoRA fine tuning containerize serving layers for portability across clusters.
CI/CD workflows trigger on registry events when new adapters achieve promotion criteria.
Automated tests validate adapter loading, measure inference latency, and verify output format compliance.
Canary deployments route a small percentage of traffic to the new adapter, monitoring error rates and latency before full rollout.
Production serving loads the base model once in GPU memory while swapping adapters dynamically based on request routing.
A practical LoRA fine tuning architecture implements adapter caching to eliminate cold start penalties.
Monitoring dashboards track per-adapter request volumes, P95 latency, and error rates, alerting engineers to performance degradation requiring investigation.
Hyperparameter Optimization Matrix: Rank (r), Alpha (α), and Quantization
Selecting optimal LoRA hyperparameters involves balancing parameter efficiency against model performance while managing GPU memory constraints.
Engineers must configure rank, alpha scaling, dropout, target modules, and quantization settings based on specific model architectures and available hardware resources.
| Hyperparameter Matrix Vector | Core Technical Impact | Enterprise Engineering Recommendation |
|---|---|---|
| Rank Selection (r) | Controls adapter capacity, trainable parameter count, checkpoint size, and GPU memory footprint. | Start with r=16 for general enterprise workloads; test r=32 or r=64 for legal, medical, code, or compliance-heavy domain adaptation. |
| Alpha Scaling (α) | Controls the learning weight ratio applied to low rank adaptation weights relative to the frozen base model. | Use α=2r as a practical starting point, then compare α=r and α=4r against validation accuracy and general capability retention. |
| LoRA Dropout | Regularizes adapter training by reducing overfitting on small or narrow proprietary datasets. | Use 0.05 for most production experiments; increase to 0.1 for smaller datasets and consider 0.0 for large curated datasets. |
| Target Modules | Determines which transformer projections receive trainable adapter matrices and directly affects quality, latency, and adapter size. | Begin with q_proj and v_proj; expand to k_proj and o_proj when reasoning quality or generation coherence requires more capacity. |
| 4-bit Quantization (QLoRA) | Compresses frozen base weights to NF4, increasing VRAM headroom while keeping adapters trainable. | Use QLoRA when GPU memory is the bottleneck, especially for 13B+ models or local fine-tuning infrastructure tied to vector database and RAG workflows. |
Rank Selection (r)
The rank parameter determines the dimensionality of the low-rank decomposition matrices in LoRA adapters. Different tasks require different rank configurations, with higher ranks increasing expressive power at the cost of memory and computation.
Ranks between 8 and 64 typically provide sufficient capacity for most fine-tuning tasks. A rank of 8 updates less than 1% of model parameters while maintaining competitive performance on domain-specific tasks.
Higher ranks of 64 or 128 become necessary for complex reasoning tasks or when fine-tuning larger parameter layers. The relationship between rank and parameter count scales linearly with the original weight matrix dimensions.
For a weight matrix W with dimensions d×k, LoRA introduces 2×r×(d+k) trainable parameters. Engineers working with QWen-2.5-7B models can achieve significant accuracy improvements using rank 64, which updates only 0.3% of total parameters.
Production deployments often start with rank 16 for initial experiments. They then scale to rank 32 or 64 based on validation metrics, minimizing resource consumption during hyperparameter search while maintaining flexibility for performance optimization.
Alpha Scaling (α)
The alpha parameter controls how aggressively LoRA adapter weights influence the base model during inference. The scaling factor α/r determines the magnitude of weight updates applied to frozen pretrained weights.
Common configurations set alpha equal to rank (α=r) for a scaling factor of 1.0, providing balanced adaptation strength. Engineers tune alpha independently from rank to control adapter influence without modifying parameter counts.
Setting alpha to 2×r doubles the adapter’s impact on model outputs, which proves useful when fine-tuning on small datasets where stronger signals improve convergence. The merged weight matrix becomes W’ = W + (α/r)×BA during inference, where B and A represent the low-rank decomposition matrices.
Lower alpha values (α < r) reduce adaptation strength, useful when preserving base model knowledge remains critical. Production systems typically test alpha values at r, 2r, and r/2 to identify optimal scaling for specific task requirements.
LoRA Dropout
Dropout rates between 0.05 and 0.1 prevent overfitting in LoRA adapter layers during fine-tuning. The dropout mechanism randomly zeros elements in the adapter matrices during training, forcing the model to learn more robust representations.
Engineers apply dropout exclusively to LoRA adapter weights, not to the frozen base model parameters. A dropout rate of 0.05 provides regularization benefits for most enterprise applications without significantly impacting convergence speed.
Higher dropout rates of 0.1 become necessary when training on datasets smaller than 1,000 examples. Zero dropout (disabled) often performs well when fine-tuning on large, high-quality datasets exceeding 10,000 examples.
The regularization effect becomes less critical as dataset size increases and overfitting risk decreases. Production configurations typically enable dropout during initial training phases, then evaluate whether disabling it improves final model quality.
Target Modules
Target module selection determines which transformer layers receive LoRA adapters, directly impacting parameter efficiency and model performance. Engineers typically apply LoRA to query and value projection matrices (q_proj, v_proj) in attention mechanisms as a baseline configuration.
| Configuration | Target Modules | Parameter Efficiency | Use Case |
|---|---|---|---|
| Minimal | q_proj, v_proj | Highest | Resource-constrained environments |
| Standard | q_proj, k_proj, v_proj, o_proj | Balanced | General fine-tuning tasks |
| Extended | All attention + FFN layers | Lowest | Complex reasoning tasks |
Expanding targets to include key projections (k_proj) and output projections (o_proj) increases trainable parameters by approximately 2x while improving model capacity. Full coverage of all attention and feed-forward network layers provides maximum adaptation capability but requires 4-8x more memory and training time.
Production systems serving multiple adapters concurrently benefit from minimal target configurations. The memory savings enable higher batch sizes and concurrent adapter serving, critical for multi-tenant deployments where numerous specialized models run simultaneously.
4-bit Quantization (QLoRA)
QLoRA reduces memory requirements by quantizing base model weights to 4-bit precision while maintaining full precision for LoRA adapter training. This approach enables fine-tuning of 70B parameter models on consumer GPUs with 24GB VRAM.
The quantization process compresses model weights from 16-bit floating point to 4-bit integers, achieving a 4x reduction in memory footprint. Base model weights remain frozen and quantized throughout training, while LoRA adapters train in full or half precision to maintain gradient quality.
Engineers can fine-tune models 4x larger than traditional methods allow on identical hardware configurations. QLoRA hardware requirements scale predictably with model size.
A 7B parameter model requires approximately 5-6GB VRAM in 4-bit precision, compared to 14GB for half precision. A 13B model fits in 8-10GB, while 30B models require 18-20GB.
These reductions make enterprise-grade fine-tuning accessible on single-GPU workstations rather than requiring multi-GPU clusters. The accuracy tradeoff from 4-bit quantization typically ranges from 0-2% depending on the task.
Mathematical reasoning and code generation tasks show minimal degradation, while tasks requiring precise numerical outputs may experience slightly larger accuracy reductions.
NF4 Quantization and VRAM Optimization
Normal Float 4-bit (NF4) quantization optimizes the distribution of quantized values to better match neural network weight distributions. NF4 outperforms standard 4-bit integer quantization by allocating more precision to frequently occurring weight values near zero.
The NF4 format uses a non-uniform quantization grid that places more quantization bins in the [-1, 1] range where most weights concentrate. This distribution-aware approach preserves model quality better than uniform quantization while maintaining identical memory savings.
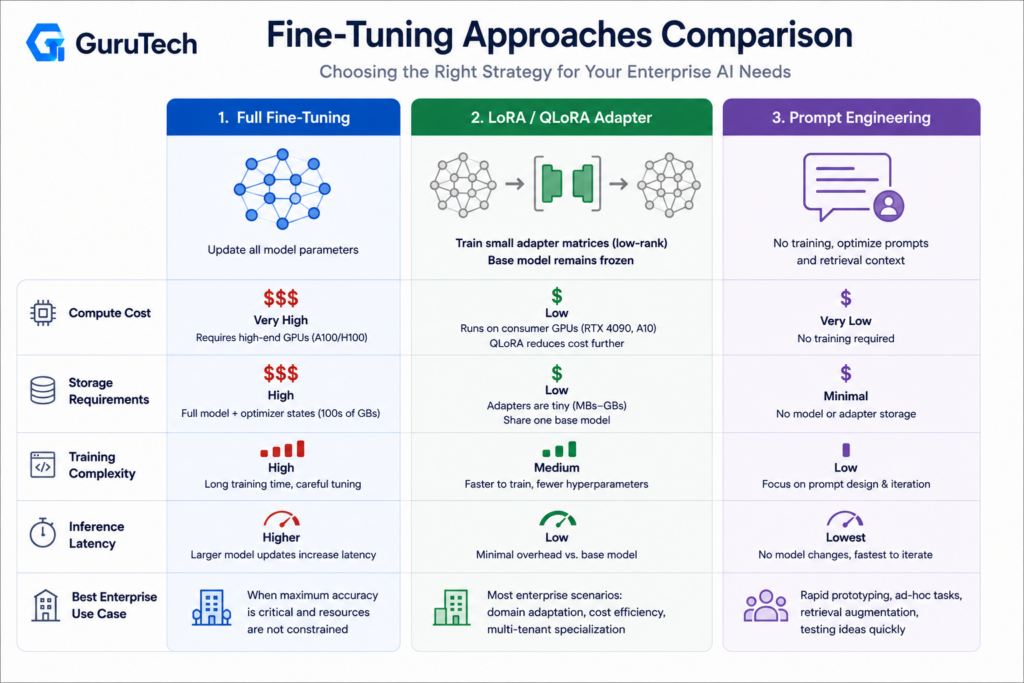
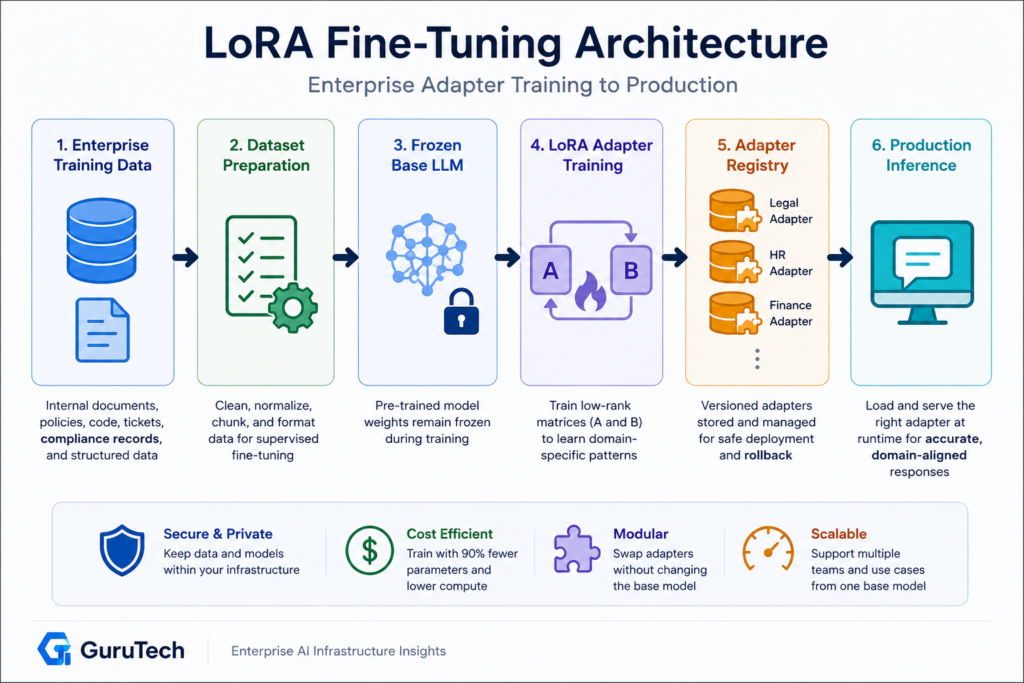
Full Fine-Tuning vs. LoRA vs. Prompt Engineering for LoRA Fine Tuning Architectures
Each approach modifies model behavior through different mechanisms with distinct resource profiles and deployment architectures. Full fine-tuning updates all parameters, LoRA injects low-rank adapters into specific layers, and prompt engineering manipulates inputs without weight changes.
| Evaluation Dimension | Full Parameter Update | LoRA/QLoRA Adapter | Prompt Context Expansion |
|---|---|---|---|
| Training Cost | Highest; requires optimizer states and multi-GPU infrastructure for larger models. | Low to moderate; trains a small adapter while the base model remains frozen. | None; no weight updates required. |
| Storage Footprint | Full model checkpoint for every specialized variant. | Small adapter files, often tens to hundreds of megabytes. | No model artifact, but prompts must be versioned and maintained. |
| Behavioral Alignment | Strongest when large datasets and budget are available. | Strong for domain adaptation, formatting, style, and task specialization. | Useful for instructions, but weaker for consistent structural behavior. |
| Inference Overhead | No adapter swap overhead, but every variant requires a full model deployment. | Minimal overhead with runtime adapters; lower latency if merged. | Higher token usage because instructions and examples travel with each request. |
| Enterprise Fit | Best for rare cases requiring complete model ownership and maximum alignment. | Best default for modular, private, department-specific LLM adaptation. | Best for prototypes, short-lived workflows, and lightweight output guidance. |
Prompt Engineering Trade-Offs
Prompt engineering requires zero parameter updates and consumes no GPU memory for training. The approach works by crafting input templates that guide model outputs through in-context learning.
Teams can iterate on prompts in minutes rather than hours required for training runs. However, prompt-based tuning keeps models fully frozen, which limits behavioral consistency across edge cases.
Token overhead from lengthy prompts increases inference costs by 20-40% compared to fine-tuned models. Context window constraints restrict the complexity of instructions that can be embedded.
Prompt engineering fails when tasks require fundamental behavior changes rather than knowledge retrieval. Multi-turn conversations with strict formatting requirements or domain-specific output structures typically demand fine-tuning.
RAG systems can supplement prompts with retrieved context but cannot modify underlying model weights to encode new patterns.
Storage and Compute Implications of Full Fine-Tuning
Full fine-tuning updates every parameter in the model, requiring optimizer states that triple memory consumption beyond the base model size. A 7B parameter model needs approximately 84GB of GPU memory during training with standard AdamW optimization.
Multi-GPU setups with DeepSpeed ZeRO-3 can distribute this load across nodes. Storage costs multiply with each task-specific model.
Organizations maintaining 10 fine-tuned variants of a 7B model store 140GB of weights compared to 14GB for LoRA adapters. Model serving infrastructure must load complete checkpoints, limiting the number of concurrent variants on shared hardware.
Full fine-tuning retains most pre-training structure in weight matrices without introducing the spectral distortions observed in LoRA approaches. This preservation makes full fine-tuning preferable for continual learning scenarios where catastrophic forgetting must be minimized.
Training times range from 6-12 hours on 8xA100 GPUs for supervised fine-tuning on 50K examples.
LoRA Adapter Modularity and Accuracy
LoRA injects trainable rank decomposition matrices into attention layers while freezing base weights. Parameter-efficient fine-tuning reduces trainable parameters by 99% compared to full fine-tuning, enabling training on single consumer GPUs.
Typical configurations use rank values between 8-64 depending on task complexity. Adapter weights occupy 10-100MB per task, enabling hot-swappable serving architectures.
Infrastructure can load a base model once and swap LoRA adapters based on request routing. This modularity supports multi-tenant deployments where hundreds of customer-specific adapters run on shared GPU pools.
Research shows LoRA introduces intruder dimensions in singular value decompositions that cause localized forgetting of pre-training knowledge. These high-ranking singular vectors accumulate during sequential fine-tuning and degrade performance in continual learning scenarios.
Scaling down intruder dimensions post-training recovers pre-training distribution modeling with minimal task performance loss. Accuracy gaps between LoRA and full fine-tuning typically stay within 1-2% on standard benchmarks.
QLoRA extends LoRA with 4-bit quantization for training 65B models on 48GB GPUs. Production teams must evaluate whether the efficiency gains justify potential accuracy trade-offs and continual learning limitations for their specific deployment patterns.
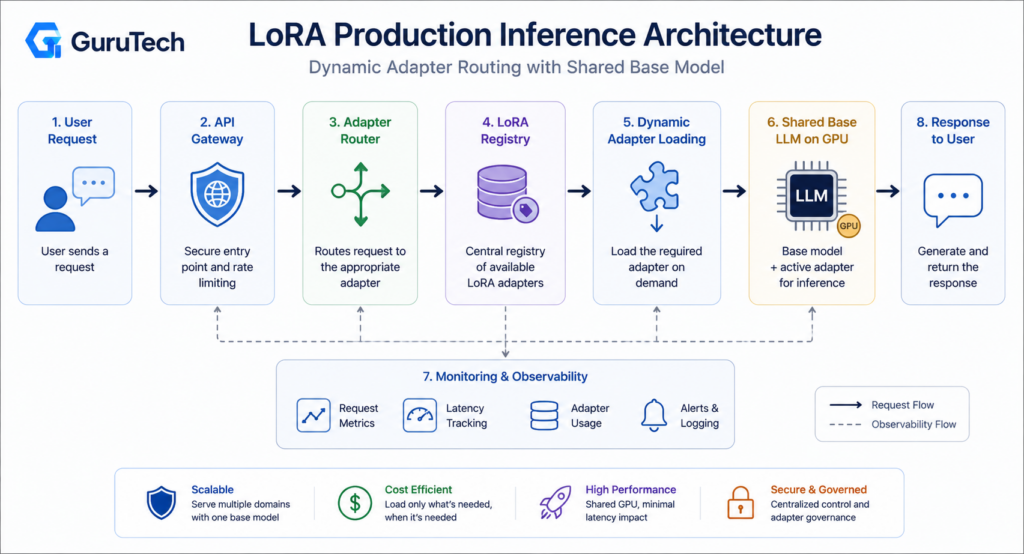
Production Inference Architecture for LoRA Fine Tuning Architectures
Deploying LoRA adapters at scale requires architectures that handle adapter routing, memory constraints, and multi-tenant workloads while maintaining low latency. Production systems must balance dynamic LoRA loading against adapter merging strategies depending on traffic patterns and resource availability.
API Gateway and Adapter Routing
The API gateway serves as the entry point for routing requests to specific LoRA adapters based on tenant identifiers, user context, or task types. Organizations typically implement routing logic through headers, query parameters, or JWT claims that map to adapter identifiers in the model registry.
A typical routing configuration includes:
| Routing Method | Use Case | Latency Impact |
|---|---|---|
Header-based (X-Adapter-ID) | Multi-tenant SaaS | <5ms |
URL path (/v1/finance/chat) | Domain-specific endpoints | <3ms |
| JWT claim extraction | User-level personalization | 10-15ms |
Gateway implementations using FastAPI or Kong can maintain adapter metadata in Redis for sub-millisecond lookups. The router must handle fallback logic when requested adapters are unavailable, either returning errors or defaulting to base models depending on SLA requirements.
Dynamic Loading and GPU Memory Management
Dynamic LoRA loading enables serving multiple adapters without duplicating the base model in VRAM. The base model remains resident in GPU memory while adapters load on-demand, typically requiring only 10-100MB per adapter compared to multi-GB base models.
Memory allocation strategies determine performance characteristics. Pinned adapters for high-traffic tenants stay loaded, while cold adapters trigger loading penalties of 100-500ms on first request.
Engineers typically allocate 20-30% of VRAM for adapter caching based on request patterns. PEFT library implementations use efficient state dict merging during inference.
The system loads adapter weights and applies them to targeted modules without full model reloading. This maintains throughput above 100 tokens/second for typical 7B parameter models on A100 GPUs.
Adapter Cache and Model Registry
The adapter cache operates as an LRU store managing which adapters remain in GPU memory versus cloud storage. Production deployments maintain hot adapters (top 20% by request volume) loaded while evicting cold adapters to S3 or GCS after configurable idle periods.
Registry systems track adapter versions, metadata, and performance metrics. Organizations implementing production LoRA pipelines store:
- Adapter checksums and lineage
- Target base model versions
- Validation metrics and A/B test results
- Access control policies per tenant
Cache warming strategies preload anticipated adapters during deployment cycles. Systems monitoring request patterns can predict which adapters to load during off-peak hours, reducing cold-start latencies during business hours.
Multi-Tenant Inference with vLLM and Ollama
vLLM provides efficient LoRA adapter serving through continuous batching and paged attention mechanisms that handle multiple adapters concurrently. The framework supports dynamic batching across tenants while swapping adapter weights between requests with minimal overhead.
Ollama offers simpler deployment patterns for lower-scale workloads with built-in adapter management. Teams running fewer than 50 adapters often choose Ollama for its ease of deployment, while enterprises exceeding 100 concurrent adapters typically migrate to vLLM for superior throughput.
Both frameworks support adapter multiplexing where a single request batch contains queries for different adapters. vLLM achieves this through KV cache partitioning and weight-swapping during attention computation, maintaining 80-90% of baseline throughput even with 10+ active adapters.
Kubernetes, KServe, and Adapter Merging
KServe deployments orchestrate adapter lifecycle management through custom resources defining adapter specifications and autoscaling policies. Engineers define InferenceService manifests that reference adapter storage locations and configure distributed training and serving architectures.
Adapter merging permanently fuses LoRA weights into base model parameters, eliminating runtime loading overhead. Merged adapters sacrifice multi-tenancy for single-tenant deployments prioritizing absolute lowest latency, reducing inference time by 15-25% compared to dynamic loading.
HorizontalPodAutoscaler configurations monitor adapter-level metrics rather than just pod-level CPU/memory. Custom metrics from Prometheus track per-adapter request rates, queue depths, and P95 latencies to trigger scaling decisions that provision additional replicas with preloaded adapter caches.
Runtime Adapter Loading Versus Merged Adapters
Runtime adapter loading maintains flexibility for multi-tenant scenarios where hundreds of adapters serve different customers or use cases. This approach optimizes VRAM utilization but accepts latency penalties during cold starts and adapter transitions between requests.
Merged adapters deliver optimal performance for dedicated deployments. Organizations running financial analysis workloads or medical diagnosis systems often deploy merged adapters in isolated pods, accepting higher infrastructure costs for guaranteed sub-100ms P99 latencies.
The decision matrix depends on tenant count and traffic patterns:
Runtime loading: 50+ adapters, variable traffic, shared infrastructure
Merged adapters: <10 adapters, consistent high-volume traffic, strict SLAs
Hybrid architectures merge top-3 adapters while dynamically loading long-tail adapters. This balances cost efficiency with performance for the majority of requests while maintaining comprehensive adapter coverage.
Enterprise Best Practices for LoRA Fine Tuning Architectures
Organizations deploying LoRA adapters at scale require standardized workflows for versioning, tracking experiments, managing registries, implementing safe rollbacks, enforcing governance, and monitoring production performance.
Adapter Naming Conventions and Semantic Versioning
Adapter artifacts should follow a hierarchical naming schema that encodes model base, domain, task, and version. A production-grade convention includes {base_model}/{use_case}/{task}/v{major}.{minor}.{patch} such as llama-3.1-8b/finance/sentiment/v2.1.0.
Major versions indicate breaking changes in input/output schema, minor versions represent performance improvements or dataset updates, and patches address bug fixes. Teams should store adapter metadata alongside weights in a JSON manifest.
This manifest captures base model hash, target modules, rank, alpha, training dataset fingerprint, and evaluation metrics. The manifest enables reproducibility and prevents version drift when multiple teams fine-tune variants of the same base model.
Git-based version control for adapter configurations works well with PEFT techniques enterprise workflows. Configurations stored as YAML or JSON files allow pull request reviews before training runs, ensuring hyperparameter choices align with organizational standards.
Experiment Tracking and MLflow
MLflow serves as the de facto experiment tracking system for LoRA training runs. Engineers should log rank, alpha, learning rate, batch size, gradient accumulation steps, and target modules as parameters.
Metrics including training loss, validation perplexity, task-specific F1 scores, and inference latency must be logged at regular intervals. Artifact logging extends beyond final adapter weights.
Teams should store training curves, sample predictions from validation sets, and merged model checkpoints at key epochs. This enables post-training analysis when adapters underperform in production or exhibit unexpected behavior.
Integration with dataset versioning tools like DVC ensures reproducibility. Each experiment links to a specific dataset commit hash, preventing scenarios where teams cannot reproduce results due to data drift.
The combination of MLflow for experiments and DVC for data creates a complete lineage graph from raw data to deployed adapter.
Model Registry and Evaluation Automation
A centralized model registry acts as the promotion pipeline for LoRA adapters. Adapters progress through stages: Development, Staging, Production, and Archived.
Promotion gates between stages enforce automated evaluation thresholds that adapters must pass before advancing.
| Stage | Criteria | Automated Checks |
|---|---|---|
| Development | Training complete, basic validation pass | Loss convergence, no NaN weights |
| Staging | Benchmark thresholds met | MMLU delta <3%, task metric >baseline |
| Production | A/B test winner, security scan clear | Human eval approval, no PII leakage |
| Archived | Superseded by newer version | Retention policy enforced |
Evaluation automation runs on every adapter commit. Fine-tuning specialized LLMs requires validating that adapters maintain general knowledge while improving task performance.
Automated scripts compare new adapters against the current production champion on held-out test sets and domain-specific benchmarks.
Rollback Strategy and A/B Testing
Production deployments should support instant rollback to previous adapter versions. Using a feature flag system, engineers can route traffic percentages to different adapter versions without redeploying inference services.
A typical rollout allocates 5% of traffic to a new adapter, monitors for 24 hours, then scales to 50% and finally 100% if metrics remain stable. Shadow mode testing runs new adapters alongside production versions without exposing outputs to end users.
The system logs both responses, allowing offline comparison of quality metrics, latency distributions, and failure modes. This de-risks adapter updates by detecting regressions before they impact users.
Kubernetes-native deployments leverage adapter sidecars or init containers that download weights from object storage at pod startup. Version pinning in deployment manifests ensures consistent adapter loading across replica sets.
When rollbacks occur, updating the manifest and triggering a rolling restart reverts all pods to the previous adapter within minutes.
Governance, Security, and Audit Logging
Enterprise LoRA deployments require audit trails that capture who trained which adapter, on what data, and when it was promoted to production. Every adapter training job should emit structured logs containing user identity, dataset provenance, hyperparameters, and approval chain.
These logs integrate with SIEM systems for compliance reporting. Data sanitization pipelines must scan training datasets for personally identifiable information, proprietary code, or regulated content before fine-tuning begins.
Automated scanning tools flag suspicious patterns, triggering human review before training proceeds. Adapters trained on non-compliant data never reach the model registry.
Operational best practices for PEFT emphasize access control for adapter artifacts.
Role-based permissions restrict who can train, promote, or deploy adapters to production environments. Encryption at rest and in transit protects adapter weights, which may encode sensitive domain knowledge from training data.
Production Monitoring
Post-deployment monitoring tracks adapter-specific metrics beyond standard API health checks. Key indicators include perplexity drift over time, refusal rate increases, average response length changes, and entity extraction accuracy degradation.
Dashboards visualize these metrics per adapter version, enabling rapid identification of performance regressions. Anomaly detection alerts fire when adapter behavior diverges from established baselines.
A sudden spike in repetitive outputs, incoherent responses, or timeout errors triggers automatic traffic shifting to a stable fallback adapter. Human-in-the-loop review follows to diagnose whether the issue stems from distribution shift, adversarial inputs, or adapter defects.
Cost monitoring becomes critical when organizations deploy dozens of adapters across multiple inference endpoints. Tracking GPU utilization, request latency percentiles, and cost per inference per adapter informs optimization decisions.
Teams often discover that merging multiple low-traffic adapters into a single multi-task adapter reduces infrastructure costs without sacrificing quality.
Common Mistakes When Building LoRA Fine Tuning Architectures
LoRA implementations fail in production due to rank misconfiguration, improper layer targeting, and dataset quality issues. Organizations often deploy adapters without proper validation infrastructure or observability, leading to silent performance degradation at scale.
Selecting Incorrect Rank Values
Engineers commonly set LoRA rank values without empirical validation, defaulting to r=8 or r=16 across all layers. This approach wastes compute resources on attention layers that require higher ranks while over-parameterizing feed-forward projections that perform well at r=4.
Task complexity determines optimal rank selection. Domain adaptation for medical terminology typically requires r=32 to r=64, while instruction following often achieves equivalent performance at r=8 to r=16.
Teams should benchmark multiple rank values against held-out validation sets before committing to production training runs. Critical LoRA assumption mistakes emerge when organizations apply uniform ranks across heterogeneous model architectures.
A 7B parameter model may reach optimal performance at r=16, while the same task on a 70B model requires r=8 due to increased base model capacity. Memory constraints in multi-tenant serving environments further complicate rank selection, as higher ranks increase adapter loading time and GPU memory footprint.
Targeting Incorrect Layers
Production teams frequently apply LoRA to all attention layers by default, ignoring task-specific requirements.
Query and value projections capture most task-specific knowledge for classification tasks, while key projections contribute minimally to performance gains.
Targeting strategies must align with downstream objectives:
- Instruction tuning: Apply LoRA to query, key, value, and output projections
- Domain adaptation: Focus on query and value matrices with selective feed-forward targeting
- Style transfer: Prioritize output projections and final layer norms
- Function calling: Target all attention layers plus the first and last feed-forward blocks
Layer selection impacts inference latency in multi-adapter deployments.
Each additional targeted layer increases adapter swap time by 15-30ms on standard GPU infrastructure.
Organizations running hundreds of adapters must balance performance gains against serving throughput requirements.
Overfitting and Poor Datasets
Small enterprise datasets with fewer than 1,000 examples consistently produce adapters that memorize training data rather than generalizing.
Teams observe perfect training accuracy alongside catastrophic validation performance, particularly when fine-tuning on internal documentation or customer support tickets.
Dataset quality determines adapter viability more than quantity.
A curated set of 500 diverse examples outperforms 10,000 repetitive samples drawn from a narrow distribution.
LLM fine-tuning mechanics and common pitfalls include insufficient negative examples, which cause models to hallucinate confident responses for out-of-distribution queries.
High learning rates (>3e-4) combined with extended training epochs amplify overfitting.
Engineers should implement gradient clipping, reduce learning rates to 1e-4 or 2e-4, and monitor validation loss every 50-100 steps.
Early stopping based on validation perplexity prevents adapter degradation during extended training runs.
Insufficient Validation and Early Adapter Merging
Organizations merge LoRA adapters into base models before conducting thorough evaluation across edge cases.
This premature optimization eliminates the flexibility to swap adapters based on request routing or A/B testing requirements.
Validation must extend beyond standard benchmarks to include:
- Adversarial inputs that probe model boundaries
- Production traffic replay against historical request logs
- Latency profiling under concurrent load
- Memory consumption during multi-adapter serving
Teams deploying merged adapters sacrifice runtime adapter selection capabilities.
Separate adapter serving enables dynamic routing based on user context, request metadata, or real-time performance metrics.
The inference overhead of unmerged adapters (5-8% latency increase) proves negligible compared to the operational flexibility gained.
Quantization Incompatibilities
QLoRA training with 4-bit quantization produces adapters that degrade when applied to full-precision base models.
Engineers encounter unexpected perplexity increases and output quality regressions when moving quantized training artifacts to production serving infrastructure.
Quantization schemes must remain consistent across training and inference environments.
An adapter trained against a GPTQ-quantized base model requires the same quantization format at serving time.
Mixed-precision deployments introduce numerical instabilities that compound across decoder layers, particularly in models exceeding 13B parameters.
Enterprise LLM fine-tuning decisions require alignment between training infrastructure and production deployment targets.
Teams using QLoRA for cost efficiency during development must either deploy quantized models in production or retrain adapters against full-precision checkpoints before launch.
Deployment Without Observability
Production LoRA deployments fail silently when teams lack adapter-specific monitoring infrastructure.
Standard LLM metrics fail to capture adapter-level performance degradation, especially in multi-tenant environments serving dozens of specialized adapters.
Critical observability requirements include:
- Per-adapter latency distributions to identify slow performers
- Token-level perplexity tracking for quality regression detection
- Adapter loading and eviction rates in dynamic serving systems
- Memory allocation patterns across adapter lifecycle events
Organizations running multiple adapters must implement request tagging that propagates adapter identifiers through distributed tracing systems.
This enables correlation between specific adapters and downstream service failures, user complaints, or accuracy regressions detected through human-in-the-loop evaluation pipelines.
Adapter versioning becomes critical as teams iterate on training datasets and hyperparameters.
Shadow deployments that route production traffic to multiple adapter versions simultaneously enable controlled rollouts and rapid rollback when performance issues emerge.
Code-Level Implementation: PEFT Config Block
The Hugging Face PEFT library centralizes LoRA configuration through the LoraConfig class, which defines rank dimensions, scaling factors, and target module selection before adapter injection.
Parameter reporting confirms the efficiency gain by showing the ratio of trainable to frozen weights.
Python Example for LoraConfig
The LoraConfig object serves as the primary interface for configuring LoRA fine tuning parameters in production environments.
Engineers specify the rank (r), alpha scaling factor (lora_alpha), dropout rate, and bias handling within this configuration block.
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# base_model initialization assumed for production-grade clean script
model = get_peft_model(base_model, peft_config)
model.print_trainable_parameters()
The rank parameter controls the bottleneck dimension of the low-rank matrices, with values between 8 and 64 common for production deployments.
The alpha value typically scales at 2x the rank to maintain gradient stability during training.
Target Modules Explanation
Target modules define which linear layers receive LoRA adapter injection.
Attention mechanisms (q_proj, k_proj, v_proj, o_proj) represent the highest-value targets for most language model architectures, as these projections carry the majority of the model’s representational capacity.
| Module Type | Impact | Memory Cost |
|---|---|---|
| Query/Key/Value | High | Medium |
| Output Projection | High | Low |
| MLP Layers | Medium | High |
| Layer Norms | Minimal | Minimal |
Engineers can expand coverage to MLP layers (gate_proj, up_proj, down_proj) when domain shift requires deeper adaptation.
The wrapper pattern for linear layers allows selective injection without architectural modifications.
Production systems often start with attention-only targeting to validate the fine-tuning pipeline before expanding scope.
This approach balances adaptation capability against memory constraints in containerized deployments.
Adapter Injection
The get_peft_model() function wraps the base model with LoRA adapters at specified target modules.
This operation freezes the original weights while initializing trainable low-rank matrices alongside each targeted layer.
Adapter injection creates a parallel computational path where input activations pass through both the frozen pretrained weights and the trainable LoRA matrices.
The outputs merge through addition, scaled by the lora_alpha/r ratio to maintain activation magnitudes.
# Verify adapter structure
for name, module in peft_model.named_modules():
if "lora" in name.lower():
print(f"{name}: {module}")
Engineers must confirm adapter placement in distributed training environments where model sharding splits layers across devices.
The PEFT library handles device mapping automatically when device_map="auto" is specified at model loading.
Trainable Parameter Reporting
The print_trainable_parameters() method quantifies the efficiency gain from LoRA adaptation.
Production systems typically achieve 0.1-1% trainable parameter ratios compared to full fine-tuning.
peft_model.print_trainable_parameters()
# Output: trainable params: 4,194,304 || all params: 6,738,415,616 || trainable%: 0.0622
This metric directly correlates with training memory requirements and checkpoint sizes.
A 7B parameter model with rank-16 LoRA adapters generates checkpoints under 100MB, enabling rapid model versioning in CI/CD pipelines.
The trainable percentage informs resource allocation decisions for Kubernetes deployments.
Engineers can calculate GPU memory requirements by estimating optimizer state size at roughly 2x the trainable parameter count in mixed-precision training.
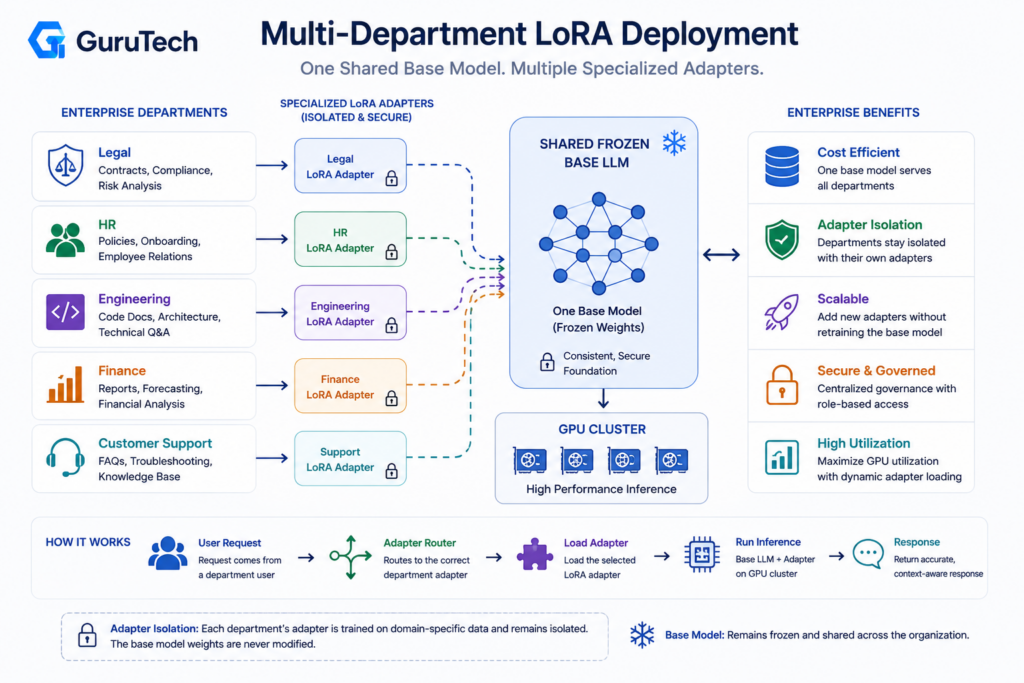
Summary: Scaling LoRA Fine Tuning Architectures Across the Enterprise
Enterprise LoRA deployments require dynamic adapter loading systems that serve multiple department-specific models from shared base weights, reducing GPU memory overhead by 70-90% compared to deploying separate full models.
Organizations implement hot-swap adapter serving to handle concurrent requests across legal, finance, and customer service departments while maintaining sub-100ms latency.
Department-Specific Adapters and Dynamic Loading
Teams deploy base models once and load department adapters on-demand using frameworks that support multi-LoRA serving architectures.
A legal department adapter trained on contract analysis loads alongside a finance adapter for earnings call summarization, both sharing the same 70B parameter base model in VRAM.
The adapter registry maps department requests to specific LoRA weights stored in vector databases or object storage.
Engineers configure adapter batching to serve 8-32 concurrent adapters per GPU, with weights pre-loaded into GPU memory for frequently accessed departments.
Cold adapters load from disk in 50-200ms depending on rank and target modules.
Production systems implement adapter versioning through semantic tags tied to evaluation metrics.
Each department maintains multiple adapter versions—production, staging, and experimental—with A/B testing routing 5-10% of traffic to candidate adapters.
Governance teams enforce human-in-the-loop approval before promoting adapters that affect compliance-sensitive outputs.
| Department | Rank | Target Modules | Adapter Size | Load Time |
|---|---|---|---|---|
| Legal | 64 | q_proj, v_proj, o_proj | 180 MB | 85 ms |
| Finance | 32 | q_proj, v_proj | 95 MB | 45 ms |
| Support | 16 | q_proj, v_proj | 48 MB | 25 ms |
GPU Utilization Improvements
QLoRA implementations enable 7B model fine-tuning on consumer GPUs by quantizing base models to 4-bit precision while maintaining adapters in higher precision formats.
A single A100 80GB serves 12-16 department adapters simultaneously at batch size 32, compared to 2-3 full models with traditional fine-tuning.
Adapter merging strategies convert trained LoRA weights back into the base model for departments requiring maximum throughput without adapter overhead.
Teams merge weights offline and deploy as separate endpoints when inference volume exceeds 10,000 requests per hour for a single department.
This trades memory efficiency for raw speed in high-traffic scenarios.
Memory profiling reveals that rank 32 adapters consume 85-120 MB per adapter across q_proj and v_proj modules in LLaMA-based architectures.
Engineers allocate GPU memory budgets by profiling peak concurrent department loads during business hours, reserving 20% headroom for traffic spikes.
Kubernetes horizontal pod autoscaling triggers new inference pods when adapter queue depth exceeds 50 pending requests.
Future Trends: DoRA, QLoRA, AdapterFusion, MoE
DoRA architectures separate magnitude and direction components during training, closing performance gaps with full fine-tuning while maintaining parameter efficiency.
Early enterprise adoption shows 2-4% accuracy improvements over standard LoRA on domain-specific benchmarks, particularly in financial forecasting and medical coding tasks.
AdapterFusion enables learning weighted combinations of multiple department adapters for cross-functional use cases.
A procurement system combines legal, finance, and supply chain adapters with learned attention weights, extracting contract terms while validating budget constraints and supplier risk scores in a single forward pass.
Mixture-of-Experts routing layers select department-specific adapters dynamically based on input content rather than explicit routing rules.
The router network learns to activate legal adapters for contract clauses and HR adapters for policy questions within the same conversation thread.
This eliminates manual adapter selection logic while supporting organic knowledge sharing across organizational boundaries.
Research teams evaluate rank-stabilized LoRA variants that scale to ranks above 256 without training instabilities, enabling higher-capacity adapters for complex multi-step reasoning tasks.
Production deployments balance adapter capacity against serving latency, with most enterprise use cases optimal between rank 16-64 based on task complexity and available inference budget.
Frequently Asked Questions
What rank should I choose for LoRA fine tuning architectures?
Start with r=16 for most enterprise instruction-tuning and domain-adaptation workloads.
Use r=8 for lightweight formatting or classification tasks, and test r=32 or r=64 when the adapter must learn complex legal, medical, code, or compliance patterns.
The correct rank should be selected through validation, not intuition, because rank selection parameter efficiency depends on task complexity, dataset quality, and base model capability.
Is QLoRA better than standard LoRA?
QLoRA is better when VRAM is the limiting factor because it quantizes the frozen base model to 4-bit NF4 while training LoRA adapters in higher precision.
Standard LoRA is simpler and usually faster when enough memory is available.
For production, teams should keep quantization consistent between training and inference to avoid quality regressions.
Can multiple LoRA adapters run together?
Yes, multiple adapters can be managed through dynamic adapter loading, adapter routing, or adapter composition techniques.
Most enterprise deployments route each request to one department-specific adapter, such as Legal, HR, Finance, or Support.
Advanced systems may combine adapters using methods such as AdapterFusion or route requests through a learned selection layer.
How large is a LoRA adapter?
Most LoRA adapters are small compared with the base model, often ranging from tens to hundreds of megabytes.
The size depends on rank, target modules, model hidden dimension, number of layers, and precision.
This small footprint is why enterprise teams can maintain many specialized LLM domain adaptation profiles without storing a full model copy for each use case.
Can LoRA replace RAG?
No. LoRA and RAG solve different problems.
RAG retrieves dynamic knowledge from documents, vector databases, and business systems, while LoRA changes model behavior, terminology, formatting, and task-specific patterns.
The strongest enterprise architecture often combines both: RAG for current knowledge and LoRA for specialized behavior.
Which layers should be targeted first?
Start with q_proj and v_proj because they usually provide the strongest quality-to-parameter ratio.
Add k_proj and o_proj when generation coherence or reasoning behavior requires more capacity.
Consider MLP modules only when the task requires deeper domain reasoning and the infrastructure can absorb the larger adapter size.
Does LoRA work with Llama models?
Yes. LoRA is commonly used with Llama-family models through Hugging Face PEFT, Axolotl, TRL, and other fine-tuning stacks.
The exact target module names depend on the model architecture.
For Llama-style models, common targets include q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, and down_proj.
Can LoRA run on consumer GPUs?
Yes, especially for 7B and 13B models when using QLoRA, gradient accumulation, mixed precision, and efficient batch sizing.
QLoRA hardware requirements are significantly lower because the frozen base model is loaded in 4-bit precision.
Larger models still benefit from workstation or cloud GPUs, but LoRA makes experimentation practical without full fine-tuning infrastructure.
What is AdapterFusion?
AdapterFusion is a technique for combining multiple trained adapters rather than selecting only one adapter at inference time.
It is useful when a workflow requires several specialized capabilities, such as legal reasoning, finance validation, and procurement language in the same response.
It adds orchestration complexity, so most enterprise teams should start with explicit adapter routing before moving to adapter fusion.
When should full fine-tuning be used instead of LoRA?
Full fine-tuning is appropriate when the organization needs maximum model alignment, owns a very large high-quality training corpus, and can support high GPU, storage, evaluation, and deployment costs.
It may also be justified when adapters cannot achieve the required task quality or when the model must become a single standalone artifact.
For most enterprise workloads, LoRA fine tuning architectures provide a better balance of cost, control, modularity, and operational scalability.
Final Thoughts
LoRA fine tuning architectures give enterprise teams a practical way to modify model behavior without duplicating or retraining entire foundation models.
The strongest production systems treat adapters as governed software artifacts: versioned, evaluated, routed, monitored, and rolled back through the same discipline used for critical infrastructure.
Which target modules, rank values, or deployment architecture has produced the best results in your environment? Share your experience in the comments below.