Single-agent AI systems and linear RAG pipelines fail when enterprise workflows require coordination across multiple decision points, iterative refinement, or dynamic task delegation.
A chatbot that retrieves documents and generates responses works for simple queries, but breaks down when the task involves validating outputs, routing exceptions, or orchestrating approval chains across departments.
Linear architectures cannot handle the cyclic dependencies, conditional branching, and stateful coordination that production systems demand.
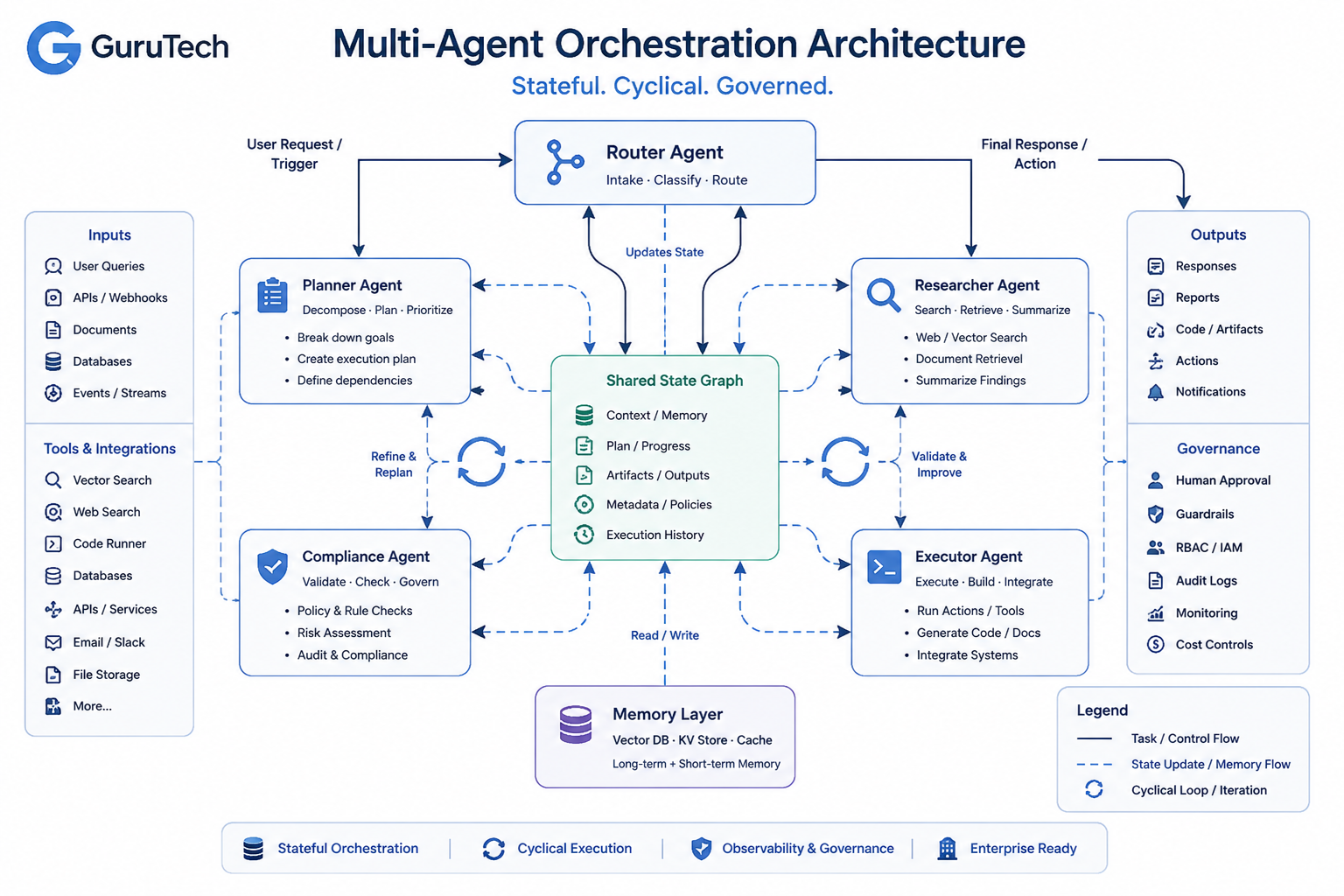
Multi-agent orchestration frameworks enable organizations to build graph-based agent networks where specialized agents collaborate through structured coordination protocols, managing complex workflows like autonomous code review, regulatory compliance automation, and document processing pipelines that require human-in-the-loop verification.
These frameworks transform isolated agentic systems into coordinated collectives where planner agents decompose tasks, executor agents perform specialized work, and critic agents validate outputs before final submission.
Performance differences between frameworks depend heavily on workflow design, model choice, state handling, tool usage, and retry behavior. In production systems, the more important question is not which framework wins a generic benchmark, but which one gives the team enough control to manage latency, cost, and failure recovery.
Understanding the architectural tradeoffs between frameworks determines whether production deployments achieve reliable orchestration or accumulate technical debt.
Organizations choosing between LangGraph and CrewAI must evaluate how each handles state persistence, retry logic, observability hooks, and governance controls.
The decision impacts development velocity, operational costs, and the ability to scale multi-agent systems beyond proof-of-concept into enterprise workflows that process thousands of requests daily.
Key Takeaways
- Graph-based multi-agent orchestration replaces linear RAG pipelines for workflows requiring iterative refinement and conditional routing
- LangGraph prioritizes flexibility and state management while CrewAI emphasizes declarative workflows and role-based coordination
- Production deployments require explicit governance patterns including retry handling, semantic caching, and human approval checkpoints
Architectural Foundations: Directed Acyclic Graphs and Loops
Early multi-agent implementations relied on simple sequential chains that proved brittle in production.
Modern frameworks address this through graph-based architectures that support both deterministic DAG execution and stateful loops with proper memory management.
The Problem with Standard LangChain
Standard LangChain chains execute tasks sequentially without branching logic or error recovery.
If any step fails, the entire pipeline collapses with no checkpoint to resume from.
This architecture lacks the orchestration layer needed for complex multi-agent workflows.
A research agent that calls a verification agent that calls a writing agent has no mechanism to retry failed steps or branch based on intermediate results.
The absence of state management means agents cannot maintain context across invocations.
Each agent call starts fresh, forcing developers to manually pass all context through function parameters.
Production teams discovered these limitations when building hierarchical orchestration patterns where coordinator agents delegate to specialists.
Without graph-based architecture, circular delegation scenarios created deadlocks that required manual intervention.
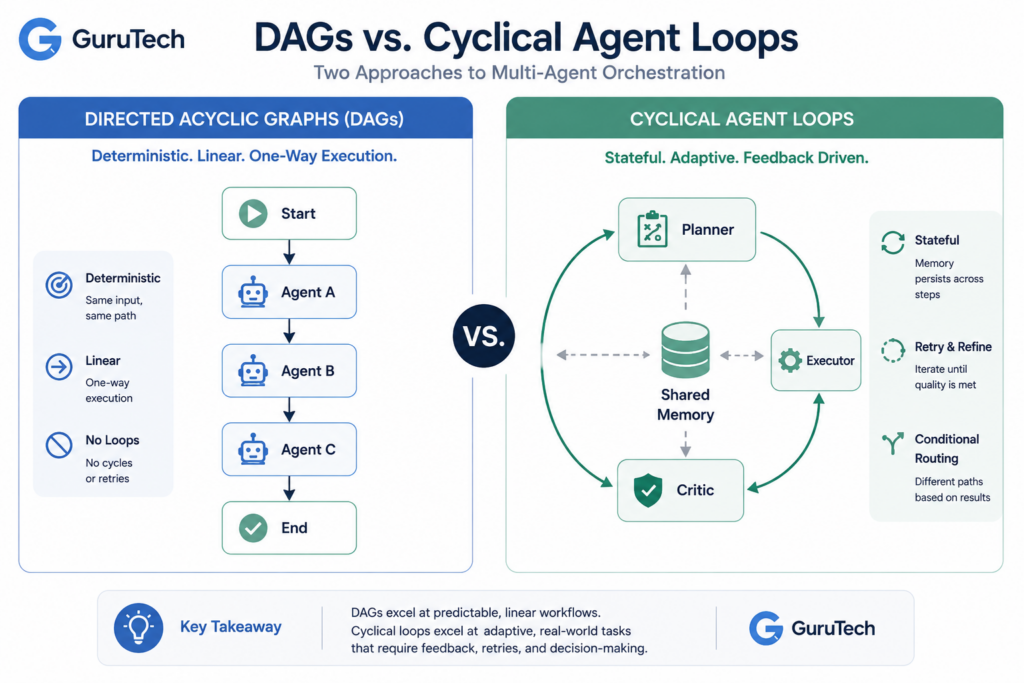
DAG-Based Workflows
Directed Acyclic Graphs model multi-agent workflows by defining nodes as agent tasks and edges as dependencies.
The scheduler executes nodes when upstream dependencies complete, automatically parallelizing independent branches.
DAG advantages for LLM orchestration:
- Deterministic execution: identical inputs produce identical execution order, enabling reproducible debugging
- Dependency management: the framework handles parallelization and serialization automatically
- Built-in observability: visualize which agent failed and inspect its upstream context
- Checkpointing: restart from the failed node rather than rerunning the entire workflow
Frameworks like Dagster treat agents as asset producers.
A research agent materializes a research_results asset, which becomes input to downstream fact_checked_claims and summary assets.
The acyclicity constraint limits iterative reasoning.
Pure DAGs cannot express “retry until quality threshold met” without recursive expansion workarounds that obscure intent.
Stateful Loops and Agent Memory
Stateful loops enable agents to iterate, reflect, and self-correct.
LangGraph introduced cyclic graphs where agents revisit previous steps based on validation results.
Memory management becomes critical in loop architectures.
Each iteration must access prior context without exceeding token limits.
Production implementations use semantic caching to store agent decisions and retrieval to inject relevant history.
# Stateful loop with memory
class AgentState(TypedDict):
messages: list[Message]
iterations: int
quality_score: float
def should_continue(state: AgentState) -> bool:
return state["quality_score"] < 0.8 and state["iterations"] < 5
The centralized orchestration layer tracks state across iterations and enforces termination conditions.
Without proper governance, loops can run indefinitely, consuming API quota.
Human approval workflows integrate naturally into stateful loops.
The graph pauses at designated checkpoints, persists state to durable storage, and resumes when approval arrives.
State Machines in Production
State machines formalize multi-agent architecture as explicit states (researching, verifying, writing) and transitions (research_complete → verify, verify_failed → research).
Each state maps to an agent or agent team.
Production state machines implement retry handling at the transition level.
If verification fails, the transition logic determines whether to retry with the same agent, escalate to a more capable model, or route to human review.
| Transition Type | Retry Strategy | Escalation Path |
|---|---|---|
| Transient failure | Exponential backoff | None |
| Quality threshold | Different prompt | Larger model |
| Schema violation | Constrained decoding | Human review |
| Timeout | Parallel execution | Fallback agent |
State persistence enables long-running workflows that span hours or days.
The framework serializes agent memory to a database, allowing the workflow to survive process restarts.
Enterprise scalability requires distributed state machines where individual states execute on separate compute resources.
The orchestration layer coordinates state transitions via message queues while maintaining exactly-once semantics.
Observable state machines expose metrics for each state: execution count, duration, failure rate, and cost.
Teams set alerts on quality score degradation or budget overruns before they impact end users.
Enterprise Production Challenges
Multi-agent orchestration systems introduce operational complexities that rarely surface during prototyping but become critical at scale.
Agent interactions create cascading failures, exponential state growth, and observability gaps that traditional monitoring cannot address.
Infinite Agent Loops
Agent loops occur when coordination logic lacks proper termination conditions or when agents continuously delegate tasks back and forth without resolution.
In production multi-agent deployments, this manifests as runaway execution costs and degraded system performance.
A planning agent might assign a task to a worker agent, which determines it needs more context and requests clarification from the planning agent.
Without cycle detection, this exchange repeats indefinitely.
The orchestration layer must implement maximum iteration limits, track delegation chains, and enforce timeout policies.
Detection requires comparing agent state transitions against a dependency graph.
When an agent invokes another agent that has already appeared in the current execution chain, the system flags a potential loop.
Implementing hard limits of 5-10 iterations per task typically prevents runaway execution while allowing legitimate multi-step reasoning.
State checkpointing enables recovery by saving agent progress at defined intervals.
When a loop is detected, the system can revert to the last valid checkpoint rather than terminating the entire workflow.
State Explosion
State explosion happens when each agent interaction generates new state entries that persist across the system.
A 10-agent workflow where each agent produces 3 state updates creates 30 state objects per execution.
At 1,000 concurrent workflows, this produces 30,000 state entries requiring storage, indexing, and retrieval.
The orchestration layer’s state management component becomes a bottleneck.
Query latency increases as agents retrieve context from expanding state stores.
Memory consumption grows until the system degrades or fails.
Mitigation requires state pruning policies that define retention windows for different state types.
Transient states used only during active execution can be discarded after task completion.
Historical states needed for audit trails are archived to cold storage.
Critical states like workflow status and decision records remain in active storage.
State Classification Strategy:
| State Type | Retention | Storage Tier |
|---|---|---|
| Execution logs | 7 days | Hot storage |
| Agent outputs | 30 days | Warm storage |
| Audit trails | 7 years | Cold archive |
| Active workflow state | Until completion | In-memory cache |
Semantic deduplication reduces redundancy by identifying functionally identical states.
Two agents generating similar risk assessments store a single canonical version with references from both agents.
Context Drift
Context drift occurs when agents operate on stale or inconsistent information as workflows progress.
An agent early in the pipeline retrieves customer data, but subsequent agents access updated versions without synchronization.
The final output reflects multiple versions of the truth.
In enterprise AI orchestration, this creates compliance violations and decision inconsistencies.
A credit approval agent might evaluate risk using different customer income figures than the compliance agent validating the same application.
Context management requires versioned context snapshots bound to workflow execution.
When a workflow initiates, the knowledge unit captures relevant context and assigns it a version identifier.
All agents in that workflow reference the same snapshot, ensuring consistency even as external data sources update.
Context versioning implementation:
workflow_id: abc-123
context_snapshot_id: v2847
retrieved_at: 2026-06-17T08:45:22Z
data_sources: [customer_db, credit_bureau, compliance_registry]
Time-to-live policies prevent agents from using severely outdated context.
If workflow execution extends beyond the defined freshness window (typically 5-15 minutes for real-time systems), the orchestration layer triggers a context refresh or workflow restart.
Retry Storms
Retry storms emerge when multiple agents simultaneously retry failed operations, overwhelming downstream services.
A temporary database timeout causes 50 concurrent agents to retry their queries within seconds. The database, already struggling, receives 50 additional requests and fails completely.
The orchestration layer’s execution unit must implement exponential backoff with jitter.
Instead of immediate retries, agents wait progressively longer intervals (2s, 4s, 8s) with randomized delays to prevent synchronized retry attempts.
Circuit breaker patterns detect cascading failures and halt retries when error rates exceed thresholds.
After 10 consecutive failures to a particular service, the circuit opens and agents receive immediate failure responses rather than attempting doomed retries.
Retry policy configuration:
- Initial retry delay: 1-2 seconds
- Maximum retry delay: 60 seconds
- Jitter range: ±30% of delay interval
- Circuit breaker threshold: 50% error rate over 30 seconds
- Circuit reset timeout: 120 seconds
Rate limiting at the orchestration level caps concurrent requests to shared resources.
If 100 agents need database access but the database handles 20 concurrent connections, the execution unit queues 80 requests and releases them as capacity becomes available.
Token Amplification
Token amplification describes the multiplicative effect of agent-to-agent communication on LLM token consumption.
A coordinator agent sends a 500-token prompt to three worker agents. Each worker generates a 1,000-token response.
The coordinator then synthesizes these responses into a 1,500-token summary, consuming 7,000 tokens total for a task that might require 2,000 tokens in a single-agent system.
Multi-agent orchestration frameworks must track token usage across agent boundaries to prevent cost overruns.
In production systems processing thousands of workflows daily, amplification factors of 3-5x create unsustainable economics.
Semantic caching reduces redundant LLM calls by storing and reusing responses to similar prompts.
When an agent submits a prompt, the orchestration layer computes a semantic embedding and checks for cached responses within a similarity threshold. Cache hits return stored responses without invoking the LLM.
Token optimization techniques:
- Implement semantic caching with 0.85+ similarity thresholds
- Compress agent-to-agent messages to essential information only
- Use structured outputs (JSON) rather than verbose natural language
- Employ smaller models for routine worker agent tasks
- Reserve frontier models for complex reasoning in coordinator agents
Token budgets per workflow prevent runaway consumption.
The orchestration layer allocates token budgets per workflow, enforces maximum iteration limits, and routes workflows to human review when agent loops exceed predefined cost or retry thresholds.
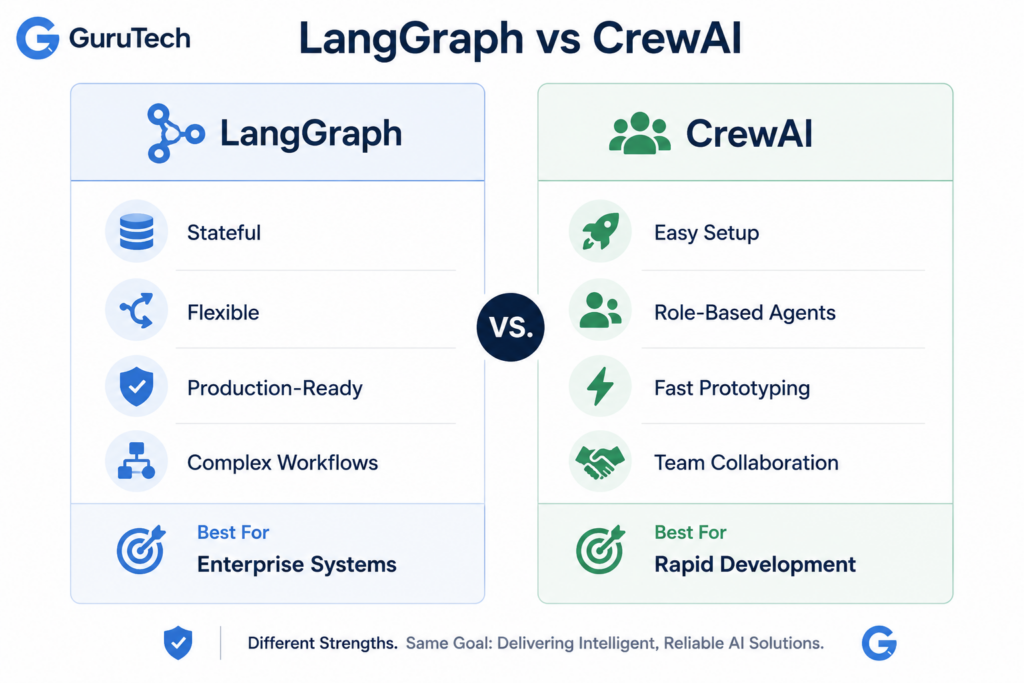
Comparing LangGraph and CrewAI
LangGraph operates as a state machine framework with explicit graph control.
CrewAI provides role-based agent abstractions that mirror human team structures.
The choice between them depends on whether your production system requires fine-grained state management or rapid deployment with intuitive agent coordination.
LangGraph (Low-Level Precision)
LangGraph models agent workflows as directed graphs where nodes represent state transformations and edges define execution paths.
Each node reads from and writes to a typed state object, enabling developers to track exactly how data flows through the system.
The framework excels at complex state machines with conditional branching.
Developers define conditional edges that route execution based on state values, implement cycles for iterative refinement, and insert human-in-the-loop interrupts at specific graph nodes.
State reducers provide fine-grained control over how concurrent operations merge their results.
Checkpointing capabilities allow systems to persist execution state at any node.
This enables resume-after-failure patterns critical for long-running workflows.
The integration with LangSmith provides production-grade observability, tracing every state mutation and LLM call through the execution graph.
State management in LangGraph supports time-travel debugging, where developers can replay execution from any checkpoint to diagnose failures.
This level of control makes LangGraph suitable for systems requiring audit trails, compliance tracking, and deterministic retry handling.
CrewAI (High-Level Abstraction)
CrewAI structures agents as team members with roles, goals, and backstories.
Developers define tasks and assign them to agents, then compose crews with either sequential or hierarchical execution processes.
The role-based collaboration model accelerates prototyping by mapping directly to how humans conceptualize teamwork.
An agent definition includes its professional role, specific goal, background context, and assigned tools.
This makes agent behavior self-documenting and accessible to non-technical stakeholders.
CrewAI handles orchestration through two primary patterns: sequential execution where agents work in order, and hierarchical delegation where a manager agent distributes subtasks.
The framework manages task outputs and shared context automatically, reducing boilerplate code.
Memory management in CrewAI operates through task output sharing and built-in memory systems.
While less granular than LangGraph’s state reducers, this approach suffices for workflows without complex branching logic or state-dependent routing requirements.
Feature Comparison Table
| Feature | LangGraph | CrewAI |
|---|---|---|
| State Management | Typed state objects with reducers, checkpointing, time-travel debugging | Task output sharing, basic shared context |
| Orchestration | Conditional edges, cycles, parallel branches, interrupt points | Sequential and hierarchical processes |
| Learning Curve | Steep – requires graph theory understanding | Gentle – role/goal/backstory maps to team thinking |
| Production Readiness | LangSmith integration, built-in persistence, replay capabilities | Improving – custom work needed for complex retry logic |
| Human-in-the-Loop | Native interrupt-resume with state persistence | Manual implementation through task callbacks |
| Observability | Full trace of state mutations and node executions | Task-level logging, less granular tracing |
| Best For | State-dependent routing, revision loops, compliance systems | Role-based collaboration, rapid prototyping, content pipelines |
When to Choose LangGraph
LangGraph fits production systems requiring conditional branching and cyclic workflows.
Code generation pipelines that test output and regenerate on failure need explicit cycle support.
Document review systems routing between editors until consensus requires state-dependent conditional edges.
Systems with human approval gates benefit from LangGraph’s interrupt-resume model.
Execution pauses at defined points, persists state to a database, and resumes exactly where it stopped when human input arrives.
This pattern proves essential for high-stakes autonomous systems requiring governance checkpoints.
Enterprise deployments needing audit trails and compliance tracking leverage LangGraph’s checkpointing.
Every state transition becomes a recoverable checkpoint, enabling replay for debugging and creating immutable execution histories for regulatory requirements.
Semantic caching strategies integrate cleanly with LangGraph’s state management.
Developers cache results at specific nodes based on state fingerprints, implementing cache invalidation logic through state reducers.
When to Choose CrewAI
CrewAI excels when agents map to distinct professional roles with clear goals.
Content generation systems with researcher, writer, and editor agents follow CrewAI’s sequential process naturally.
Market analysis platforms with specialist agents for competitive analysis, trend forecasting, and reporting benefit from hierarchical delegation.
Rapid prototyping scenarios favor CrewAI’s abstraction layer.
Teams can move from concept to working demo in hours rather than days, validating agent decomposition before committing to complex orchestration logic.
Systems without revision loops or complex state routing avoid LangGraph’s overhead.
If the workflow executes linearly or delegates hierarchically without conditional branching, CrewAI provides sufficient orchestration with less code.
Non-technical stakeholder involvement benefits from CrewAI’s self-documenting agent definitions.
Product managers can review role descriptions and goals to validate alignment with business requirements without understanding graph topology or state reducers.
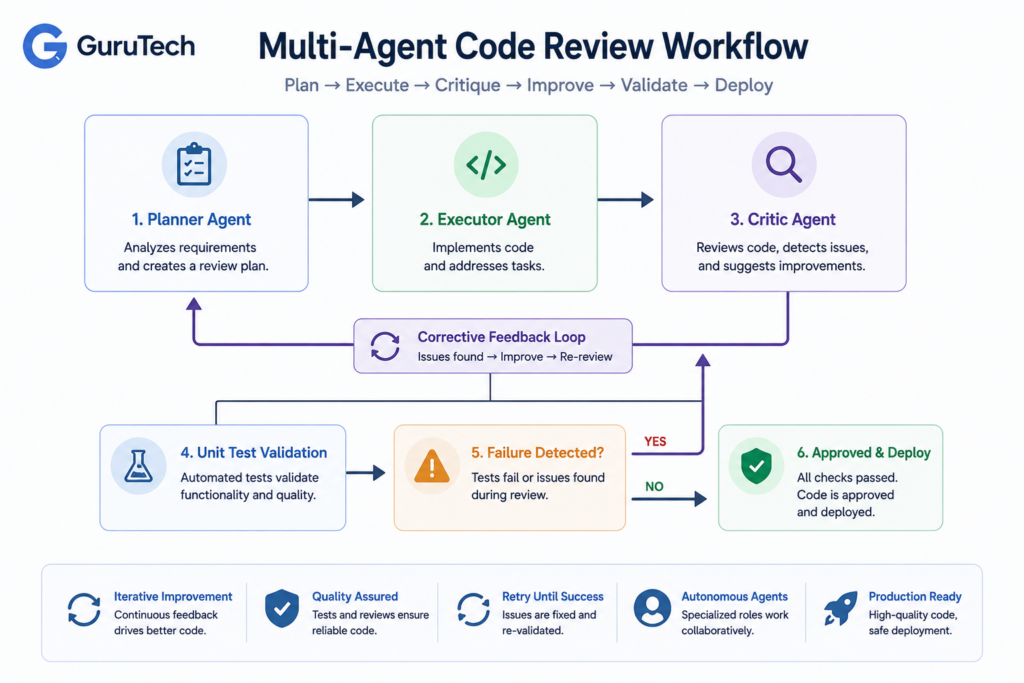
Designing a Resilient Code-Review Agent Cluster
A code-review agent cluster distributes review responsibilities across specialized roles that validate different aspects of code quality.
The planner decomposes pull requests into reviewable units, the executor performs targeted analysis on each unit, and the critic validates outputs before they reach developers.
Planner Agent
The planner agent receives incoming pull requests and breaks them into atomic review tasks based on file types, change scope, and dependency relationships.
It analyzes the diff structure to identify which files changed together and should be reviewed as cohesive units rather than in isolation.
This agent maintains a task queue with priority scores derived from factors like cyclomatic complexity increases, security-sensitive file patterns, and historical bug density in modified modules.
It assigns each task to executor instances based on their specialization profiles.
The planner implements semantic caching by hashing file contents and review parameters.
When developers push incremental commits, it skips re-planning unchanged portions and only generates tasks for new modifications.
This reduces token consumption by 60-70% on typical iterative development workflows.
State management happens through a persistent task registry that tracks which review units have been processed, which are in-flight, and which failed validation.
The registry enables crash recovery without losing progress on partially completed reviews.
Executor Agent
The executor agent performs the actual code analysis on assigned review units.
Different executor instances specialize in distinct review dimensions: security vulnerability scanning, performance regression detection, style consistency checking, and logic correctness verification.
Each executor runs in an isolated session with no shared conversation state.
It receives the specific file chunk, relevant context from the planner’s dependency analysis, and a structured schema for its output format.
The executor uses explicit context control rather than accumulated conversation history to prevent token bloat.
Retry handling includes exponential backoff with jitter for transient API failures.
Executors implement circuit breakers that trip after three consecutive failures and route subsequent tasks to backup model providers.
For example, an executor might fall back from GPT-5.2 to Claude Opus 4.7 when primary capacity is exhausted.
Observability instrumentation captures per-executor metrics including token usage, latency percentiles, cache hit rates, and error classifications.
These metrics feed into adaptive routing logic that shifts load away from struggling instances.
Critic Agent
The critic agent validates executor outputs against quality standards before surfacing them to developers.
It checks that review comments reference actual line numbers in the diff, that severity ratings align with the flagged issue types, and that suggested fixes compile and pass basic syntax validation.
This validation layer prevents hallucinated feedback from reaching pull request threads.
The critic runs executors’ proposed code fixes through a sandboxed compilation step and rejects any that introduce syntax errors or break existing tests.
The critic also enforces governance policies defined in the review cluster’s configuration.
It filters out comments below a confidence threshold, removes duplicate findings across different executors, and consolidates overlapping suggestions into unified recommendations.
Human approval workflows trigger when the critic encounters ambiguous cases where multiple executors conflict or when flagged issues exceed a severity threshold.
The approval gate pauses workflow execution and presents a Rich terminal interface or web dashboard where engineers can inspect the full review context and decide whether to accept or reject the findings.
Corrective Feedback Loops
Corrective feedback loops route rejected review comments back to executors with annotated explanations of why the critic or human reviewer dismissed them. This creates a learning signal that reduces false positive rates over successive iterations.
The loop maintains agent memory through a FAISS-based vector store that indexes past review decisions. When an executor generates a new comment, the system retrieves similar historical cases and their outcomes.
Executors condition their analysis on this retrieved context to avoid repeating previously rejected patterns. Loop termination requires explicit exit conditions to prevent infinite revision cycles.
The planner enforces a maximum iteration count of five passes through the executor-critic cycle. After five rejections, the system escalates to human review rather than continuing automated refinement.
State snapshots capture the full review context at each iteration boundary. If an executor crashes mid-loop, it resumes from the last snapshot rather than restarting from scratch.
This resilience pattern becomes critical for large pull requests that take 10-15 minutes to process completely.
Code Implementation: Defining State and Edges
LangGraph’s StateGraph provides typed state schemas that define data flow between nodes in a multi-agent system.
The state object acts as shared memory that persists across agent boundaries and enables coordination without direct agent-to-agent communication.
A production state schema typically includes task metadata, execution status, and routing logic:
from typing import TypedDict, Literal
class OrchestratorState(TypedDict):
task_id: str
full_plan: list[dict]
current_step: int
agent_outputs: dict[str, str]
verification_status: Literal["pending", "passed", "failed"]
next: str
retry_count: int
The next field drives conditional routing between agents, while retry_count supports failure recovery.
Graph edges define how control flows between specialized agents.
Conditional edges inspect state to determine the next node:
def route_after_verification(state: OrchestratorState) -> str:
if state["verification_status"] == "passed":
return "finalizer"
elif state["retry_count"] < 3:
return "executor"
return "escalation_handler"
graph.add_conditional_edges("verifier", route_after_verification)
Static edges enforce sequential execution without branching logic.
Production systems combine both patterns to balance flexibility with predictability.
State type validation prevents runtime errors from schema drift.
Each node receives the complete state object but should only modify fields within its responsibility scope to maintain clear ownership boundaries.
Cost, Performance, and Governance Considerations
Production multi-agent systems require careful attention to token efficiency and operational costs.
Coordination among numerous agents can create communication overhead that drives up token usage exponentially as workflows scale.
Each agent interaction consumes tokens for context passing, state synchronization, and inter-agent messages. Implementing semantic caching reduces redundant LLM calls by storing and reusing responses for similar queries.
State management strategies like checkpointing prevent full workflow reruns when individual agents fail. Retry handling with exponential backoff helps manage transient failures without multiplying costs through immediate retries.
Enterprise Governance Requirements
Organizations deploying multi-agent orchestration frameworks need robust security and compliance controls.
RBAC systems define which users can trigger specific agent workflows or access sensitive outputs. SSO integration connects agent platforms to existing identity providers for centralized authentication.
Audit logging captures every agent action, decision point, and data access for compliance reviews. Guardrails enforce policy boundaries by blocking agents from executing prohibited actions or accessing restricted resources.
Human approval workflows insert manual checkpoints before high-risk agent actions execute.
Performance and Integration Patterns
AI ecosystems benefit from tool integrations that extend agent capabilities without custom development.
Observability through distributed tracing reveals bottlenecks across agent handoffs. Agent memory systems maintain conversation context and learned preferences across sessions.
Production architectures balance token efficiency against response latency. Parallel agent execution reduces wall-clock time but increases concurrent token consumption.
Sequential patterns optimize costs but extend user wait times.
Summary: Selecting the Right Framework for Production
LangGraph is frequently selected for production-oriented deployments because its graph-based model, checkpointing support, and LangSmith integration map well to enterprise observability and state-management requirements.
The graph-based state machine model maps cleanly to production multi-agent flows where state management and error recovery are critical.
CrewAI offers superior demo-to-prototype ergonomics with its role-based crew abstraction but trails in production observability and retry handling.
Teams prioritizing rapid proof-of-concept development over enterprise scalability find CrewAI’s intuitive API valuable for initial validation.
Microsoft AutoGen leads in academic and research environments with mature multi-agent debate and verification patterns.
Its conversational-agent abstraction supports complex multi-turn interactions, though production deployment patterns remain less standardized than LangGraph’s supervisor architecture.
OpenAI Swarm remains explicitly experimental and unsuitable for production despite its minimal handoff pattern.
The framework lacks robust state management, governance controls, and production-grade observability required for enterprise deployments.
Custom orchestration still remains common in mature engineering teams, especially when framework abstractions conflict with internal requirements around state management, human approval workflows, or semantic caching strategies.
Senior engineering teams choose custom implementations when framework abstractions conflict with specific production requirements around agent memory persistence or complex retry logic.
Framework selection matters less than underlying model quality, evaluation infrastructure, and human-checkpoint design.
A frontier model with basic orchestration outperforms sophisticated frameworks running weaker models.
Production teams should instrument per-agent performance metrics, implement regression testing with trace replay, and define clear human approval gates before framework selection.
Frequently Asked Questions
Production multi-agent systems require explicit architectural decisions around component separation, tool selection, communication contracts, observability infrastructure, control flow mechanisms, and enterprise integration patterns that directly impact reliability and maintainability at scale.
What are the core architectural components and responsibilities in a production-grade agent orchestration layer?
A production orchestration layer separates into four distinct components: the router, the executor, the state manager, and the observability layer.
The router analyzes incoming requests and determines which agents should handle specific tasks based on capability matching and current system load.
The executor manages the actual invocation of agents, including timeout enforcement, retry logic, and failure isolation.
It wraps each agent call with circuit breakers to prevent cascading failures when downstream agents become unresponsive.
The state manager maintains conversation context, agent memory, and execution checkpoints across the entire workflow.
This component handles semantic caching to avoid redundant LLM calls and stores intermediate results for recovery after partial failures.
The observability layer captures traces, metrics, and logs for every agent interaction.
It records token usage, latency percentiles, error rates, and business-specific metrics like task completion rates or human approval frequencies.
Human-in-the-loop checkpoints belong in the executor component as special breakpoints that pause execution until approval is received.
These checkpoints should include full context serialization so that workflows can resume days later without re-executing previous steps.
Agent memory lives in the state manager and requires careful design decisions around scope and lifetime.
Per-agent memory stores tool-specific context, while shared memory enables cross-agent collaboration on complex tasks requiring multiple specializations.
Which open-source tools are most commonly used to coordinate multiple LLM agents, and how do they compare by routing, memory, and tool-calling support?
LangGraph provides graph-based orchestration with explicit state machines and conditional edges for deterministic control flow.
It excels at complex routing patterns where agents need to make decisions about which path to follow based on intermediate results.
CrewAI focuses on role-based agent collaboration with hierarchical or sequential execution patterns.
Agents in CrewAI operate as crew members with defined roles, making it intuitive for workflows that mirror human team structures.
AutoGen emphasizes conversational patterns between agents with built-in support for human proxy agents.
It handles multi-turn dialogues naturally and provides strong primitives for agent-to-agent communication through message passing.
| Framework | Routing Model | Memory Architecture | Tool Calling | State Persistence |
|---|---|---|---|---|
| LangGraph | Graph-based with conditional edges | Channel-based shared state | Function calling with retries | Checkpointer API with Redis/Postgres |
| CrewAI | Sequential or hierarchical | Agent-specific context | Tool decorator pattern | In-memory with custom backends |
| AutoGen | Conversational with speaker selection | Conversation history buffer | Function registration | Session-based with SQLite option |
| Microsoft Copilot Studio | Orchestrator-driven delegation | Conversation transcript sharing | Built-in connectors | Cloud-native state service |
LangGraph integrates native checkpointing for long-running workflows, storing execution state at each graph node.
This enables replay from any point and supports sophisticated retry strategies after transient failures.
CrewAI’s memory model includes short-term memory for task execution, long-term memory for facts across sessions, and entity memory for relationship tracking.
However, developers must implement custom persistence layers for production durability.
Tool-calling support varies significantly across frameworks.
LangGraph wraps tools as graph nodes with automatic retry and timeout handling, while CrewAI uses decorator-based tool registration that requires manual error handling in production.
How do you design and implement agent-to-agent communication patterns (broadcast, mediator, blackboard, swarm) with clear handoff contracts?
The mediator pattern uses a central coordinator agent that routes requests to specialized workers and aggregates their responses.
The coordinator maintains the conversation context and enforces the single response principle where only one agent communicates with the end user.
Broadcast patterns send the same request to multiple agents simultaneously, useful for ensemble approaches or redundancy.
Each agent processes independently and returns results to the orchestrator, which then merges or selects the best response based on confidence scores.
Blackboard architectures maintain shared state that all agents can read and write to asynchronously.
Agents observe the blackboard for tasks matching their capabilities, claim work items through atomic operations, and publish results back for other agents to consume.
Swarm patterns allow agents to dynamically spawn sub-agents as needed, creating emergent behavior through local interactions.
This approach requires careful governance to prevent runaway agent creation and resource exhaustion.
Handoff contracts define the exact data structure, validation rules, and error handling expectations when one agent delegates to another.
These contracts should include the task description, required context, expected output format, timeout values, and fallback behaviors.
The Agent-to-Agent (A2A) protocol standardizes handoffs between heterogeneous agent systems.
A2A defines message schemas, authentication mechanisms, and capability negotiation to enable interoperability across different orchestration frameworks.
Implementing clear handoff contracts requires explicit instructions in agent prompts.
Parent agents must specify that child agents should return findings only without responding directly to users, while child agents need explicit instructions declaring their role as subagents.
The Model Context Protocol (MCP) provides another interoperability layer for connecting agents to external tools and data sources.
MCP standardizes how agents discover, authenticate with, and invoke remote capabilities across organizational boundaries.
What are the recommended evaluation and observability practices for multi-agent runs (tracing, metrics, replay, and regression testing) before deployment?
Distributed tracing captures the complete execution path across all agents involved in fulfilling a request.
Each agent interaction becomes a span within a trace, recording start time, duration, input parameters, output values, and any errors encountered.
OpenTelemetry provides the standard instrumentation libraries for multi-agent systems.
Traces should include custom attributes like agent_id, task_type, and token_count.
They should also capture workflow_id, parent_agent_id, model_name, cache_status, tool_name, retry_count, and human_approval_status. These attributes make it possible to reconstruct how each workflow moved through the agent graph and identify which agent, tool, or edge created latency, cost, or quality issues.
Replay is especially important for multi-agent systems because failures often emerge from interaction patterns rather than a single bad model response. Teams should store representative traces, rerun them after prompt changes or model upgrades, and compare output quality, latency, token cost, and routing behavior against previous baselines.
Regression testing should include both successful workflows and known failure cases such as malformed tool outputs, low-confidence critic feedback, retry exhaustion, missing context, and human rejection events. This prevents teams from optimizing for happy-path demos while leaving production edge cases untested.
How should teams prevent runaway cost in autonomous agent loops?
Teams should enforce token budgets, maximum iteration counts, retry limits, timeout policies, and escalation rules at the orchestration layer rather than relying on individual agent prompts. Each workflow should have a defined cost ceiling and a clear fallback path when the system cannot complete the task safely within that budget.
Semantic caching, prompt compression, structured outputs, and model routing can significantly reduce repeated token usage. Expensive reasoning models should be reserved for planning, critique, or escalation steps, while cheaper models can often handle extraction, formatting, classification, and routine worker-agent tasks.
When should an enterprise choose LangGraph instead of CrewAI?
LangGraph is the stronger choice when the workflow requires explicit state management, conditional routing, durable execution, human approval checkpoints, auditability, and complex retry behavior. It is better suited for mission-critical systems where developers need to control exactly how state moves through the graph.
CrewAI is often better for rapid prototyping, role-based content workflows, research teams, and simpler collaborative patterns where agents behave like members of a structured team. It can still be used in production, but highly regulated or deeply stateful systems usually require additional governance and persistence layers.
How do multi-agent systems connect with semantic caching?
Multi-agent systems generate many repetitive prompts because planner, executor, verifier, and critic agents often revisit similar subtasks across workflows. A semantic caching layer can intercept repeated or near-duplicate requests, compare them through vector similarity, and return a validated cached result when the query is close enough to a previous one.
This is especially useful in code review, compliance analysis, support automation, and document-processing workflows where agents repeatedly ask similar questions about policies, schemas, requirements, or validation rules. The orchestration layer should record cache hits, misses, similarity thresholds, and downstream quality impact so caching improves economics without hiding errors.
What is the safest way to add human approval to a multi-agent workflow?
The safest pattern is to define approval checkpoints as explicit graph nodes or state transitions. When the workflow reaches a high-risk action, the system pauses, persists the current state, summarizes the decision context, and waits for a human reviewer to approve, reject, or modify the next step.
Human approval should be required before external side effects such as database writes, customer communication, financial actions, production code changes, or compliance-sensitive decisions. The approval event should be logged with the workflow state, reviewer identity, timestamp, and final action for auditability.
Conclusion
Multi-agent orchestration frameworks are becoming a core layer in enterprise AI architecture because they allow teams to move beyond linear prompt chains and build systems that plan, execute, validate, retry, and escalate work across specialized agents. The architectural challenge is not simply connecting agents together. It is managing state, memory, routing, cost, observability, and governance across many model calls and tool interactions.
LangGraph is best aligned with complex production systems that require explicit state control, conditional edges, human approval checkpoints, durable execution, and traceable recovery paths. CrewAI is attractive when teams need faster prototyping, role-based collaboration, and simpler agent team definitions. The best choice depends on workflow complexity, engineering maturity, compliance requirements, and how much control the organization needs over state transitions.
For enterprise teams, the framework decision should be paired with a broader operating model: token observability, semantic caching, evaluation pipelines, audit logging, and human-in-the-loop governance. Without those supporting layers, even a well-designed multi-agent graph can become expensive, unpredictable, and difficult to debug. With them, multi-agent orchestration can become a practical foundation for scalable AI automation.